 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative MoE: Communication Efficient Parallel MoE Inference with Speculative Token and Expert Pre-scheduling
Mar 07, 2025



MoE (Mixture of Experts) prevails as a neural architecture that can scale modern transformer-based LLMs (Large Language Models) to unprecedented scales. Nevertheless, large MoEs' great demands of computing power, memory capacity and memory bandwidth make scalable serving a fundamental challenge and efficient parallel inference has become a requisite to attain adequate throughput under latency constraints. DeepSpeed-MoE, one state-of-the-art MoE inference framework, adopts a 3D-parallel paradigm including EP (Expert Parallelism), TP (Tensor Parallel) and DP (Data Parallelism). However, our analysis shows DeepSpeed-MoE's inference efficiency is largely bottlenecked by EP, which is implemented with costly all-to-all collectives to route token activation. Our work aims to boost DeepSpeed-MoE by strategically reducing EP's communication overhead with a technique named Speculative MoE. Speculative MoE has two speculative parallelization schemes, speculative token shuffling and speculative expert grouping, which predict outstanding tokens' expert routing paths and pre-schedule tokens and experts across devices to losslessly trim EP's communication volume. Besides DeepSpeed-MoE, we also build Speculative MoE into a prevailing MoE inference engine SGLang. Experiments show Speculative MoE can significantly boost state-of-the-art MoE inference frameworks on fast homogeneous and slow heterogeneous interconnects.
Towards A Comprehensive Visual Saliency Explanation Framework for AI-based Face Recognition Systems
Jul 08, 2024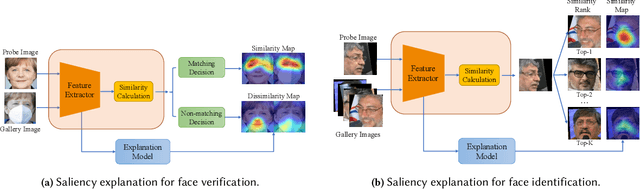
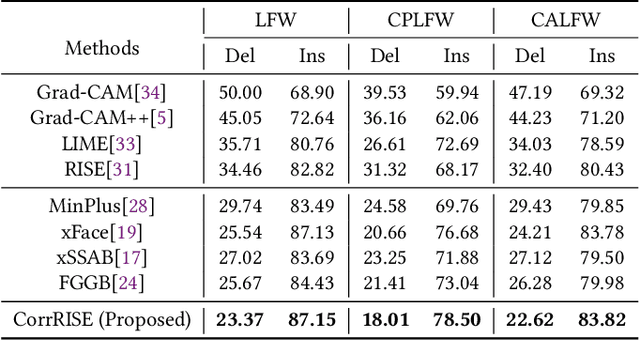
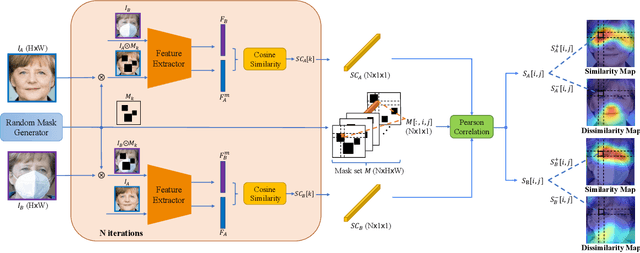
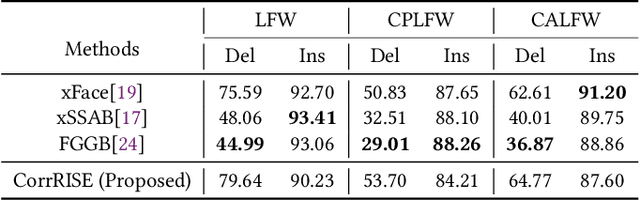
Over recent years, deep convolutional neural networks have significantly advanced the field of face recognition techniques for both verification and identification purposes. Despite the impressive accuracy, these neural networks are often criticized for lacking explainability. There is a growing demand for understanding the decision-making process of AI-based face recognition systems. Some studies have investigated the use of visual saliency maps as explanations, but they have predominantly focused on the specific face verification case. The discussion on more general face recognition scenarios and the corresponding evaluation methodology for these explanations have long been absent in current research. Therefore, this manuscript conceives a comprehensive explanation framework for face recognition tasks. Firstly, an exhaustive definition of visual saliency map-based explanations for AI-based face recognition systems is provided, taking into account the two most common recognition situations individually, i.e., face verification and identification. Secondly, a new model-agnostic explanation method named CorrRISE is proposed to produce saliency maps, which reveal both the similar and dissimilar regions between any given face images. Subsequently, the explanation framework conceives a new evaluation methodology that offers quantitative measurement and comparison of the performance of general visual saliency explanation methods in face recognition. Consequently, extensive experiments are carried out on multiple verification and identification scenarios. The results showcase that CorrRISE generates insightful saliency maps and demonstrates superior performance, particularly in similarity maps in comparison with the state-of-the-art explanation approaches.
