 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry From Scratch: Group Equivariance as a Supervised Learning Task
Oct 05, 2024In machine learning datasets with symmetries, the paradigm for backward compatibility with symmetry-breaking has been to relax equivariant architectural constraints, engineering extra weights to differentiate symmetries of interest. However, this process becomes increasingly over-engineered as models are geared towards specific symmetries/asymmetries hardwired of a particular set of equivariant basis functions. In this work, we introduce symmetry-cloning, a method for inducing equivariance in machine learning models. We show that general machine learning architectures (i.e., MLPs) can learn symmetries directly as a supervised learning task from group equivariant architectures and retain/break the learned symmetry for downstream tasks. This simple formulation enables machine learning models with group-agnostic architectures to capture the inductive bias of group-equivariant architectures.
Integrating Large Pre-trained Models into Multimodal Named Entity Recognition with Evidential Fusion
Jun 29, 2023Multimodal Named Entity Recognition (MNER) is a crucial task for information extraction from social media platforms such as Twitter. Most current methods rely on attention weights to extract information from both text and images but are often unreliable and lack interpretability. To address this problem, we propose incorporating uncertainty estimation into the MNER task, producing trustworthy predictions. Our proposed algorithm models the distribution of each modality as a Normal-inverse Gamma distribution, and fuses them into a unified distribution with an evidential fusion mechanism, enabling hierarchical characterization of uncertainties and promotion of prediction accuracy and trustworthiness. Additionally, we explore the potential of pre-trained large foundation models in MNER and propose an efficient fusion approach that leverages their robust feature representations. Experiments on two datasets demonstrate that our proposed method outperforms the baselines and achieves new state-of-the-art performance.
