 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrEditor3D: Fast and Precise 3D Shape Editing
Dec 09, 2024We propose a training-free approach to 3D editing that enables the editing of a single shape within a few minutes. The edited 3D mesh aligns well with the prompts, and remains identical for regions that are not intended to be altered. To this end, we first project the 3D object onto 4-view images and perform synchronized multi-view image editing along with user-guided text prompts and user-provided rough masks. However, the targeted regions to be edited are ambiguous due to projection from 3D to 2D. To ensure precise editing only in intended regions, we develop a 3D segmentation pipeline that detects edited areas in 3D space, followed by a merging algorithm to seamlessly integrate edited 3D regions with the original input. Extensive experiments demonstrate the superiority of our method over previous approaches, enabling fast, high-quality editing while preserving unintended regions.
ObjectMatch: Robust Registration using Canonical Object Correspondences
Dec 05, 2022



We present ObjectMatch, a semantic and object-centric camera pose estimation for RGB-D SLAM pipelines. Modern camera pose estimators rely on direct correspondences of overlapping regions between frames; however, they cannot align camera frames with little or no overlap. In this work, we propose to leverage indirect correspondences obtained via semantic object identification. For instance, when an object is seen from the front in one frame and from the back in another frame, we can provide additional pose constraints through canonical object correspondences. We first propose a neural network to predict such correspondences on a per-pixel level, which we then combine in our energy formulation with state-of-the-art keypoint matching solved with a joint Gauss-Newton optimization. In a pairwise setting, our method improves registration recall of state-of-the-art feature matching from 77% to 87% overall and from 21% to 52% in pairs with 10% or less inter-frame overlap. In registering RGB-D sequences, our method outperforms cutting-edge SLAM baselines in challenging, low frame-rate scenarios, achieving more than 35% reduction in trajectory error in multiple scenes.
ROCA: Robust CAD Model Retrieval and Alignment from a Single Image
Dec 03, 2021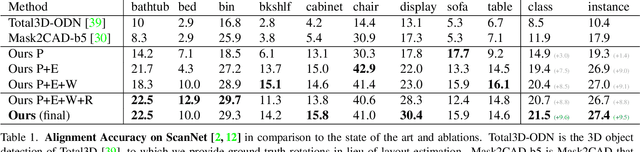



We present ROCA, a novel end-to-end approach that retrieves and aligns 3D CAD models from a shape database to a single input image. This enables 3D perception of an observed scene from a 2D RGB observation, characterized as a lightweight, compact, clean CAD representation. Core to our approach is our differentiable alignment optimization based on dense 2D-3D object correspondences and Procrustes alignment. ROCA can thus provide a robust CAD alignment while simultaneously informing CAD retrieval by leveraging the 2D-3D correspondences to learn geometrically similar CAD models. Experiments on challenging, real-world imagery from ScanNet show that ROCA significantly improves on state of the art, from 9.5% to 17.6% in retrieval-aware CAD alignment accuracy.