 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large Scale Video Classification
Paper and Code
May 22, 2015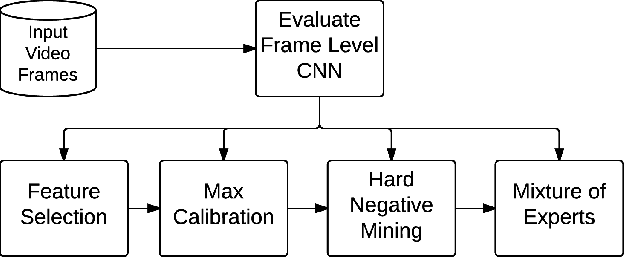



Video classification has advanced tremendously over the recent years. A large part of the improvements in video classification had to do with the work done by the image classification community and the use of deep convolutional networks (CNNs) which produce competitive results with hand- crafted motion features. These networks were adapted to use video frames in various ways and have yielded state of the art classification results. We present two methods that build on this work, and scale it up to work with millions of videos and hundreds of thousands of classes while maintaining a low computational cost. In the context of large scale video processing, training CNNs on video frames is extremely time consuming, due to the large number of frames involved. We propose to avoid this problem by training CNNs on either YouTube thumbnails or Flickr images, and then using these networks' outputs as features for other higher level classifiers. We discuss the challenges of achieving this and propose two models for frame-level and video-level classification. The first is a highly efficient mixture of experts while the latter is based on long short term memory neural networks. We present results on the Sports-1M video dataset (1 million videos, 487 classes) and on a new dataset which has 12 million videos and 150,000 labels.