Explainable Face Verification via Feature-Guided Gradient Backpropagation
Mar 07, 2024Recent years have witnessed significant advancement in face recognition (FR) techniques, with their applications widely spread in people's lives and security-sensitive areas. There is a growing need for reliable interpretations of decisions of such systems. Existing studies relying on various mechanisms have investigated the usage of saliency maps as an explanation approach, but suffer from different limitations. This paper first explores the spatial relationship between face image and its deep representation via gradient backpropagation. Then a new explanation approach FGGB has been conceived, which provides precise and insightful similarity and dissimilarity saliency maps to explain the "Accept" and "Reject" decision of an FR system. Extensive visual presentation and quantitative measurement have shown that FGGB achieves superior performance in both similarity and dissimilarity maps when compared to current state-of-the-art explainable face verification approaches.
Discriminative Deep Feature Visualization for Explainable Face Recognition
Jun 01, 2023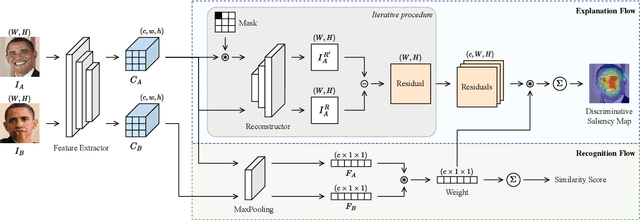
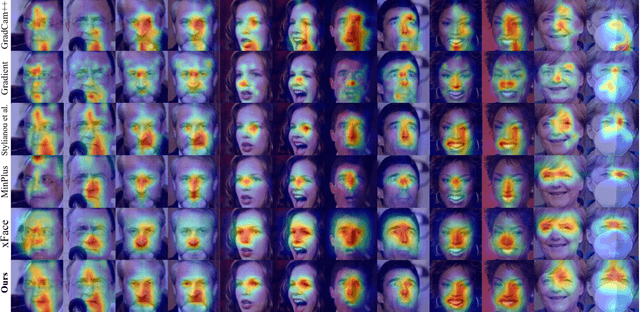
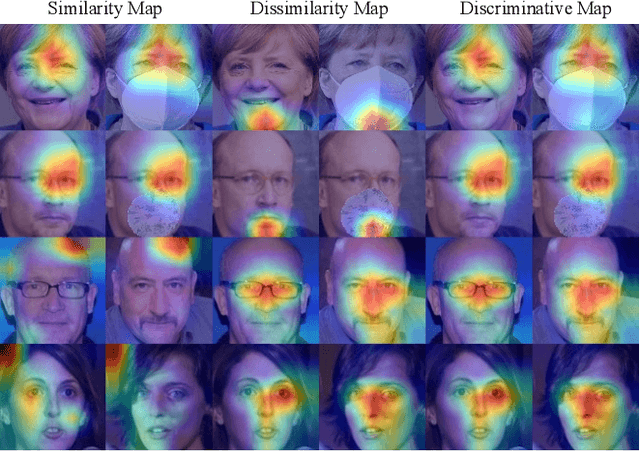
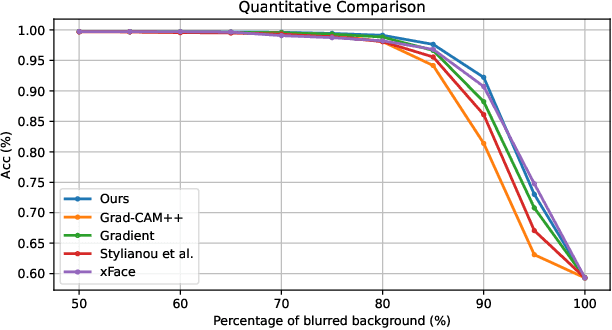
Despite the huge success of deep convolutional neural networks in face recognition (FR) tasks, current methods lack explainability for their predictions because of their "black-box" nature. In recent years, studies have been carried out to give an interpretation of the decision of a deep FR system. However, the affinity between the input facial image and the extracted deep features has not been explored. This paper contributes to the problem of explainable face recognition by first conceiving a face reconstruction-based explanation module, which reveals the correspondence between the deep feature and the facial regions. To further interpret the decision of an FR model, a novel visual saliency explanation algorithm has been proposed. It provides insightful explanation by producing visual saliency maps that represent similar and dissimilar regions between input faces. A detailed analysis has been presented for the generated visual explanation to show the effectiveness of the proposed method.