Remote Sensing Images Semantic Segmentation with General Remote Sensing Vision Model via a Self-Supervised Contrastive Learning Method
Jun 20, 2021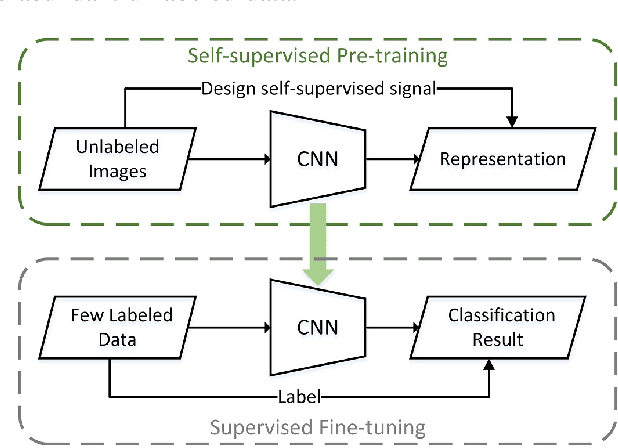
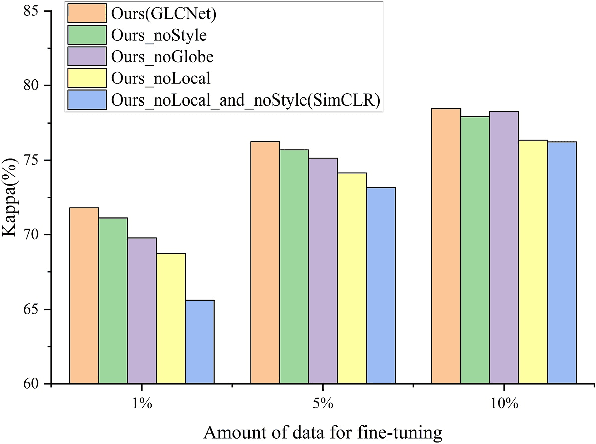
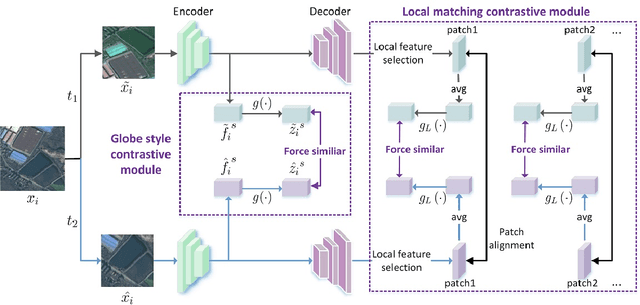
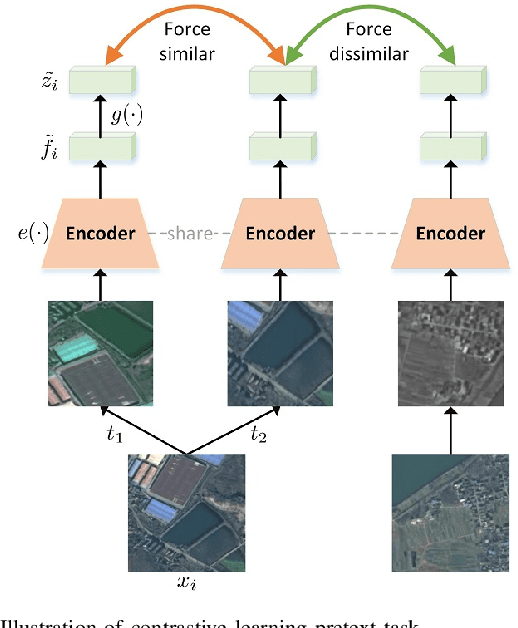
A new learning paradigm, self-supervised learning (SSL), can be used to solve such problems by pre-training a general model with large unlabeled images and then fine-tuning on a downstream task with very few labeled samples. Contrastive learning is a typical method of SSL, which can learn general invariant features. However, most of the existing contrastive learning is designed for classification tasks to obtain an image-level representation, which may be sub-optimal for semantic segmentation tasks requiring pixel-level discrimination. Therefore, we propose Global style and Local matching Contrastive Learning Network (GLCNet) for remote sensing semantic segmentation. Specifically, the global style contrastive module is used to learn an image-level representation better, as we consider the style features can better represent the overall image features; The local features matching contrastive module is designed to learn representations of local regions which is beneficial for semantic segmentation. We evaluate four remote sensing semantic segmentation datasets, and the experimental results show that our method mostly outperforms state-of-the-art self-supervised methods and ImageNet pre-training. Specifically, with 1\% annotation from the original dataset, our approach improves Kappa by 6\% on the ISPRS Potsdam dataset and 3\% on Deep Globe Land Cover Classification dataset relative to the existing baseline. Moreover, our method outperforms supervised learning when there are some differences between the datasets of upstream tasks and downstream tasks. Our study promotes the development of self-supervised learning in the field of remote sensing semantic segmentation. The source code is available at https://github.com/GeoX-Lab/G-RSIM.
