 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEve Said Yes: AirBone Authentication for Head-Wearable Smart Voice Assistant
Sep 26, 2023



Recent advances in machine learning and natural language processing have fostered the enormous prosperity of smart voice assistants and their services, e.g., Alexa, Google Home, Siri, etc. However, voice spoofing attacks are deemed to be one of the major challenges of voice control security, and never stop evolving such as deep-learning-based voice conversion and speech synthesis techniques. To solve this problem outside the acoustic domain, we focus on head-wearable devices, such as earbuds and virtual reality (VR) headsets, which are feasible to continuously monitor the bone-conducted voice in the vibration domain. Specifically, we identify that air and bone conduction (AC/BC) from the same vocalization are coupled (or concurrent) and user-level unique, which makes them suitable behavior and biometric factors for multi-factor authentication (MFA). The legitimate user can defeat acoustic domain and even cross-domain spoofing samples with the proposed two-stage AirBone authentication. The first stage answers \textit{whether air and bone conduction utterances are time domain consistent (TC)} and the second stage runs \textit{bone conduction speaker recognition (BC-SR)}. The security level is hence increased for two reasons: (1) current acoustic attacks on smart voice assistants cannot affect bone conduction, which is in the vibration domain; (2) even for advanced cross-domain attacks, the unique bone conduction features can detect adversary's impersonation and machine-induced vibration. Finally, AirBone authentication has good usability (the same level as voice authentication) compared with traditional MFA and those specially designed to enhance smart voice security. Our experimental results show that the proposed AirBone authentication is usable and secure, and can be easily equipped by commercial off-the-shelf head wearables with good user experience.
To Talk or to Work: Delay Efficient Federated Learning over Mobile Edge Devices
Nov 01, 2021
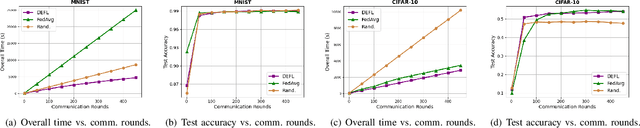