Towards Visual Saliency Explanations of Face Recognition
May 15, 2023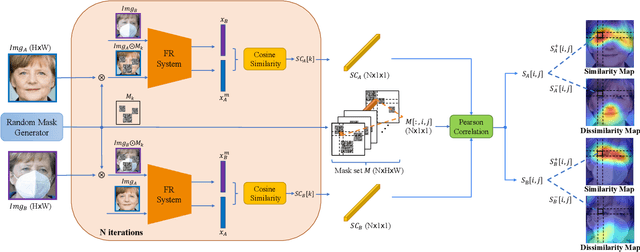



Deep convolutional neural networks have been pushing the frontier of face recognition (FR) techniques in the past years. Despite the high accuracy, they are often criticized for lacking explainability. There has been an increasing demand for understanding the decision-making process of deep face recognition systems. Recent studies have investigated using visual saliency maps as an explanation, but they often lack a discussion and analysis in the context of face recognition. This paper conceives a new explanation framework for face recognition. It starts by providing a new definition of the saliency-based explanation method, which focuses on the decisions made by the deep FR model. Then, a novel correlation-based RISE algorithm (CorrRISE) is proposed to produce saliency maps, which reveal both the similar and dissimilar regions of any given pair of face images. Besides, two evaluation metrics are designed to measure the performance of general visual saliency explanation methods in face recognition. Consequently, substantial visual and quantitative results have shown that the proposed method consistently outperforms other explainable face recognition approaches.
Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism
Jan 24, 2023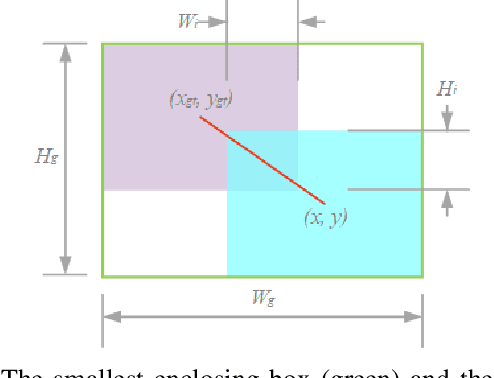
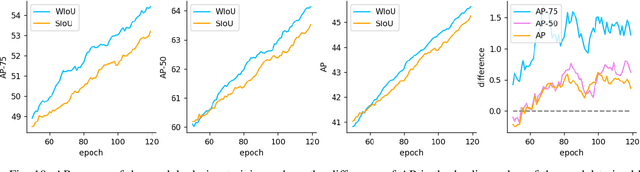

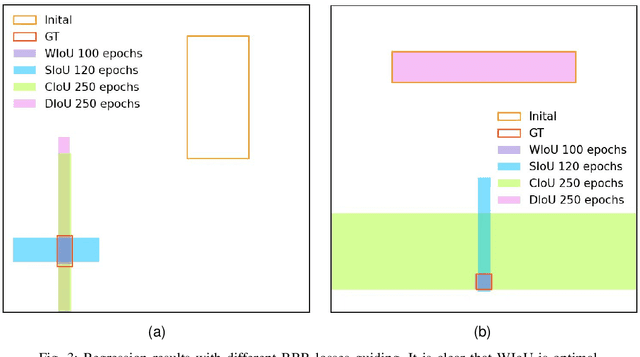
The loss function for bounding box regression (BBR) is essential to object detection. Its good definition will bring significant performance improvement to the model. Most existing works assume that the examples in the training data are high-quality and focus on strengthening the fitting ability of BBR loss. If we blindly strengthen BBR on low-quality examples, it will jeopardize localization performance. Focal-EIoU v1 was proposed to solve this problem, but due to its static focusing mechanism (FM), the potential of non-monotonic FM was not fully exploited. Based on this idea, we propose an IoU-based loss with a dynamic non-monotonic FM named Wise-IoU (WIoU). When WIoU is applied to the state-of-the-art real-time detector YOLOv7, the AP-75 on the MS-COCO dataset is improved from 53.03% to 54.50%.