RS-MetaNet: Deep meta metric learning for few-shot remote sensing scene classification
Sep 28, 2020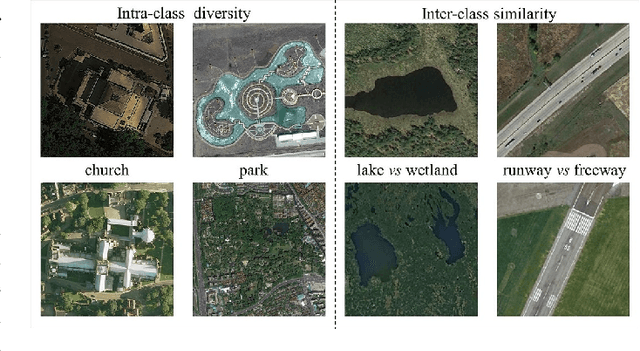

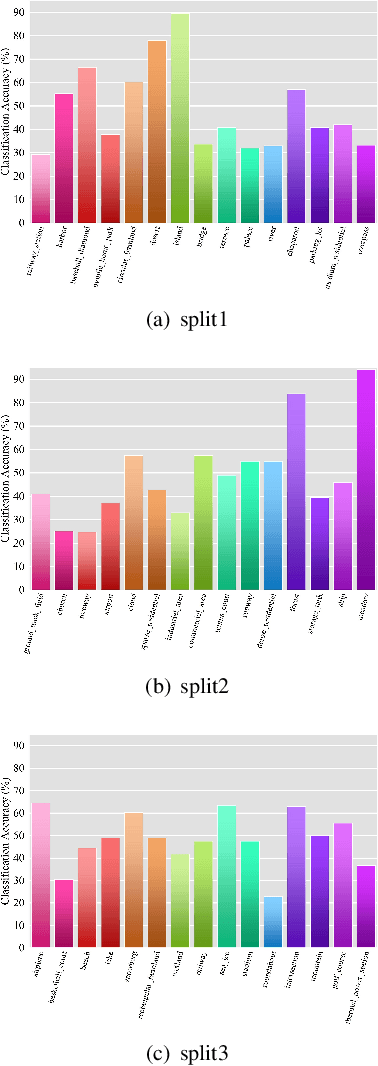

Training a modern deep neural network on massive labeled samples is the main paradigm in solving the scene classification problem for remote sensing, but learning from only a few data points remains a challenge. Existing methods for few-shot remote sensing scene classification are performed in a sample-level manner, resulting in easy overfitting of learned features to individual samples and inadequate generalization of learned category segmentation surfaces. To solve this problem, learning should be organized at the task level rather than the sample level. Learning on tasks sampled from a task family can help tune learning algorithms to perform well on new tasks sampled in that family. Therefore, we propose a simple but effective method, called RS-MetaNet, to resolve the issues related to few-shot remote sensing scene classification in the real world. On the one hand, RS-MetaNet raises the level of learning from the sample to the task by organizing training in a meta way, and it learns to learn a metric space that can well classify remote sensing scenes from a series of tasks. We also propose a new loss function, called Balance Loss, which maximizes the generalization ability of the model to new samples by maximizing the distance between different categories, providing the scenes in different categories with better linear segmentation planes while ensuring model fit. The experimental results on three open and challenging remote sensing datasets, UCMerced\_LandUse, NWPU-RESISC45, and Aerial Image Data, demonstrate that our proposed RS-MetaNet method achieves state-of-the-art results in cases where there are only 1-20 labeled samples.
* 13 pages, 11 figures
DAPnet: A double self-attention convolutional network for segmentation of point clouds
Apr 18, 2020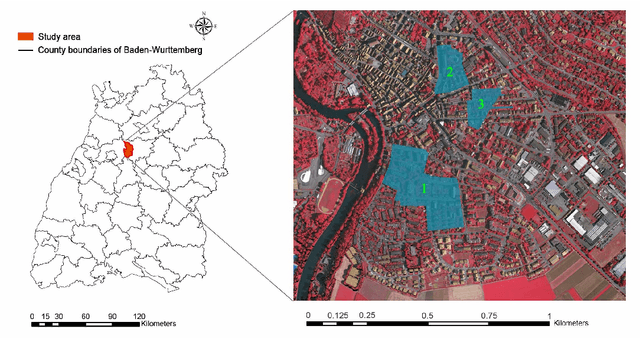
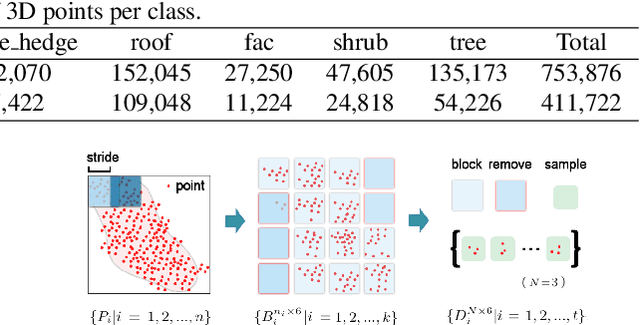

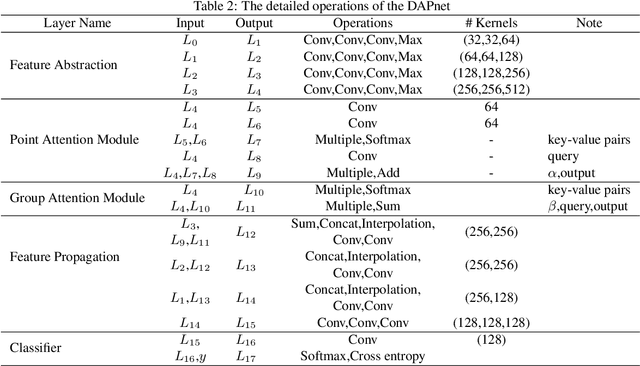
LiDAR point cloud has a complex structure and the 3D semantic labeling of it is a challenging task. Existing methods adopt data transformations without fully exploring contextual features, which are less efficient and accurate problem. In this study, we propose a double self-attention convolutional network, called DAPnet, by combining geometric and contextual features to generate better segmentation results. The double self-attention module including point attention module and group attention module originates from the self-attention mechanism to extract contextual features of terrestrial objects with various shapes and scales. The contextual features extracted by these modules represent the long-range dependencies between the data and are beneficial to reducing the scale diversity of point cloud objects. The point