Federated learning (FL), an emerging distributed machine learning paradigm, in conflux with edge computing is a promising area with novel applications over mobile edge devices. In FL, since mobile devices collaborate to train a model based on their own data under the coordination of a central server by sharing just the model updates, training data is maintained private. However, without the central availability of data, computing nodes need to communicate the model updates often to attain convergence. Hence, the local computation time to create local model updates along with the time taken for transmitting them to and from the server result in a delay in the overall time. Furthermore, unreliable network connections may obstruct an efficient communication of these updates. To address these, in this paper, we propose a delay-efficient FL mechanism that reduces the overall time (consisting of both the computation and communication latencies) and communication rounds required for the model to converge. Exploring the impact of various parameters contributing to delay, we seek to balance the trade-off between wireless communication (to talk) and local computation (to work). We formulate a relation with overall time as an optimization problem and demonstrate the efficacy of our approach through extensive simulations.
Towards Energy Efficient Federated Learning over 5G+ Mobile Devices
Jan 13, 2021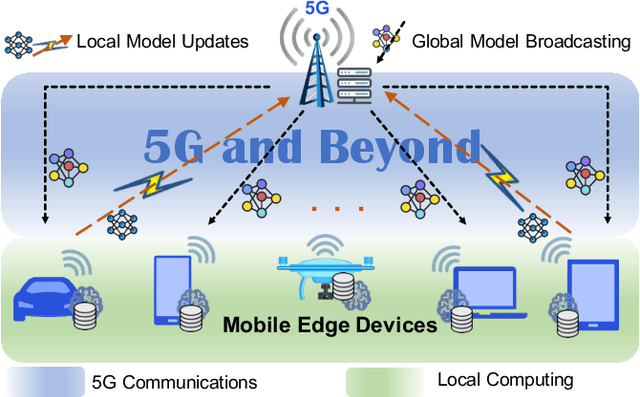
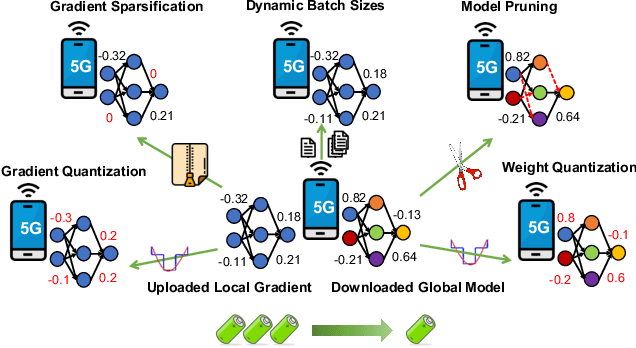
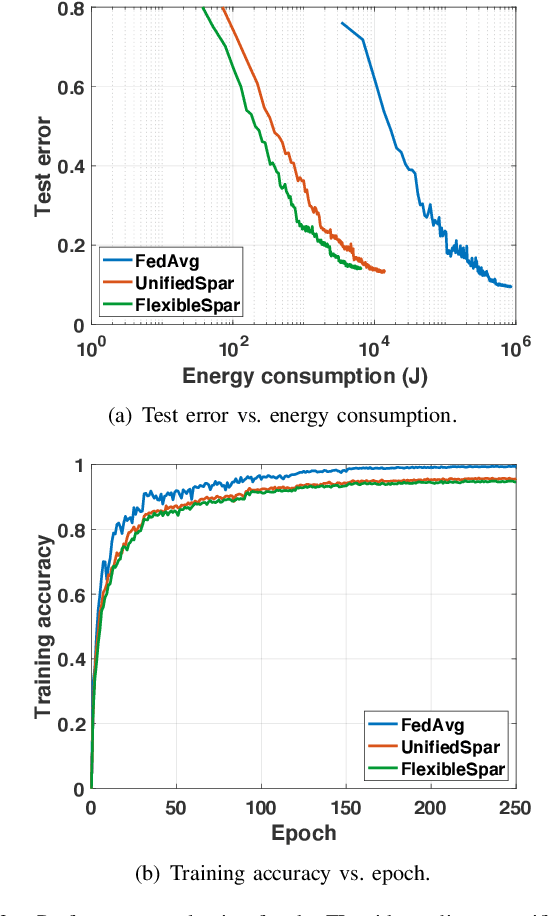
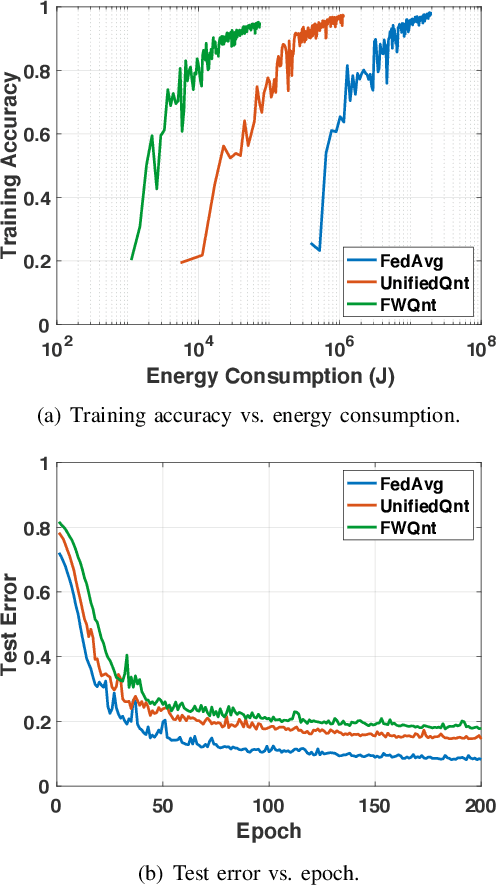
The continuous convergence of machine learning algorithms, 5G and beyond (5G+) wireless communications, and artificial intelligence (AI) hardware implementation hastens the birth of federated learning (FL) over 5G+ mobile devices, which pushes AI functions to mobile devices and initiates a new era of on-device AI applications. Despite the remarkable progress made in FL, huge energy consumption is one of the most significant obstacles restricting the development of FL over battery-constrained 5G+ mobile devices. To address this issue, in this paper, we investigate how to develop energy efficient FL over 5G+ mobile devices by making a trade-off between energy consumption for "working" (i.e., local computing) and that for "talking" (i.e., wireless communications) in order to boost the overall energy efficiency. Specifically, we first examine energy consumption models for graphics processing unit (GPU) computation and wireless transmissions. Then, we overview the state of the art of integrating FL procedure with energy-efficient learning techniques (e.g., gradient sparsification, weight quantization, pruning, etc.). Finally, we present several potential future research directions for FL over 5G+ mobile devices from the perspective of energy efficiency.