 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Hidden States Enables Learning Generalizable Reward Model for LLMs
Paper and Code
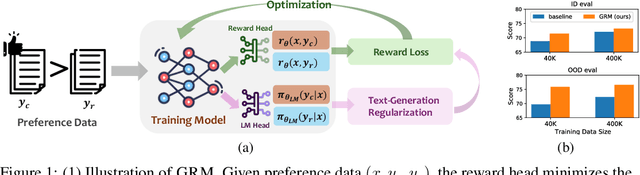
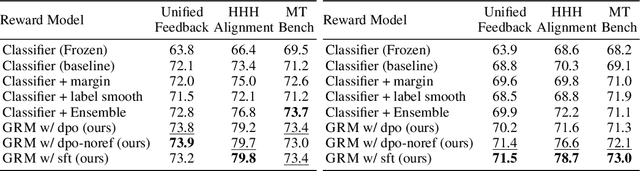


Reward models trained on human preference data have been proven to be effective for aligning Large Language Models (LLMs) with human intent within the reinforcement learning from human feedback (RLHF) framework. However, the generalization capabilities of current reward models to unseen prompts and responses are limited. This limitation can lead to an unexpected phenomenon known as reward over-optimization, where excessive optimization of rewards results in a decline in actual performance. While previous research has advocated for constraining policy optimization, our study proposes a novel approach to enhance the reward model's generalization ability against distribution shifts by regularizing the hidden states. Specifically, we retain the base model's language model head and incorporate a suite of text-generation losses to preserve the hidden states' text generation capabilities, while concurrently learning a reward head behind the same hidden states. Our experimental results demonstrate that the introduced regularization technique markedly improves the accuracy of learned reward models across a variety of out-of-distribution (OOD) tasks and effectively alleviate the over-optimization issue in RLHF, offering a more reliable and robust preference learning paradigm.