 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Trojans Analysis and Mitigation from the Input Domain
Paper and Code
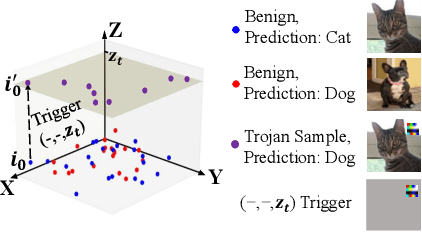
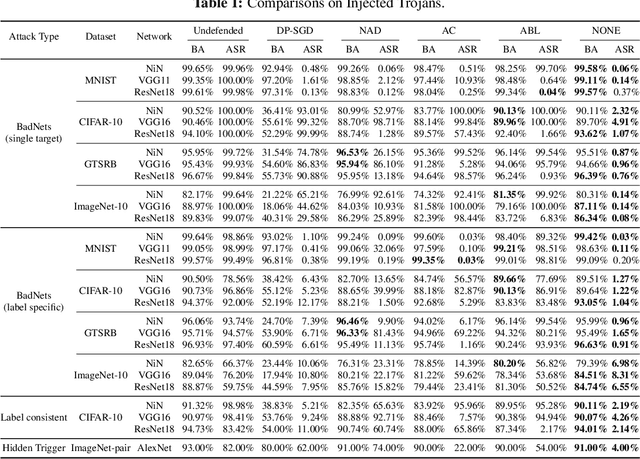
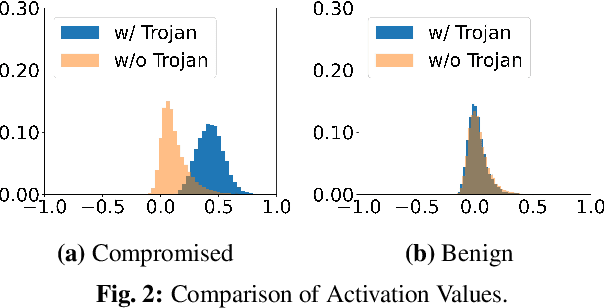
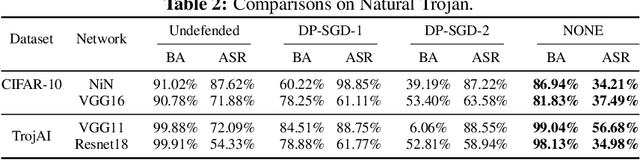
Deep Neural Networks (DNNs) can learn Trojans (or backdoors) from benign or poisoned data, which raises security concerns of using them. By exploiting such Trojans, the adversary can add a fixed input space perturbation to any given input to mislead the model predicting certain outputs (i.e., target labels). In this paper, we analyze such input space Trojans in DNNs, and propose a theory to explain the relationship of a model's decision regions and Trojans: a complete and accurate Trojan corresponds to a hyperplane decision region in the input domain. We provide a formal proof of this theory, and provide empirical evidence to support the theory and its relaxations. Based on our analysis, we design a novel training method that removes Trojans during training even on poisoned datasets, and evaluate our prototype on five datasets and five different attacks. Results show that our method outperforms existing solutions. Code: \url{https://anonymous.4open.science/r/NOLE-84C3}.