attention module selectively enhances the features by modeling the interdependencies of neighboring points. Meanwhile, the group attention module is used to emphasizes interdependent groups of points. We evaluate our method based on the ISPRS 3D Semantic Labeling Contest dataset and find that our model outperforms the benchmark by 85.2% with an overall accuracy of 90.7%. The improvements over powerline and car are 7.5% and 13%. By conducting ablation comparison, we find that the point attention module is more effective for the overall improvement of the model than the group attention module, and the incorporation of the double self-attention module has an average of 7% improvement on the pre-class accuracy of the classes. Moreover, the adoption of the double self-attention module consumes a similar training time as the one without the attention module for model convergence. The experimental result shows the effectiveness and efficiency of the DAPnet for the segmentation of LiDAR point clouds. The source codes are available at https://github.com/RayleighChen/point-attention.
DASNet: Dual attentive fully convolutional siamese networks for change detection of high resolution satellite images
Mar 07, 2020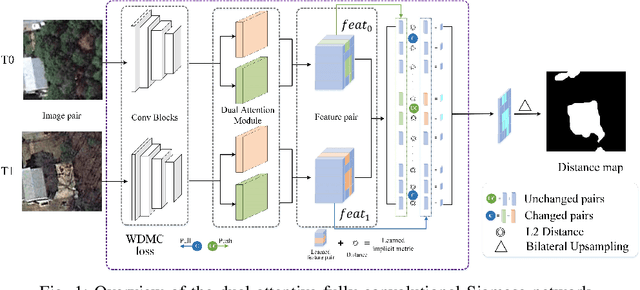



Change detection is a basic task of remote sensing image processing. The research objective is to identity the change information of interest and filter out the irrelevant change information as interference factors. Recently, the rise of deep learning has provided new tools for change detection, which have yielded impressive results. However, the available methods focus mainly on the difference information between multitemporal remote sensing images and lack robustness to pseudo-change information. To overcome the lack of resistance of current methods to pseudo-changes, in this paper, we propose a new method, namely, dual attentive fully convolutional Siamese networks (DASNet) for change detection in high-resolution images. Through the dual-attention mechanism, long-range dependencies are captured to obtain more discriminant feature representations to enhance the recognition performance of the model. Moreover, the imbalanced sample is a serious problem in change detection, i.e. unchanged samples are much more than changed samples, which is one of the main reasons resulting in pseudo-changes. We put forward the weighted double margin contrastive loss to address this problem by punishing the attention to unchanged feature pairs and increase attention to changed feature pairs. The experimental results of our method on the change detection dataset (CDD) and the building change detection dataset (BCDD) demonstrate that compared with other baseline methods, the proposed method realizes maximum improvements of 2.1\% and 3.6\%, respectively, in the F1 score. Our Pytorch implementation is available at https://github.com/lehaifeng/DASNet.
