 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Sparse-to-Dense: Self-supervised Depth Completion from LiDAR and Monocular Camera
Paper and Code

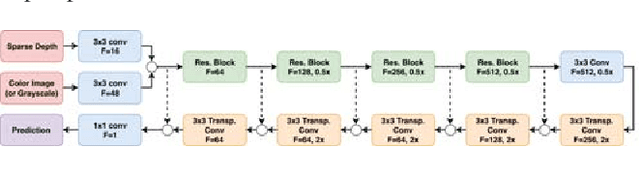
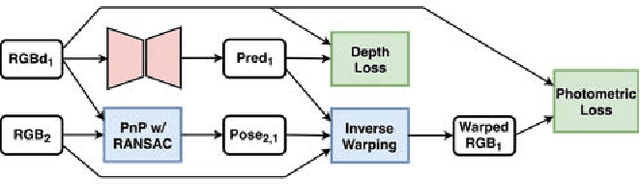
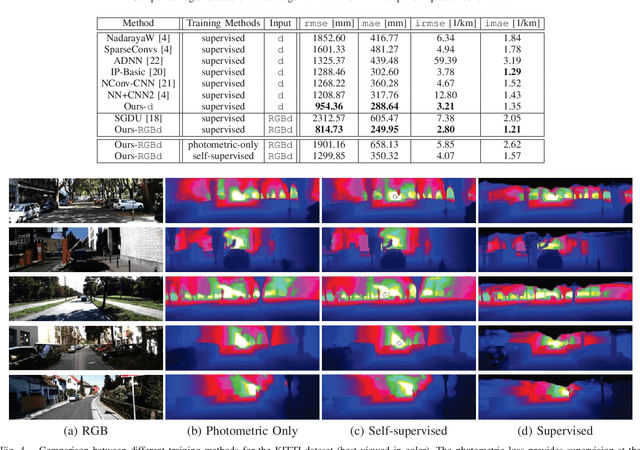
Depth completion, the technique of estimating a dense depth image from sparse depth measurements, has a variety of applications in robotics and autonomous driving. However, depth completion faces 3 main challenges: the irregularly spaced pattern in the sparse depth input, the difficulty in handling multiple sensor modalities (when color images are available), as well as the lack of dense, pixel-level ground truth depth labels. In this work, we address all these challenges. Specifically, we develop a deep regression model to learn a direct mapping from sparse depth (and color images) to dense depth. We also propose a self-supervised training framework that requires only sequences of color and sparse depth images, without the need for dense depth labels. Our experiments demonstrate that our network, when trained with semi-dense annotations, attains state-of-the- art accuracy and is the winning approach on the KITTI depth completion benchmark at the time of submission. Furthermore, the self-supervised framework outperforms a number of existing solutions trained with semi- dense annotations.