 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Task Offloading, Inference Optimization and UAV Trajectory Planning for Generative AI Empowered Intelligent Transportation Digital Twin
Apr 09, 2026To implement the intelligent transportation digital twin (ITDT), unmanned aerial vehicles (UAVs) are scheduled to process the sensing data from the roadside sensors. At this time, generative artificial intelligence (GAI) technologies such as diffusion models are deployed on the UAVs to transform the raw sensing data into the high-quality and valuable. Therefore, we propose the GAI-empowered ITDT. The dynamic processing of a set of diffusion model inference (DMI) tasks on the UAVs with dynamic mobility simultaneously influences the DT updating fidelity and delay. In this paper, we investigate a joint optimization problem of DMI task offloading, inference optimization and UAV trajectory planning as the system utility maximization (SUM) problem to address the fidelity-delay tradeoff for the GAI-empowered ITDT. To seek a solution to the problem under the network dynamics, we model the SUM problem as the heterogeneous-agent Markov decision process, and propose the sequential update-based heterogeneous-agent twin delayed deep deterministic policy gradient (SU-HATD3) algorithm, which can quickly learn a near-optimal solution. Numerical results demonstrate that compared with several baseline algorithms, the proposed algorithm has great advantages in improving the system utility and convergence rate.
Agentic AI for Embodied-enhanced Beam Prediction in Low-Altitude Economy Networks
Mar 12, 2026Millimeter-wave or terahertz communications can meet demands of low-altitude economy networks for high-throughput sensing and real-time decision making. However, high-frequency characteristics of wireless channels result in severe propagation loss and strong beam directivity, which make beam prediction challenging in highly mobile uncrewed aerial vehicles (UAV) scenarios. In this paper, we employ agentic AI to enable the transformation of mmWave base stations toward embodied intelligence. We innovatively design a multi-agent collaborative reasoning architecture for UAV-to-ground mmWave communications and propose a hybrid beam prediction model system based on bimodal data. The multi-agent architecture is designed to overcome the limited context window and weak controllability of large language model (LLM)-based reasoning by decomposing beam prediction into task analysis, solution planning, and completeness assessment. To align with the agentic reasoning process, a hybrid beam prediction model system is developed to process multimodal UAV data, including numeric mobility information and visual observations. The proposed hybrid model system integrates Mamba-based temporal modelling, convolutional visual encoding, and cross-attention-based multimodal fusion, and dynamically switches data-flow strategies under multi-agent guidance. Extensive simulations on a real UAV mmWave communication dataset demonstrate that proposed architecture and system achieve high prediction accuracy and robustness under diverse data conditions, with maximum top-1 accuracy reaching 96.57%.
Filling the Missing: Exploring Generative AI for Enhanced Federated Learning over Heterogeneous Mobile Edge Devices
Oct 29, 2023



Distributed Artificial Intelligence (AI) model training over mobile edge networks encounters significant challenges due to the data and resource heterogeneity of edge devices. The former hampers the convergence rate of the global model, while the latter diminishes the devices' resource utilization efficiency. In this paper, we propose a generative AI-empowered federated learning to address these challenges by leveraging the idea of FIlling the MIssing (FIMI) portion of local data. Specifically, FIMI can be considered as a resource-aware data augmentation method that effectively mitigates the data heterogeneity while ensuring efficient FL training. We first quantify the relationship between the training data amount and the learning performance. We then study the FIMI optimization problem with the objective of minimizing the device-side overall energy consumption subject to required learning performance constraints. The decomposition-based analysis and the cross-entropy searching method are leveraged to derive the solution, where each device is assigned suitable AI-synthesized data and resource utilization policy. Experiment results demonstrate that FIMI can save up to 50% of the device-side energy to achieve the target global test accuracy in comparison with the existing methods. Meanwhile, FIMI can significantly enhance the converged global accuracy under the non-independently-and-identically distribution (non-IID) data.
Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism
Jan 24, 2023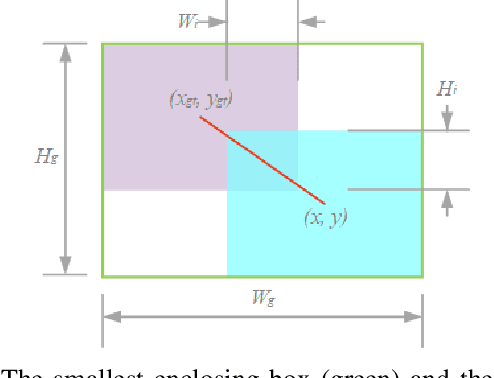
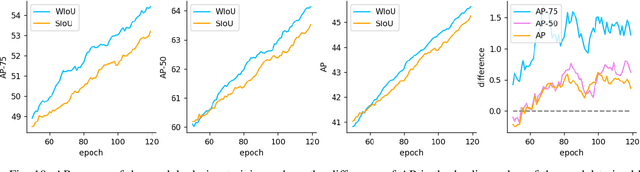

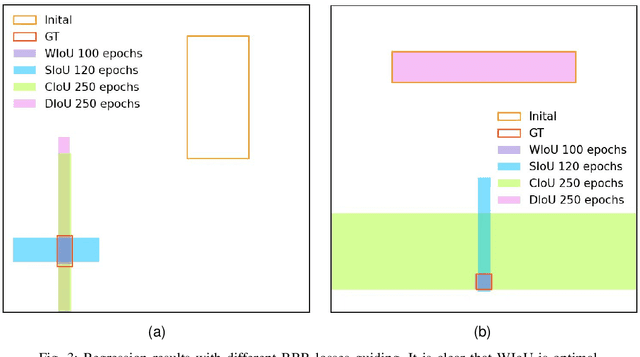
The loss function for bounding box regression (BBR) is essential to object detection. Its good definition will bring significant performance improvement to the model. Most existing works assume that the examples in the training data are high-quality and focus on strengthening the fitting ability of BBR loss. If we blindly strengthen BBR on low-quality examples, it will jeopardize localization performance. Focal-EIoU v1 was proposed to solve this problem, but due to its static focusing mechanism (FM), the potential of non-monotonic FM was not fully exploited. Based on this idea, we propose an IoU-based loss with a dynamic non-monotonic FM named Wise-IoU (WIoU). When WIoU is applied to the state-of-the-art real-time detector YOLOv7, the AP-75 on the MS-COCO dataset is improved from 53.03% to 54.50%.
AnycostFL: Efficient On-Demand Federated Learning over Heterogeneous Edge Devices
Jan 08, 2023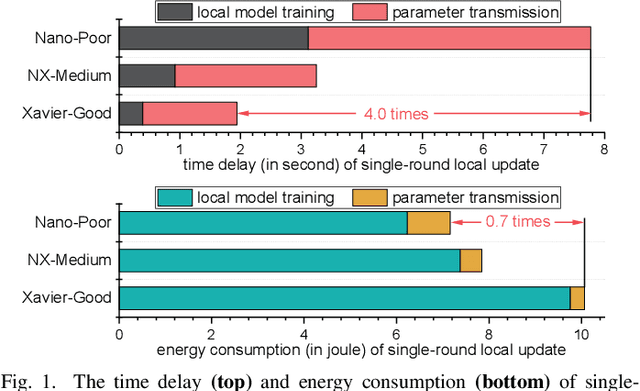
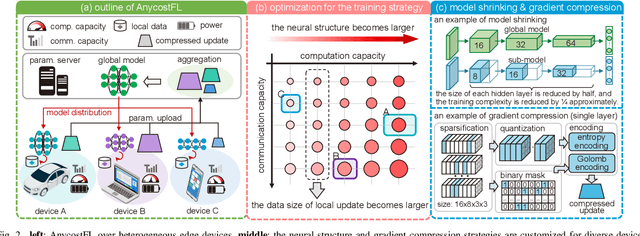
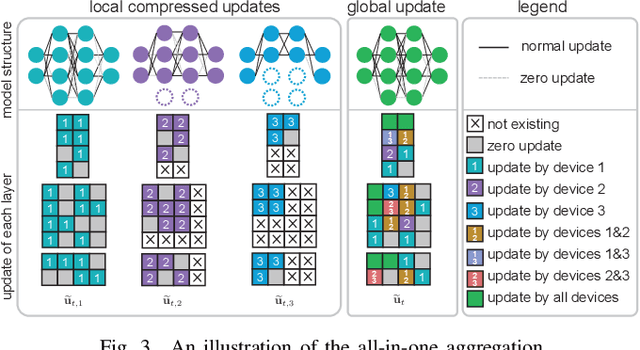
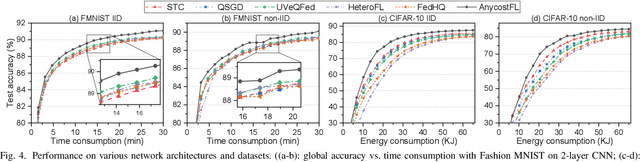
In this work, we investigate the challenging problem of on-demand federated learning (FL) over heterogeneous edge devices with diverse resource constraints. We propose a cost-adjustable FL framework, named AnycostFL, that enables diverse edge devices to efficiently perform local updates under a wide range of efficiency constraints. To this end, we design the model shrinking to support local model training with elastic computation cost, and the gradient compression to allow parameter transmission with dynamic communication overhead. An enhanced parameter aggregation is conducted in an element-wise manner to improve the model performance. Focusing on AnycostFL, we further propose an optimization design to minimize the global training loss with personalized