 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Reverse-engineering of Trojan Triggers
Oct 27, 2022Deep Neural Networks are vulnerable to Trojan (or backdoor) attacks. Reverse-engineering methods can reconstruct the trigger and thus identify affected models. Existing reverse-engineering methods only consider input space constraints, e.g., trigger size in the input space. Expressly, they assume the triggers are static patterns in the input space and fail to detect models with feature space triggers such as image style transformations. We observe that both input-space and feature-space Trojans are associated with feature space hyperplanes. Based on this observation, we design a novel reverse-engineering method that exploits the feature space constraint to reverse-engineer Trojan triggers. Results on four datasets and seven different attacks demonstrate that our solution effectively defends both input-space and feature-space Trojans. It outperforms state-of-the-art reverse-engineering methods and other types of defenses in both Trojaned model detection and mitigation tasks. On average, the detection accuracy of our method is 93\%. For Trojan mitigation, our method can reduce the ASR (attack success rate) to only 0.26\% with the BA (benign accuracy) remaining nearly unchanged. Our code can be found at https://github.com/RU-System-Software-and-Security/FeatureRE.
Neural Network Trojans Analysis and Mitigation from the Input Domain
Feb 16, 2022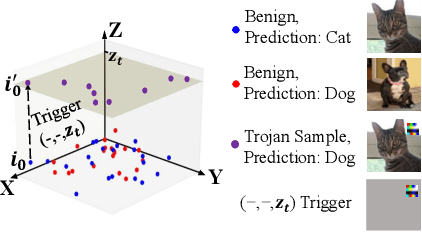
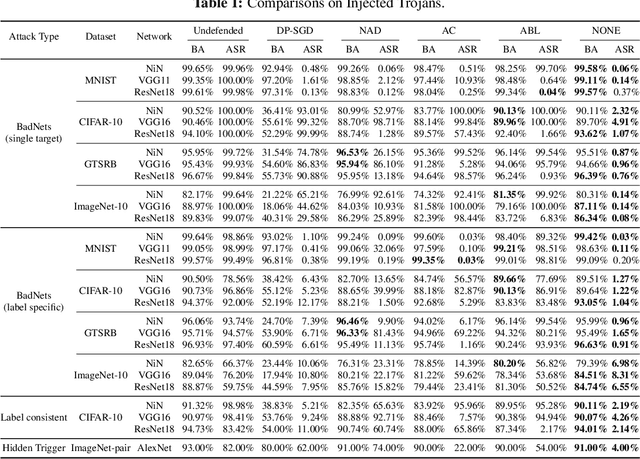
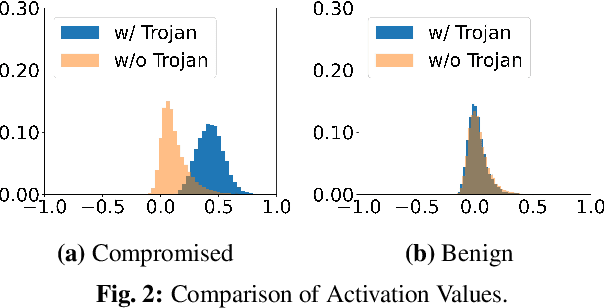
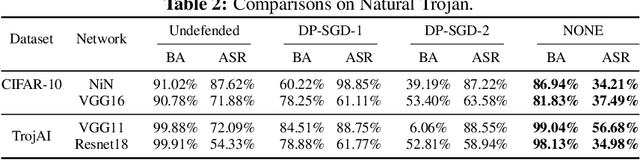
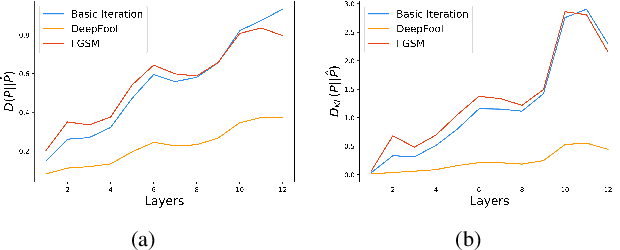
Deep Neural Networks (DNNs) can learn Trojans (or backdoors) from benign or poisoned data, which raises security concerns of using them. By exploiting such Trojans, the adversary can add a fixed input space perturbation to any given input to mislead the model predicting certain outputs (i.e., target labels). In this paper, we analyze such input space Trojans in DNNs, and propose a theory to explain the relationship of a model's decision regions and Trojans: a complete and accurate Trojan corresponds to a hyperplane decision region in the input domain. We provide a formal proof of this theory, and provide empirical evidence to support the theory and its relaxations. Based on our analysis, we design a novel training method that removes Trojans during training even on poisoned datasets, and evaluate our prototype on five datasets and five different attacks. Results show that our method outperforms existing solutions. Code: \url{https://anonymous.4open.science/r/NOLE-84C3}.
