 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining CNNs faster with Dynamic Input and Kernel Downsampling
Paper and Code
Oct 15, 2019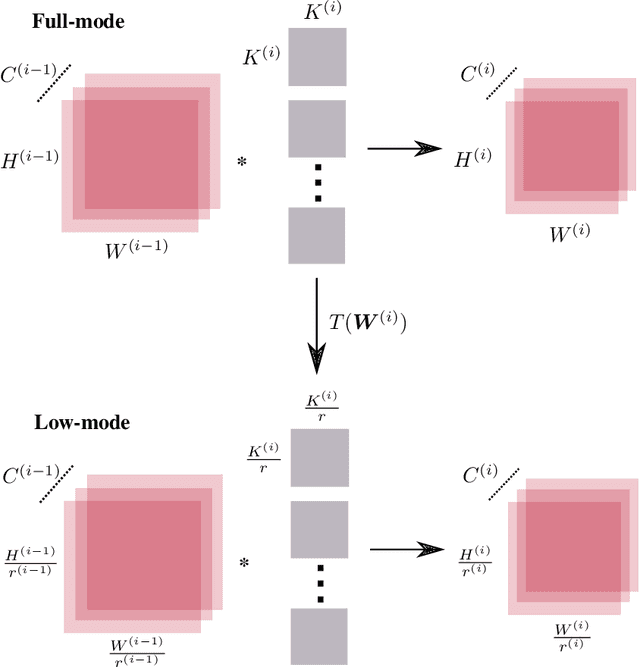



We reduce training time in convolutional networks (CNNs) with a method that, for some of the mini-batches: a) scales down the resolution of input images via downsampling, and b) reduces the forward pass operations via pooling on the convolution filters. Training is performed in an interleaved fashion; some batches undergo the regular forward and backpropagation passes with original network parameters, whereas others undergo a forward pass with pooled filters and downsampled inputs. Since pooling is differentiable, the gradients of the pooled filters propagate to the original network parameters for a standard parameter update. The latter phase requires fewer floating point operations and less storage due to the reduced spatial dimensions in feature maps and filters. The key idea is that this phase leads to smaller and approximate updates and thus slower learning, but at significantly reduced cost, followed by passes that use the original network parameters as a refinement stage. Deciding how often and for which batches the downsmapling occurs can be done either stochastically or deterministically, and can be defined as a training hyperparameter itself. Experiments on residual architectures show that we can achieve up to 23% reduction in training time with minimal loss in validation accuracy.