Explainable Sentence-Level Sentiment Analysis for Amazon Product Reviews
Nov 11, 2021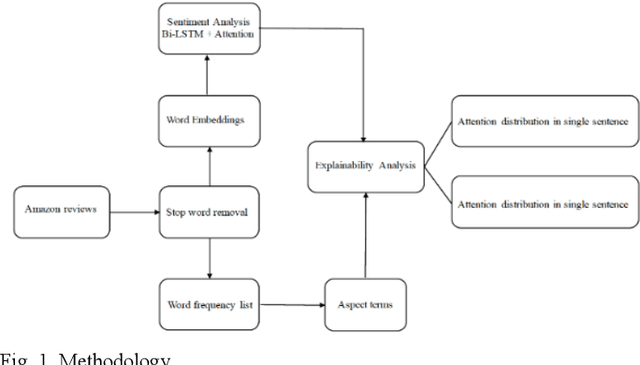
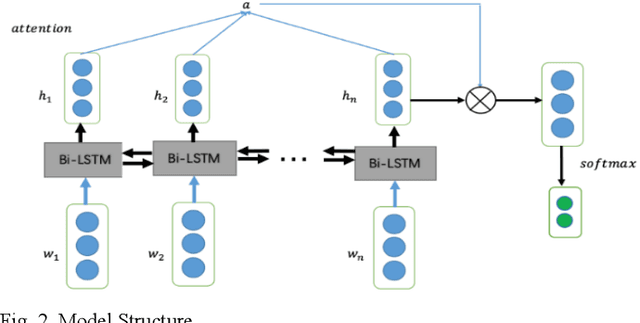
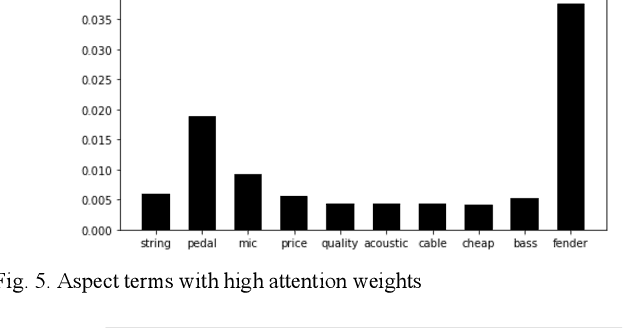
In this paper, we conduct a sentence level sentiment analysis on the product reviews from Amazon and thorough analysis on the model interpretability. For the sentiment analysis task, we use the BiLSTM model with attention mechanism. For the study of interpretability, we consider the attention weights distribution of single sentence and the attention weights of main aspect terms. The model has an accuracy of up to 0.96. And we find that the aspect terms have the same or even more attention weights than the sentimental words in sentences.
DAPnet: A double self-attention convolutional network for segmentation of point clouds
Apr 18, 2020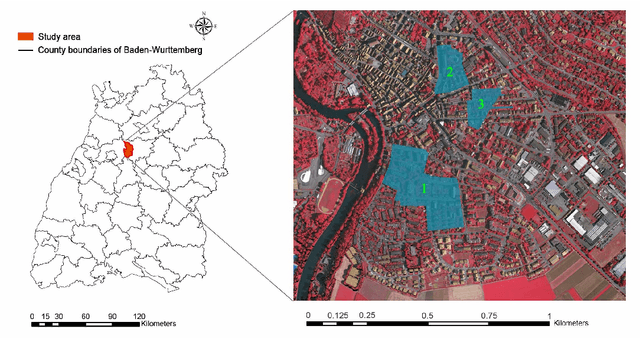

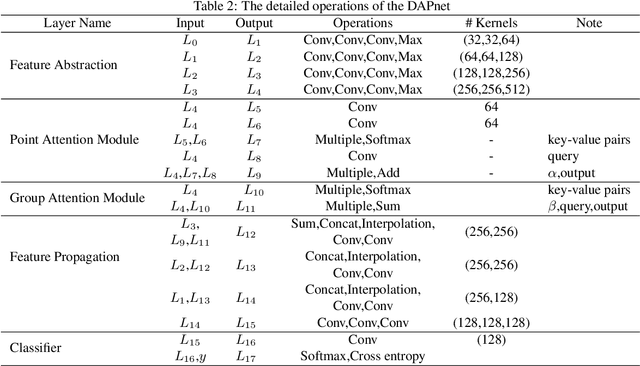
LiDAR point cloud has a complex structure and the 3D semantic labeling of it is a challenging task. Existing methods adopt data transformations without fully exploring contextual features, which are less efficient and accurate problem. In this study, we propose a double self-attention convolutional network, called DAPnet, by combining geometric and contextual features to generate better segmentation results. The double self-attention module including point attention module and group attention module originates from the self-attention mechanism to extract contextual features of terrestrial objects with various shapes and scales. The contextual features extracted by these modules represent the long-range dependencies between the data and are beneficial to reducing the scale diversity of point cloud objects. The point attention module selectively enhances the features by modeling the interdependencies of neighboring points. Meanwhile, the group attention module is used to emphasizes interdependent groups of points. We evaluate our method based on the ISPRS 3D Semantic Labeling Contest dataset and find that our model outperforms the benchmark by 85.2% with an overall accuracy of 90.7%. The improvements over powerline and car are 7.5% and 13%. By conducting ablation comparison, we find that the point attention module is more effective for the overall improvement of the model than the group attention module, and the incorporation of the double self-attention module has an average of 7% improvement on the pre-class accuracy of the classes. Moreover, the adoption of the double self-attention module consumes a similar training time as the one without the attention module for model convergence. The experimental result shows the effectiveness and efficiency of the DAPnet for the segmentation of LiDAR point clouds. The source codes are available at https://github.com/RayleighChen/point-attention.