Convolution Neural Network Architecture Learning for Remote Sensing Scene Classification
Jan 27, 2020
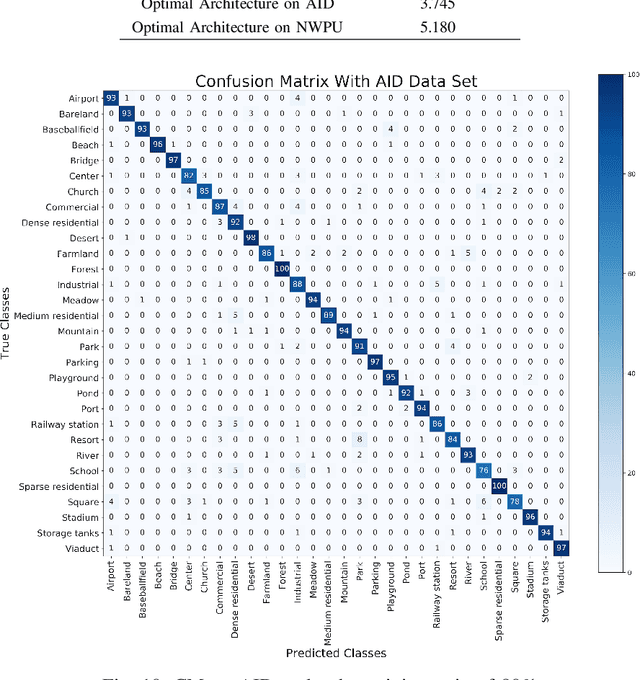
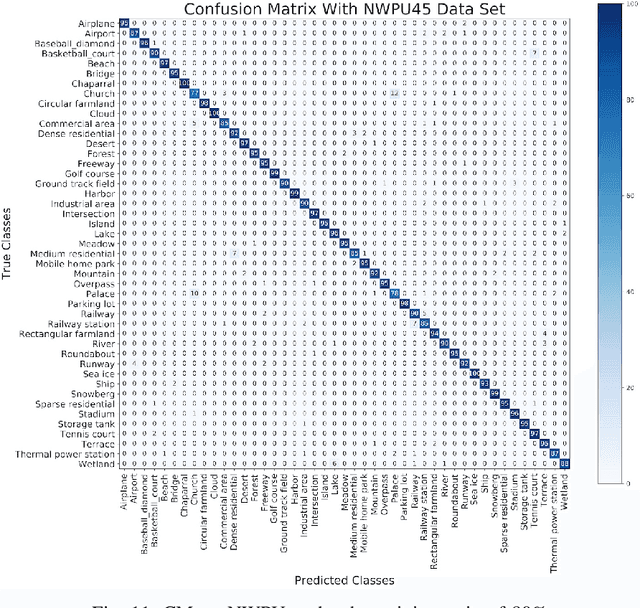

Remote sensing image scene classification is a fundamental but challenging task in understanding remote sensing images. Recently, deep learning-based methods, especially convolutional neural network-based (CNN-based) methods have shown enormous potential to understand remote sensing images. CNN-based methods meet with success by utilizing features learned from data rather than features designed manually. The feature-learning procedure of CNN largely depends on the architecture of CNN. However, most of the architectures of CNN used for remote sensing scene classification are still designed by hand which demands a considerable amount of architecture engineering skills and domain knowledge, and it may not play CNN's maximum potential on a special dataset. In this paper, we proposed an automatically architecture learning procedure for remote sensing scene classification. We designed a parameters space in which every set of parameters represents a certain architecture of CNN (i.e., some parameters represent the type of operators used in the architecture such as convolution, pooling, no connection or identity, and the others represent the way how these operators connect). To discover the optimal set of parameters for a given dataset, we introduced a learning strategy which can allow efficient search in the architecture space by means of gradient descent. An architecture generator finally maps the set of parameters into the CNN used in our experiments.
