 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMUSE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Dec 18, 2025

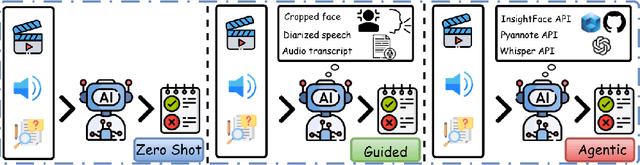
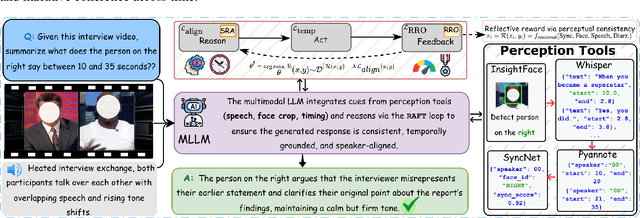
Recent multimodal large language models (MLLMs) such as GPT-4o and Qwen3-Omni show strong perception but struggle in multi-speaker, dialogue-centric settings that demand agentic reasoning tracking who speaks, maintaining roles, and grounding events across time. These scenarios are central to multimodal audio-video understanding, where models must jointly reason over audio and visual streams in applications such as conversational video assistants and meeting analytics. We introduce AMUSE, a benchmark designed around tasks that are inherently agentic, requiring models to decompose complex audio-visual interactions into planning, grounding, and reflection steps. It evaluates MLLMs across three modes zero-shot, guided, and agentic and six task families, including spatio-temporal speaker grounding and multimodal dialogue summarization. Across all modes, current models exhibit weak multi-speaker reasoning and inconsistent behavior under both non-agentic and agentic evaluation. Motivated by the inherently agentic nature of these tasks and recent advances in LLM agents, we propose RAFT, a data-efficient agentic alignment framework that integrates reward optimization with intrinsic multimodal self-evaluation as reward and selective parameter adaptation for data and parameter efficient updates. Using RAFT, we achieve up to 39.52\% relative improvement in accuracy on our benchmark. Together, AMUSE and RAFT provide a practical platform for examining agentic reasoning in multimodal models and improving their capabilities.
Probabilistic Speech-Driven 3D Facial Motion Synthesis: New Benchmarks, Methods, and Applications
Nov 30, 2023



We consider the task of animating 3D facial geometry from speech signal. Existing works are primarily deterministic, focusing on learning a one-to-one mapping from speech signal to 3D face meshes on small datasets with limited speakers. While these models can achieve high-quality lip articulation for speakers in the training set, they are unable to capture the full and diverse distribution of 3D facial motions that accompany speech in the real world. Importantly, the relationship between speech and facial motion is one-to-many, containing both inter-speaker and intra-speaker variations and necessitating a probabilistic approach. In this paper, we identify and address key challenges that have so far limited the development of probabilistic models: lack of datasets and metrics that are suitable for training and evaluating them, as well as the difficulty of designing a model that generates diverse results while remaining faithful to a strong conditioning signal as speech. We first propose large-scale benchmark datasets and metrics suitable for probabilistic modeling. Then, we demonstrate a probabilistic model that achieves both diversity and fidelity to speech, outperforming other methods across the proposed benchmarks. Finally, we showcase useful applications of probabilistic models trained on these large-scale datasets: we can generate diverse speech-driven 3D facial motion that matches unseen speaker styles extracted from reference clips; and our synthetic meshes can be used to improve the performance of downstream audio-visual models.
Multi-Domain Translation by Learning Uncoupled Autoencoders
Feb 09, 2019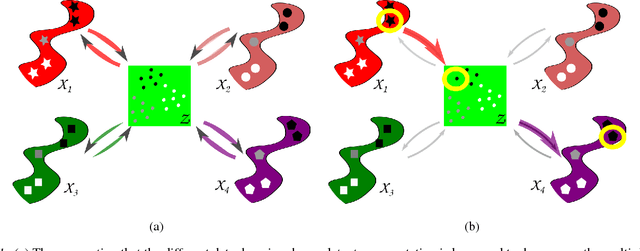
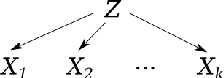
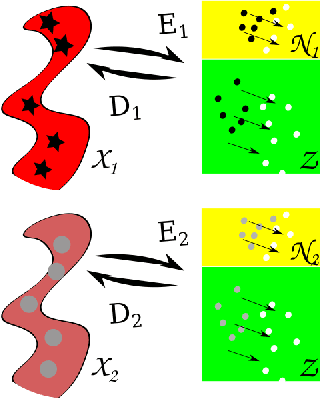

Multi-domain translation seeks to learn a probabilistic coupling between marginal distributions that reflects the correspondence between different domains. We assume that data from different domains are generated from a shared latent representation based on a structural equation model. Under this assumption, we show that the problem of computing a probabilistic coupling between marginals is equivalent to learning multiple uncoupled autoencoders that embed to a given shared latent distribution. In addition, we propose a new framework and algorithm for multi-domain translation based on learning the shared latent distribution and training autoencoders under distributional constraints. A key practical advantage of our framework is that new autoencoders (i.e., new domains) can be added sequentially to the model without retraining on the other domains, which we demonstrate experimentally on image as well as genomics datasets.
Scalable Unbalanced Optimal Transport using Generative Adversarial Networks
Oct 26, 2018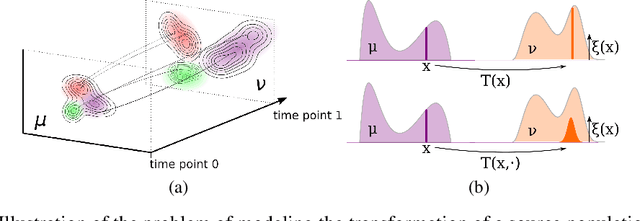

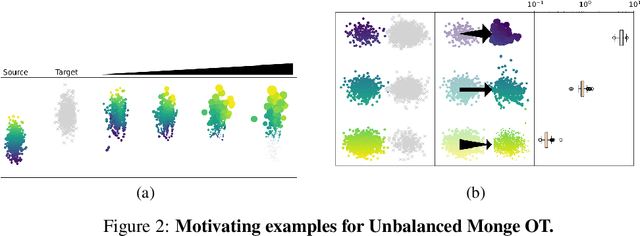
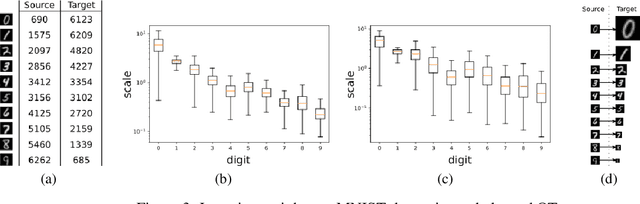
Generative adversarial networks (GANs) are an expressive class of neural generative models with tremendous success in modeling high-dimensional continuous measures. In this paper, we present a scalable method for unbalanced optimal transport (OT) based on the generative-adversarial framework. We formulate unbalanced OT as a problem of simultaneously learning a transport map and a scaling factor that push a source measure to a target measure in a cost-optimal manner. In addition, we propose an algorithm for solving this problem based on stochastic alternating gradient updates, similar in practice to GANs. We also provide theoretical justification for this formulation, showing that it is closely related to an existing static formulation by Liero et al. (2018), and perform numerical experiments demonstrating how this methodology can be applied to population modeling.