latency and energy constraints. By revealing the theoretical insights of the convergence analysis, personalized training strategies are deduced for different devices to match their locally available resources. Experiment results indicate that, when compared to the state-of-the-art efficient FL algorithms, our learning framework can reduce up to 1.9 times of the training latency and energy consumption for realizing a reasonable global testing accuracy. Moreover, the results also demonstrate that, our approach significantly improves the converged global accuracy.
FedGreen: Federated Learning with Fine-Grained Gradient Compression for Green Mobile Edge Computing
Nov 11, 2021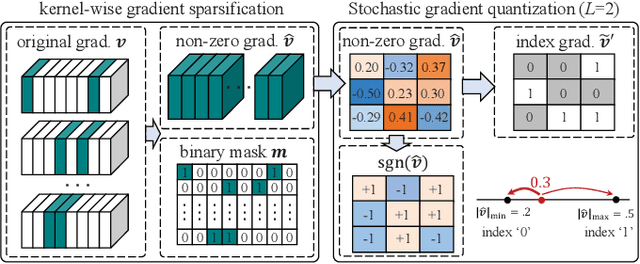
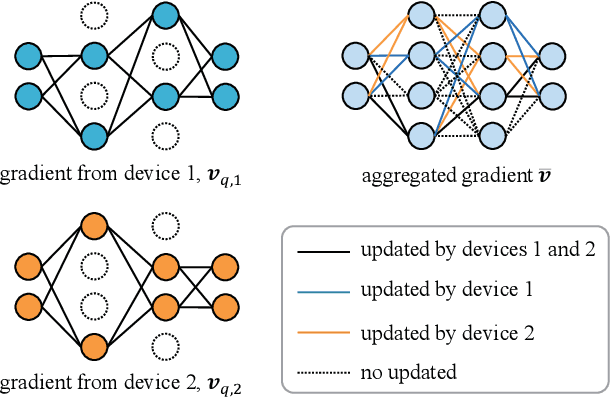
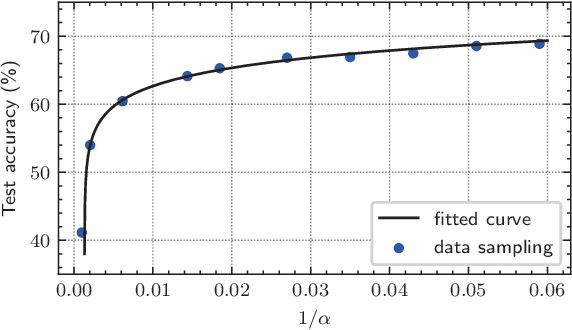
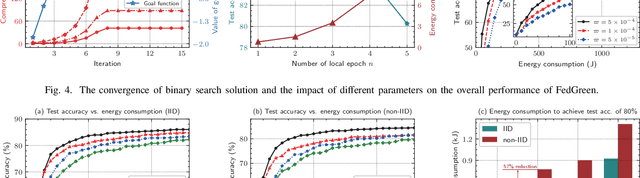
Federated learning (FL) enables devices in mobile edge computing (MEC) to collaboratively train a shared model without uploading the local data. Gradient compression may be applied to FL to alleviate the communication overheads but current FL with gradient compression still faces great challenges. To deploy green MEC, we propose FedGreen, which enhances the original FL with fine-grained gradient compression to efficiently control the total energy consumption of the devices. Specifically, we introduce the relevant operations including device-side gradient reduction and server-side element-wise aggregation to facilitate the gradient compression in FL. According to a public dataset, we investigate the contributions of the compressed local gradients with respect to different compression ratios. After that, we formulate and tackle a learning accuracy-energy efficiency tradeoff problem where the optimal compression ratio and computing frequency are derived for each device. Experiments results demonstrate that given the 80% test accuracy requirement, compared with the baseline schemes, FedGreen reduces at least 32% of the total energy consumption of the devices.
