 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Concept to Capability: Evaluating 3D Gaussian Splatting for Synthetic Scene Editing in Autonomous Driving
May 03, 2026The perception of an Autonomous Driving System (ADS) critically depends on relevant, comprehensive, and diverse datasets to ensure its safety while operating in the environment. Field data collection lacks completeness with respect to the list of rare but still possible safety-related scenarios needed for the development, verification, and validation of the ADS. 3D Gaussian Splatting (3DGS) has shown promising capabilities for the reconstruction and editing of scenes based on data collected by cameras and LiDAR sensors. However, the industrial fidelity evaluation of reconstructions is underexplored, which is crucial when employing such methods in safety-related systems, especially for ADS. This becomes more challenging as ADS operates in a dynamic, uncontrolled environment with limited viewpoints and often partially occluded objects. This paper addresses this gap by proposing and implementing a framework (Fig. 1) to systematically analyze the capabilities and limitations of 3DGS for use in the reconstruction of safety-related scenes. It focuses on the quality of reconstruction for vehicles and pedestrians, which are the two most critical object classes for ADS. Our findings provide industry insights into the fidelity degradation of reconstructions from multiple novel viewpoints, both lateral and longitudinal, enabling the integration of these methods into real-world industrial AD software development and testing pipelines.
Large Language Models in Code Co-generation for Safe Autonomous Vehicles
May 26, 2025Software engineers in various industrial domains are already using Large Language Models (LLMs) to accelerate the process of implementing parts of software systems. When considering its potential use for ADAS or AD systems in the automotive context, there is a need to systematically assess this new setup: LLMs entail a well-documented set of risks for safety-related systems' development due to their stochastic nature. To reduce the effort for code reviewers to evaluate LLM-generated code, we propose an evaluation pipeline to conduct sanity-checks on the generated code. We compare the performance of six state-of-the-art LLMs (CodeLlama, CodeGemma, DeepSeek-r1, DeepSeek-Coders, Mistral, and GPT-4) on four safety-related programming tasks. Additionally, we qualitatively analyse the most frequent faults generated by these LLMs, creating a failure-mode catalogue to support human reviewers. Finally, the limitations and capabilities of LLMs in code generation, and the use of the proposed pipeline in the existing process, are discussed.
On Simulation-Guided LLM-based Code Generation for Safe Autonomous Driving Software
Apr 02, 2025


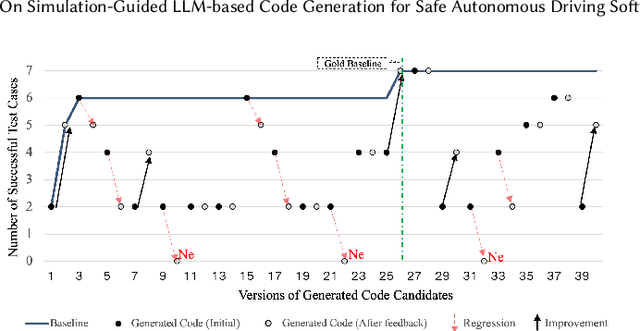
Automated Driving System (ADS) is a safety-critical software system responsible for the interpretation of the vehicle's environment and making decisions accordingly. The unbounded complexity of the driving context, including unforeseeable events, necessitate continuous improvement, often achieved through iterative DevOps processes. However, DevOps processes are themselves complex, making these improvements both time- and resource-intensive. Automation in code generation for ADS using Large Language Models (LLM) is one potential approach to address this challenge. Nevertheless, the development of ADS requires rigorous processes to verify, validate, assess, and qualify the code before it can be deployed in the vehicle and used. In this study, we developed and evaluated a prototype for automatic code generation and assessment using a designed pipeline of a LLM-based agent, simulation model, and rule-based feedback generator in an industrial setup. The LLM-generated code is evaluated automatically in a simulation model against multiple critical traffic scenarios, and an assessment report is provided as feedback to the LLM for modification or bug fixing. We report about the experimental results of the prototype employing Codellama:34b, DeepSeek (r1:32b and Coder:33b), CodeGemma:7b, Mistral:7b, and GPT4 for Adaptive Cruise Control (ACC) and Unsupervised Collision Avoidance by Evasive Manoeuvre (CAEM). We finally assessed the tool with 11 experts at two Original Equipment Manufacturers (OEMs) by conducting an interview study.
Engineering Safety Requirements for Autonomous Driving with Large Language Models
Mar 24, 2024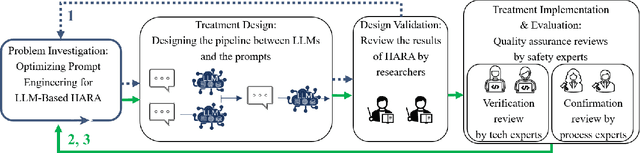

