 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldAgents: Can Foundation Image Models be Agents for 3D World Models?
Mar 20, 2026Given the remarkable ability of 2D foundation image models to generate high-fidelity outputs, we investigate a fundamental question: do 2D foundation image models inherently possess 3D world model capabilities? To answer this, we systematically evaluate multiple state-of-the-art image generation models and Vision-Language Models (VLMs) on the task of 3D world synthesis. To harness and benchmark their potential implicit 3D capability, we propose an agentic framing to facilitate 3D world generation. Our approach employs a multi-agent architecture: a VLM-based director that formulates prompts to guide image synthesis, a generator that synthesizes new image views, and a VLM-backed two-step verifier that evaluates and selectively curates generated frames from both 2D image and 3D reconstruction space. Crucially, we demonstrate that our agentic approach provides coherent and robust 3D reconstruction, producing output scenes that can be explored by rendering novel views. Through extensive experiments across various foundation models, we demonstrate that 2D models do indeed encapsulate a grasp of 3D worlds. By exploiting this understanding, our method successfully synthesizes expansive, realistic, and 3D-consistent worlds.
PrEditor3D: Fast and Precise 3D Shape Editing
Dec 09, 2024We propose a training-free approach to 3D editing that enables the editing of a single shape within a few minutes. The edited 3D mesh aligns well with the prompts, and remains identical for regions that are not intended to be altered. To this end, we first project the 3D object onto 4-view images and perform synchronized multi-view image editing along with user-guided text prompts and user-provided rough masks. However, the targeted regions to be edited are ambiguous due to projection from 3D to 2D. To ensure precise editing only in intended regions, we develop a 3D segmentation pipeline that detects edited areas in 3D space, followed by a merging algorithm to seamlessly integrate edited 3D regions with the original input. Extensive experiments demonstrate the superiority of our method over previous approaches, enabling fast, high-quality editing while preserving unintended regions.
HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion
Mar 29, 2023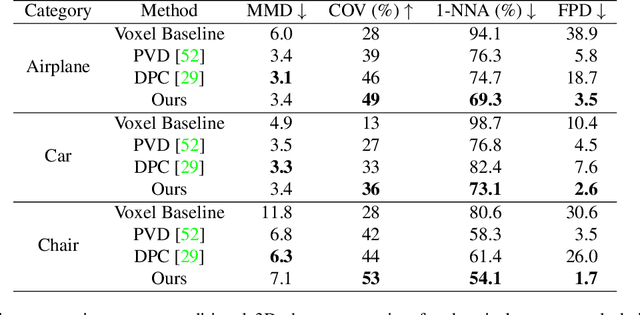

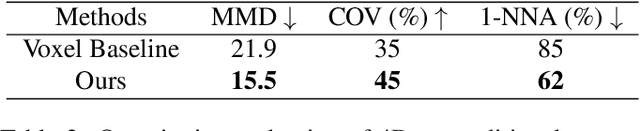
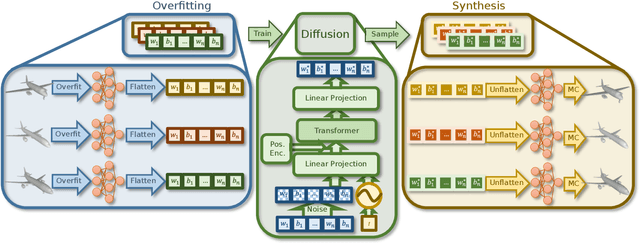
Implicit neural fields, typically encoded by a multilayer perceptron (MLP) that maps from coordinates (e.g., xyz) to signals (e.g., signed distances), have shown remarkable promise as a high-fidelity and compact representation. However, the lack of a regular and explicit grid structure also makes it challenging to apply generative modeling directly on implicit neural fields in order to synthesize new data. To this end, we propose HyperDiffusion, a novel approach for unconditional generative modeling of implicit neural fields. HyperDiffusion operates directly on MLP weights and generates new neural implicit fields encoded by synthesized MLP parameters. Specifically, a collection of MLPs is first optimized to faithfully represent individual data samples. Subsequently, a diffusion process is trained in this MLP weight space to model the underlying distribution of neural implicit fields. HyperDiffusion enables diffusion modeling over a implicit, compact, and yet high-fidelity representation of complex signals across 3D shapes and 4D mesh animations within one single unified framework.