To Talk or to Work: Delay Efficient Federated Learning over Mobile Edge Devices
Nov 01, 2021
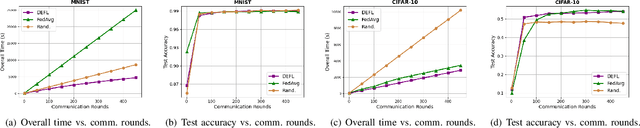
Federated learning (FL), an emerging distributed machine learning paradigm, in conflux with edge computing is a promising area with novel applications over mobile edge devices. In FL, since mobile devices collaborate to train a model based on their own data under the coordination of a central server by sharing just the model updates, training data is maintained private. However, without the central availability of data, computing nodes need to communicate the model updates often to attain convergence. Hence, the local computation time to create local model updates along with the time taken for transmitting them to and from the server result in a delay in the overall time. Furthermore, unreliable network connections may obstruct an efficient communication of these updates. To address these, in this paper, we propose a delay-efficient FL mechanism that reduces the overall time (consisting of both the computation and communication latencies) and communication rounds required for the model to converge. Exploring the impact of various parameters contributing to delay, we seek to balance the trade-off between wireless communication (to talk) and local computation (to work). We formulate a relation with overall time as an optimization problem and demonstrate the efficacy of our approach through extensive simulations.
FedParking: A Federated Learning based Parking Space Estimation with Parked Vehicle assisted Edge Computing
Oct 19, 2021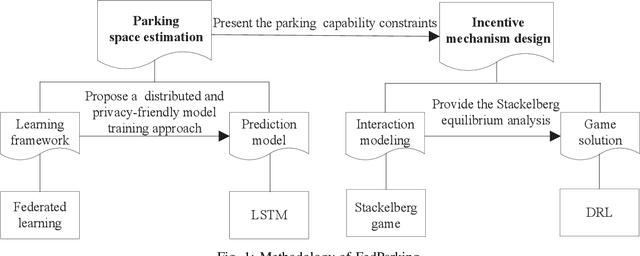
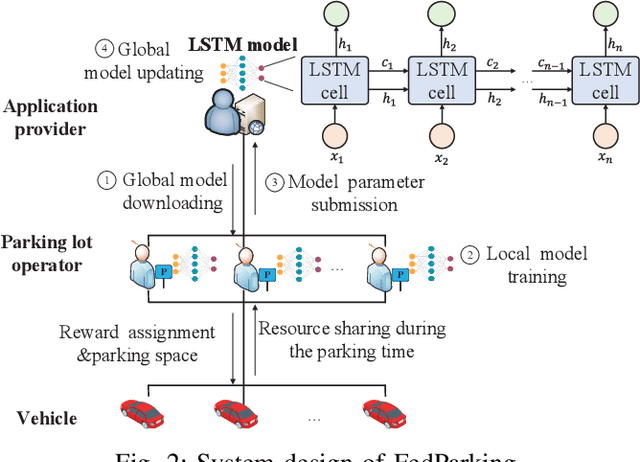
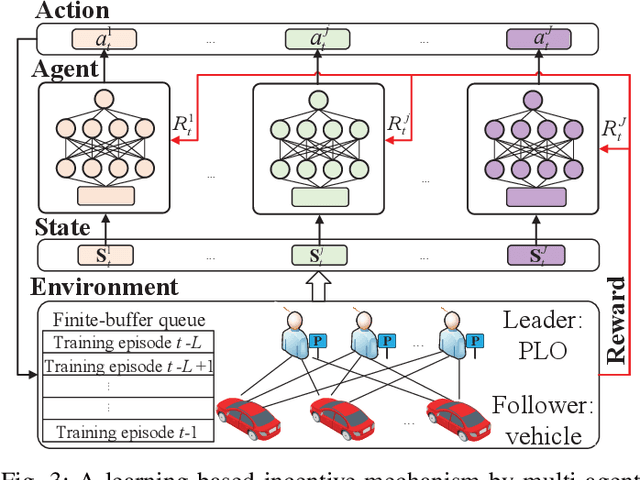
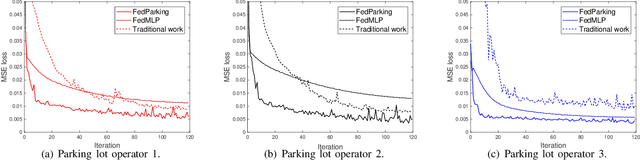
As a distributed learning approach, federated learning trains a shared learning model over distributed datasets while preserving the training data privacy. We extend the application of federated learning to parking management and introduce FedParking in which Parking Lot Operators (PLOs) collaborate to train a long