 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Importance of Single Directions via Representative Substitution
Paper and Code
Dec 06, 2018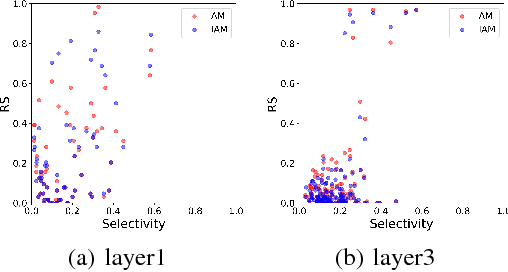
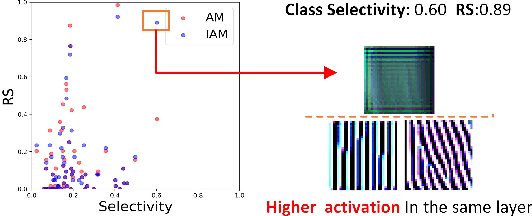
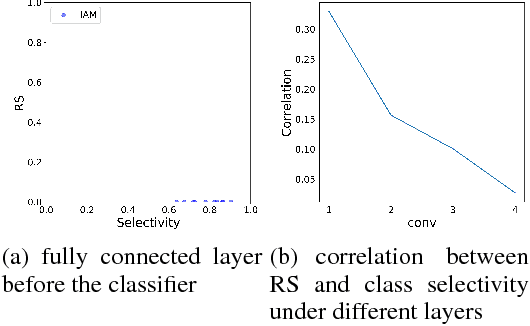
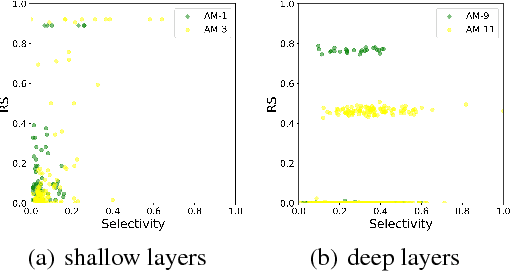
Understanding the internal representations of deep neural networks (DNNs) is crucal to explain their behavior. The interpretation of individual units, which are neurons in MLPs or convolution kernels in convolutional networks, has been paid much attention given their fundamental role. However, recent research (Morcos et al. 2018) presented a counterintuitive phenomenon, which suggests that an individual unit with high class selectivity, called interpretable units, has poor contributions to generalization of DNNs. In this work, we provide a new perspective to understand this counterintuitive phenomenon, which makes sense when we introduce Representative Substitution (RS). Instead of individually selective units with classes, the RS refers to the independence of a unit's representations in the same layer without any annotation. Our experiments demonstrate that interpretable units have high RS which are not critical to network's generalization. The RS provides new insights into the interpretation of DNNs and suggests that we need to focus on the independence and relationship of the representations.