 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Hausdorff Distance: A Loss Function For Object Localization
Paper and Code

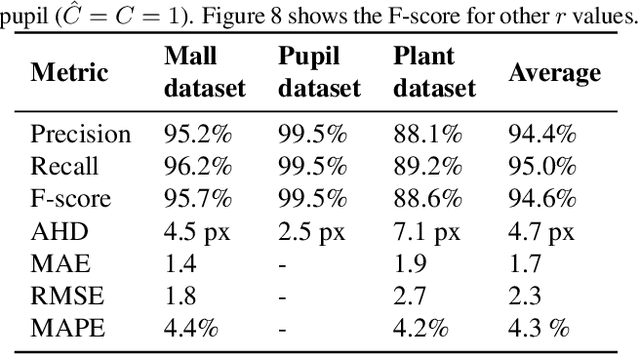

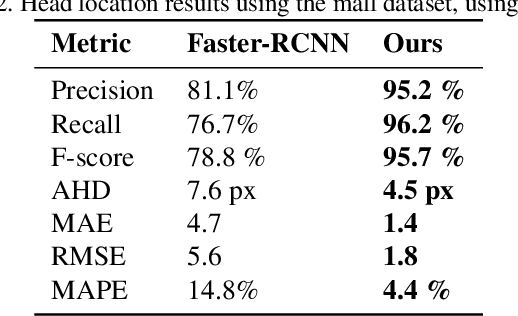
Recent advances in Convolutional Neural Networks (CNN) have achieved remarkable results in localizing objects in images. In these networks, the training procedure usually requires providing bounding boxes or the maximum number of expected objects. In this paper, we address the task of estimating object locations without annotated bounding boxes, which are typically hand-drawn and time consuming to label. We propose a loss function that can be used in any Fully Convolutional Network (FCN) to estimate object locations. This loss function is a modification of the Average Hausdorff Distance between two unordered sets of points. The proposed method does not require one to "guess" the maximum number of objects in the image, and has no notion of bounding boxes, region proposals, or sliding windows. We evaluate our method with three datasets designed to locate people's heads, pupil centers and plant centers. We report an average precision and recall of 94% for the three datasets, and an average location error of 6 pixels in 256x256 images.