Adversarial Feature Genome: a Data Driven Adversarial Examples Recognition Method
Dec 25, 2018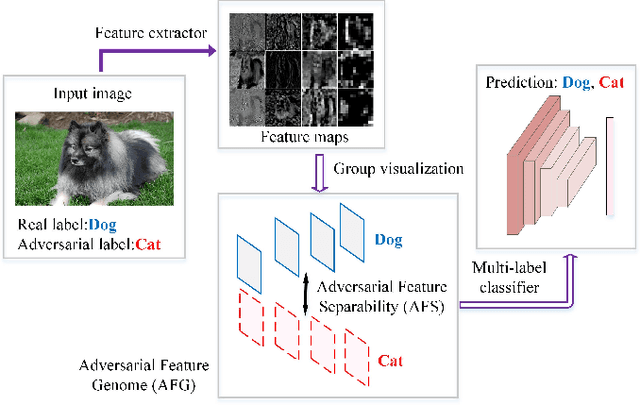
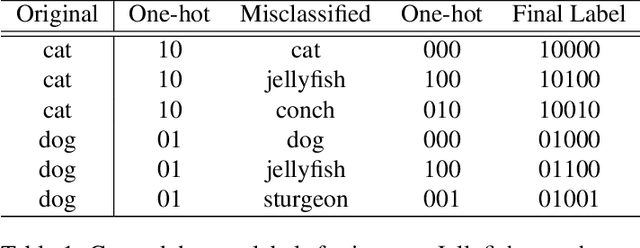

Convolutional neural networks (CNNs) are easily spoofed by adversarial examples which lead to wrong classification result. Most of the one-way defense methods focus only on how to improve the robustness of a CNN or to identify adversarial examples. They are incapable of identifying and correctly classifying adversarial examples simultaneously due to the lack of an effective way to quantitatively represent changes in the characteristics of the sample within the network. We find that adversarial examples and original ones have diverse representation in the feature space. Moreover, this difference grows as layers go deeper, which we call Adversarial Feature Separability (AFS). Inspired by AFS, we propose an Adversarial Feature Genome (AFG) based adversarial examples defense framework which can detect adversarial examples and correctly classify them into original category simultaneously. First, we extract the representations of adversarial examples and original ones with labels by the group visualization method. Then, we encode the representations into the feature database AFG. Finally, we model adversarial examples recognition as a multi-label classification or prediction problem by training a CNN for recognizing adversarial examples and original examples on the AFG. Experiments show that the proposed framework can not only effectively identify the adversarial examples in the defense process, but also correctly classify adversarial examples with mean accuracy up to 63\%. Our framework potentially gives a new perspective, i.e. data-driven way, to adversarial examples defense. We believe that adversarial examples defense research may benefit from a large scale AFG database which is similar to ImageNet. The database and source code can be visited at https://github.com/lehaifeng/Adversarial_Feature_Genome.
Understanding the Importance of Single Directions via Representative Substitution
Dec 06, 2018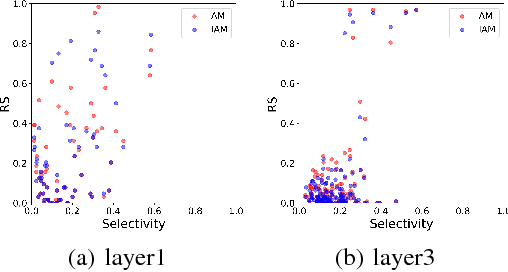
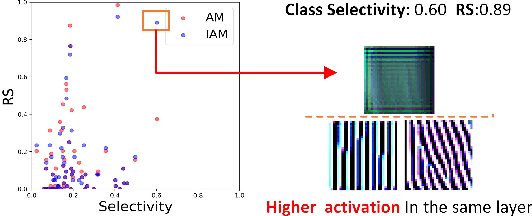
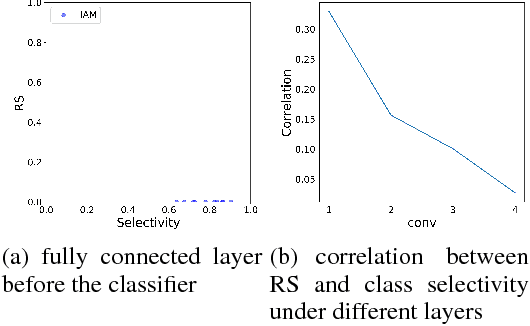
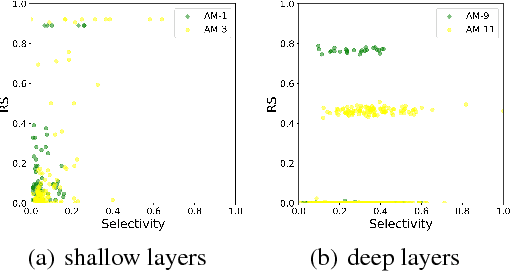
Understanding the internal representations of deep neural networks (DNNs) is crucal to explain their behavior. The interpretation of individual units, which are neurons in MLPs or convolution kernels in convolutional networks, has been paid much attention given their fundamental role. However, recent research (Morcos et al. 2018) presented a counterintuitive phenomenon, which suggests that an individual unit with high class selectivity, called interpretable units, has poor contributions to generalization of DNNs. In this work, we provide a new perspective to understand this counterintuitive phenomenon, which makes sense when we introduce Representative Substitution (RS). Instead of individually selective units with classes, the RS refers to the independence of a unit's representations in the same layer without any annotation. Our experiments demonstrate that interpretable units have high RS which are not critical to network's generalization. The RS provides new insights into the interpretation of DNNs and suggests that we need to focus on the independence and relationship of the representations.
* 4 pages, 6 figures