 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAPnet: A double self-attention convolutional network for segmentation of point clouds
Paper and Code
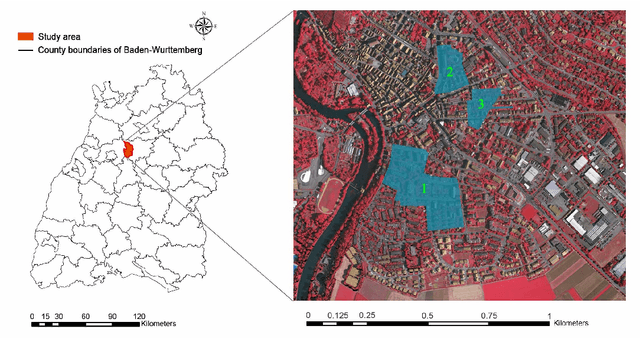

LiDAR point cloud has a complex structure and the 3D semantic labeling of it is a challenging task. Existing methods adopt data transformations without fully exploring contextual features, which are less efficient and accurate problem. In this study, we propose a double self-attention convolutional network, called DAPnet, by combining geometric and contextual features to generate better segmentation results. The double self-attention module including point attention module and group attention module originates from the self-attention mechanism to extract contextual features of terrestrial objects with various shapes and scales. The contextual features extracted by these modules represent the long-range dependencies between the data and are beneficial to reducing the scale diversity of point cloud objects. The point attention module selectively enhances the features by modeling the interdependencies of neighboring points. Meanwhile, the group attention module is used to emphasizes interdependent groups of points. We evaluate our method based on the ISPRS 3D Semantic Labeling Contest dataset and find that our model outperforms the benchmark by 85.2% with an overall accuracy of 90.7%. The improvements over powerline and car are 7.5% and 13%. By conducting ablation comparison, we find that the point attention module is more effective for the overall improvement of the model than the group attention module, and the incorporation of the double self-attention module has an average of 7% improvement on the pre-class accuracy of the classes. Moreover, the adoption of the double self-attention module consumes a similar training time as the one without the attention module for model convergence. The experimental result shows the effectiveness and efficiency of the DAPnet for the segmentation of LiDAR point clouds. The source codes are available at https://github.com/RayleighChen/point-attention.