short-term memory model for parking space estimation without exchanging the raw data. Furthermore, we investigate the management of Parked Vehicle assisted Edge Computing (PVEC) by FedParking. In PVEC, different PLOs recruit PVs as edge computing nodes for offloading services through an incentive mechanism, which is designed according to the computation demand and parking capacity constraints derived from FedParking. We formulate the interactions among the PLOs and vehicles as a multi-lead multi-follower Stackelberg game. Considering the dynamic arrivals of the vehicles and time-varying parking capacity constraints, we present a multi-agent deep reinforcement learning approach to gradually reach the Stackelberg equilibrium in a distributed yet privacy-preserving manner. Finally, numerical results are provided to demonstrate the effectiveness and efficiency of our scheme.
Evaluation of Inference Attack Models for Deep Learning on Medical Data
Oct 31, 2020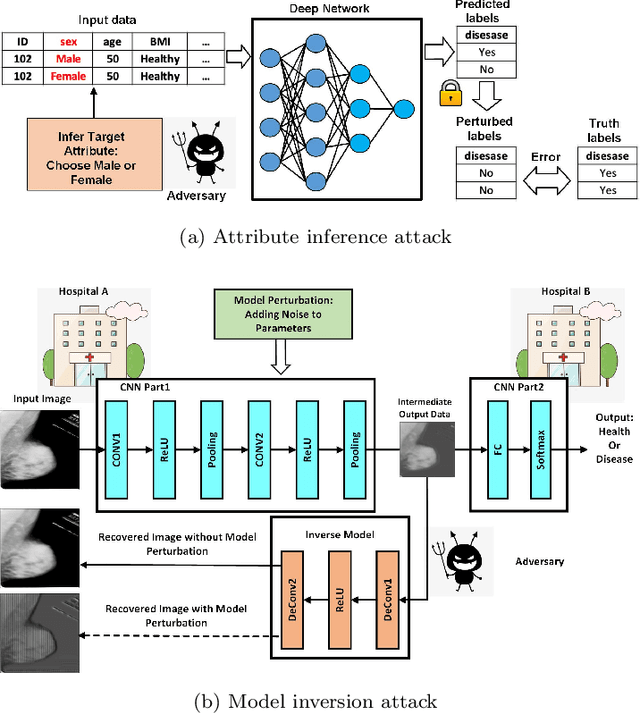
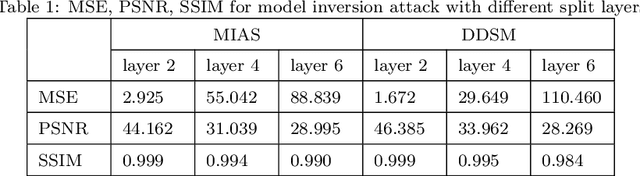
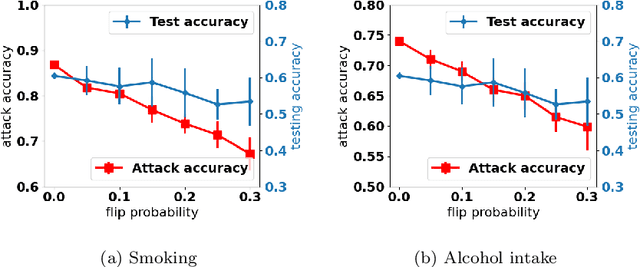
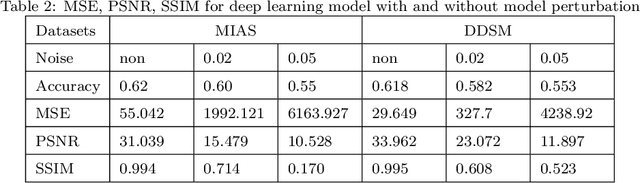
Deep learning has attracted broad interest in healthcare and medical communities. However, there has been little research into the privacy issues created by deep networks trained for medical applications. Recently developed inference attack algorithms indicate that images and text records can be reconstructed by malicious parties that have the ability to query deep networks. This gives rise to the concern that medical images and electronic health records containing sensitive patient information are vulnerable to these attacks. This paper aims to attract interest from researchers in the medical deep learning community to this important problem. We evaluate two prominent inference attack models, namely, attribute inference attack and model inversion attack. We show that they can reconstruct real-world medical images and clinical reports with high fidelity. We then investigate how to protect patients' privacy using defense