Adversarial Feature Genome: a Data Driven Adversarial Examples Recognition Method
Dec 25, 2018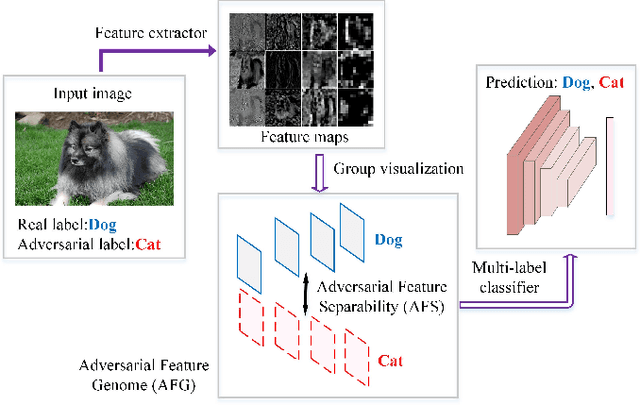
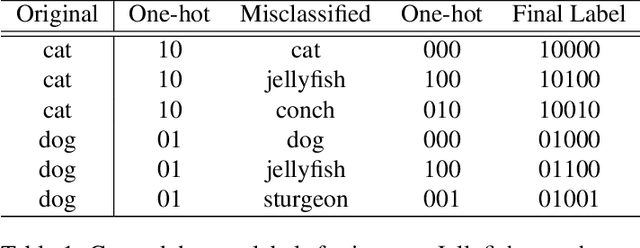
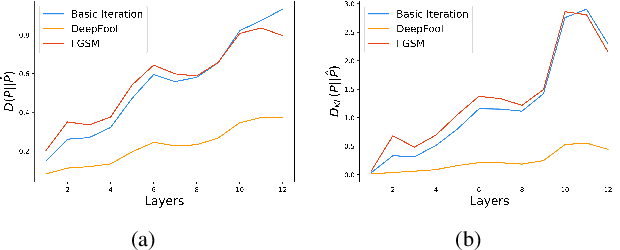

Convolutional neural networks (CNNs) are easily spoofed by adversarial examples which lead to wrong classification result. Most of the one-way defense methods focus only on how to improve the robustness of a CNN or to identify adversarial examples. They are incapable of identifying and correctly classifying adversarial examples simultaneously due to the lack of an effective way to quantitatively represent changes in the characteristics of the sample within the network. We find that adversarial examples and original ones have diverse representation in the feature space. Moreover, this difference grows as layers go deeper, which we call Adversarial Feature Separability (AFS). Inspired by AFS, we propose an Adversarial Feature Genome (AFG) based adversarial examples defense framework which can detect adversarial examples and correctly classify them into original category simultaneously. First, we extract the representations of adversarial examples and original ones with labels by the group visualization method. Then, we encode the representations into the feature database AFG. Finally, we model adversarial examples recognition as a multi-label classification or prediction problem by training a CNN for recognizing adversarial examples and original examples on the AFG. Experiments show that the proposed framework can not only effectively identify the adversarial examples in the defense process, but also correctly classify adversarial examples with mean accuracy up to 63\%. Our framework potentially gives a new perspective, i.e. data-driven way, to adversarial examples defense. We believe that adversarial examples defense research may benefit from a large scale AFG database which is similar to ImageNet. The database and source code can be visited at https://github.com/lehaifeng/Adversarial_Feature_Genome.