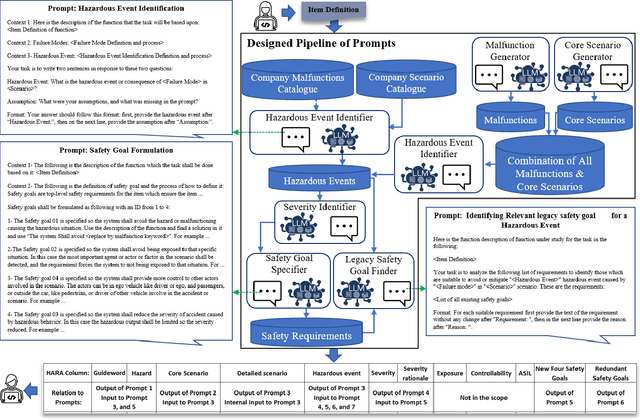

Changes and updates in the requirement artifacts, which can be frequent in the automotive domain, are a challenge for SafetyOps. Large Language Models (LLMs), with their impressive natural language understanding and generating capabilities, can play a key role in automatically refining and decomposing requirements after each update. In this study, we propose a prototype of a pipeline of prompts and LLMs that receives an item definition and outputs solutions in the form of safety requirements. This pipeline also performs a review of the requirement dataset and identifies redundant or contradictory requirements. We first identified the necessary characteristics for performing HARA and then defined tests to assess an LLM's capability in meeting these criteria. We used design science with multiple iterations and let experts from different companies evaluate each cycle quantitatively and qualitatively. Finally, the prototype was implemented at a case company and the responsible team evaluated its efficiency.
On STPA for Distributed Development of Safe Autonomous Driving: An Interview Study
Mar 14, 2024Safety analysis is used to identify hazards and build knowledge during the design phase of safety-relevant functions. This is especially true for complex AI-enabled and software intensive systems such as Autonomous Drive (AD). System-Theoretic Process Analysis (STPA) is a novel method applied in safety-related fields like defense and aerospace, which is also becoming popular in the automotive industry. However, STPA assumes prerequisites that are not fully valid in the automotive system engineering with distributed system development and multi-abstraction design levels. This would inhibit software developers from using STPA to analyze their software as part of a bigger system, resulting in a lack of traceability. This can be seen as a maintainability challenge in continuous development and deployment (DevOps). In this paper, STPA's different guidelines for the automotive industry, e.g. J31887/ISO21448/STPA handbook, are firstly compared to assess their applicability to the distributed development of complex AI-enabled systems like AD. Further, an approach to overcome the challenges of using STPA in a multi-level design context is proposed. By conducting an interview study with automotive industry experts for the development of AD, the challenges are validated and the effectiveness of the proposed approach is evaluated.
* Accepted at SEAA. 8 pages, 2 figures
Welcome Your New AI Teammate: On Safety Analysis by Leashing Large Language Models
Mar 14, 2024DevOps is a necessity in many industries, including the development of Autonomous Vehicles. In those settings, there are iterative activities that reduce the speed of SafetyOps cycles. One of these activities is "Hazard Analysis & Risk Assessment" (HARA), which is an essential step to start the safety requirements specification. As a potential approach to increase the speed of this step in SafetyOps, we have delved into the capabilities of Large Language Models (LLMs). Our objective is to systematically assess their potential for application in the field of safety engineering. To that end, we propose a framework to support a higher degree of automation of HARA with LLMs. Despite our endeavors to automate as much of the process as possible, expert review remains crucial to ensure the validity and correctness of the analysis results, with necessary modifications made accordingly.
Training CNNs faster with Dynamic Input and Kernel Downsampling
Oct 15, 2019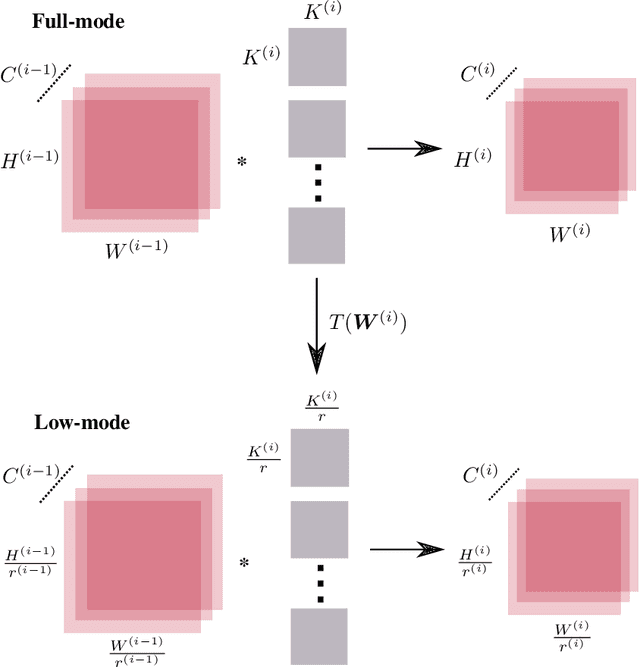