mechanisms, such as label perturbation and model perturbation. We provide a comparison of attack results between the original and the medical deep learning models with defenses. The experimental evaluations show that our proposed defense approaches can effectively reduce the potential privacy leakage of medical deep learning from the inference attacks.
Differentially Private and Fair Classification via Calibrated Functional Mechanism
Jan 14, 2020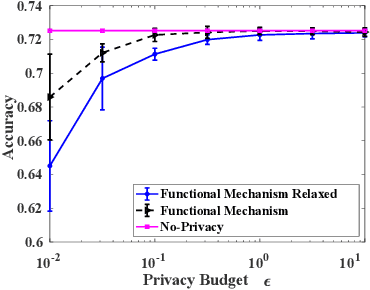
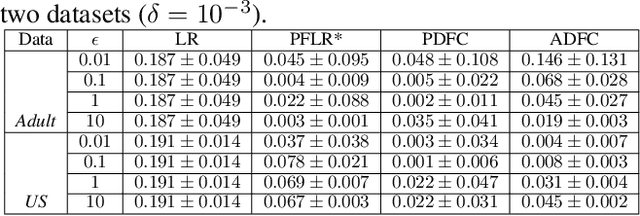
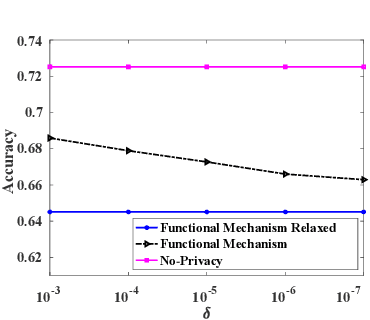
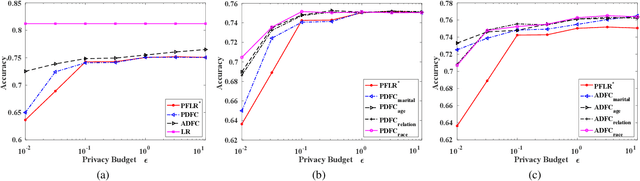
Machine learning is increasingly becoming a powerful tool to make decisions in a wide variety of applications, such as medical diagnosis and autonomous driving. Privacy concerns related to the training data and unfair behaviors of some decisions with regard to certain attributes (e.g., sex, race) are becoming more critical. Thus, constructing a fair machine learning model while simultaneously providing privacy protection becomes a challenging problem. In this paper, we focus on the design of classification model with fairness and differential privacy guarantees by jointly combining functional mechanism and decision boundary fairness. In order to enforce $\epsilon$-differential privacy and fairness, we leverage the functional mechanism to add different amounts of Laplace noise regarding different attributes to the polynomial coefficients of the objective function in consideration of fairness constraint. We further propose an utility-enhancement scheme, called relaxed functional mechanism by adding Gaussian noise instead of Laplace noise, hence achieving $(\epsilon,\delta)$-differential privacy. Based on the relaxed functional mechanism, we can design $(\epsilon,\delta)$-differentially private and fair classification model. Moreover, our theoretical analysis and empirical results demonstrate that our two approaches achieve both fairness and differential privacy while preserving good utility and outperform the state-of-the-art algorithms.