We reduce training time in convolutional networks (CNNs) with a method that, for some of the mini-batches: a) scales down the resolution of input images via downsampling, and b) reduces the forward pass operations via pooling on the convolution filters. Training is performed in an interleaved fashion; some batches undergo the regular forward and backpropagation passes with original network parameters, whereas others undergo a forward pass with pooled filters and downsampled inputs. Since pooling is differentiable, the gradients of the pooled filters propagate to the original network parameters for a standard parameter update. The latter phase requires fewer floating point operations and less storage due to the reduced spatial dimensions in feature maps and filters. The key idea is that this phase leads to smaller and approximate updates and thus slower learning, but at significantly reduced cost, followed by passes that use the original network parameters as a refinement stage. Deciding how often and for which batches the downsmapling occurs can be done either stochastically or deterministically, and can be defined as a training hyperparameter itself. Experiments on residual architectures show that we can achieve up to 23% reduction in training time with minimal loss in validation accuracy.
A Bayesian Sampling Approach to Exploration in Reinforcement Learning
May 09, 2012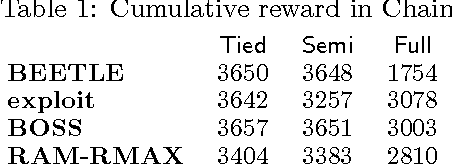
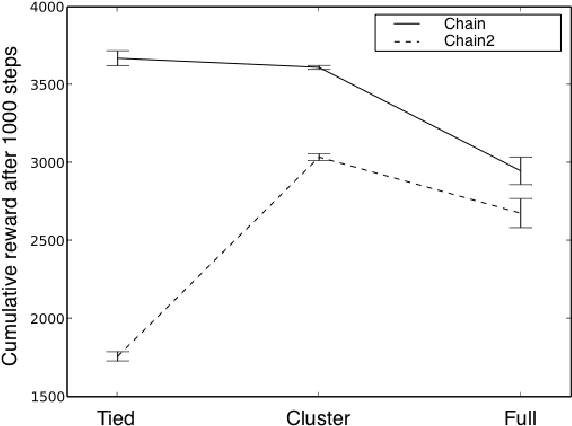
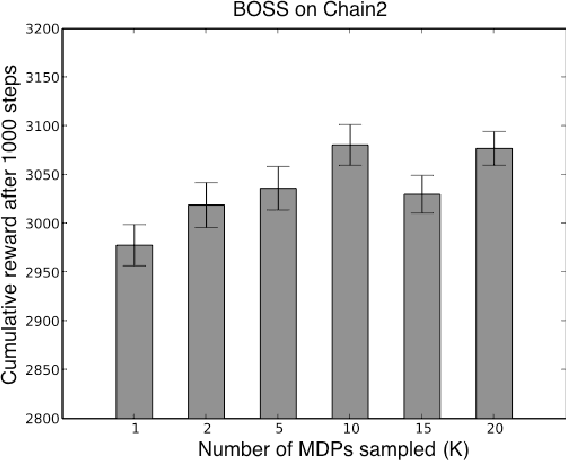

We present a modular approach to reinforcement learning that uses a Bayesian representation of the uncertainty over models. The approach, BOSS (Best of Sampled Set), drives exploration by sampling multiple models from the posterior and selecting actions optimistically. It extends previous work by providing a rule for deciding when to resample and how to combine the models. We show that our algorithm achieves nearoptimal reward with high probability with a sample complexity that is low relative to the speed at which the posterior distribution converges during learning. We demonstrate that BOSS performs quite favorably compared to state-of-the-art reinforcement-learning approaches and illustrate its flexibility by pairing it with a non-parametric model that generalizes across states.