 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Adaptive SwiGLU for Mixture-of-Experts
May 30, 2026SwiGLU has become a standard gated activation in modern Transformer MLPs, yet its gate sharpness -- the smoothness and selectivity of the gating function -- is typically fixed throughout training. In this work, we propose Confidence-Aware SwiGLU ($κ$-SwiGLU), a variant of SwiGLU for Mixture-of-Experts (MoE) models that adjusts expert gate sharpness according to token-level routing confidence. Specifically, $κ$-SwiGLU parameterizes the SiLU gate sharpness coefficient as a learnable function of the router logit, enabling each expert gate unit to interpolate between smooth, broadly active gating and sharp, selective gating. We evaluate $κ$-SwiGLU on the FineWeb-Edu dataset across MoE Transformer models ranging from 8 to 28 layers. Across these settings, $κ$-SwiGLU improves mean CORE performance while adding negligible parameters and incurring only a small computational overhead, demonstrating that confidence-aware gate sharpness is a promising mechanism for improving MoE MLPs. The code is available at https://github.com/askerlee/kappa-swiglu.
Structured Semantic Cloaking for Jailbreak Attacks on Large Language Models
Mar 17, 2026Modern LLMs employ safety mechanisms that extend beyond surface-level input filtering to latent semantic representations and generation-time reasoning, enabling them to recover obfuscated malicious intent during inference and refuse accordingly, and rendering many surface-level obfuscation jailbreak attacks ineffective. We propose Structured Semantic Cloaking (S2C), a novel multi-dimensional jailbreak attack framework that manipulates how malicious semantic intent is reconstructed during model inference. S2C strategically distributes and reshapes semantic cues such that full intent consolidation requires multi-step inference and long-range co-reference resolution within deeper latent representations. The framework comprises three complementary mechanisms: (1) Contextual Reframing, which embeds the request within a plausible high-stakes scenario to bias the model toward compliance; (2) Content Fragmentation, which disperses the semantic signature of the request across disjoint prompt segments; and (3) Clue-Guided Camouflage, which disguises residual semantic cues while embedding recoverable markers that guide output generation. By delaying and restructuring semantic consolidation, S2C degrades safety triggers that depend on coherent or explicitly reconstructed malicious intent at decoding time, while preserving sufficient instruction recoverability for functional output generation. We evaluate S2C across multiple open-source and proprietary LLMs using HarmBench and JBB-Behaviors, where it improves Attack Success Rate (ASR) by 12.4% and 9.7%, respectively, over the current SOTA. Notably, S2C achieves substantial gains on GPT-5-mini, outperforming the strongest baseline by 26% on JBB-Behaviors. We also analyse which combinations perform best against broad families of models, and characterise the trade-off between the extent of obfuscation versus input recoverability on jailbreak success.
Graph Federated Learning for Personalized Privacy Recommendation
Aug 08, 2025Federated recommendation systems (FedRecs) have gained significant attention for providing privacy-preserving recommendation services. However, existing FedRecs assume that all users have the same requirements for privacy protection, i.e., they do not upload any data to the server. The approaches overlook the potential to enhance the recommendation service by utilizing publicly available user data. In real-world applications, users can choose to be private or public. Private users' interaction data is not shared, while public users' interaction data can be shared. Inspired by the issue, this paper proposes a novel Graph Federated Learning for Personalized Privacy Recommendation (GFed-PP) that adapts to different privacy requirements while improving recommendation performance. GFed-PP incorporates the interaction data of public users to build a user-item interaction graph, which is then used to form a user relationship graph. A lightweight graph convolutional network (GCN) is employed to learn each user's user-specific personalized item embedding. To protect user privacy, each client learns the user embedding and the scoring function locally. Additionally, GFed-PP achieves optimization of the federated recommendation framework through the initialization of item embedding on clients and the aggregation of the user relationship graph on the server. Experimental results demonstrate that GFed-PP significantly outperforms existing methods for five datasets, offering superior recommendation accuracy without compromising privacy. This framework provides a practical solution for accommodating varying privacy preferences in federated recommendation systems.
Fine-tuning is Not Fine: Mitigating Backdoor Attacks in GNNs with Limited Clean Data
Jan 10, 2025



Graph Neural Networks (GNNs) have achieved remarkable performance through their message-passing mechanism. However, recent studies have highlighted the vulnerability of GNNs to backdoor attacks, which can lead the model to misclassify graphs with attached triggers as the target class. The effectiveness of recent promising defense techniques, such as fine-tuning or distillation, is heavily contingent on having comprehensive knowledge of the sufficient training dataset. Empirical studies have shown that fine-tuning methods require a clean dataset of 20% to reduce attack accuracy to below 25%, while distillation methods require a clean dataset of 15%. However, obtaining such a large amount of clean data is commonly impractical. In this paper, we propose a practical backdoor mitigation framework, denoted as GRAPHNAD, which can capture high-quality intermediate-layer representations in GNNs to enhance the distillation process with limited clean data. To achieve this, we address the following key questions: How to identify the appropriate attention representations in graphs for distillation? How to enhance distillation with limited data? By adopting the graph attention transfer method, GRAPHNAD can effectively align the intermediate-layer attention representations of the backdoored model with that of the teacher model, forcing the backdoor neurons to transform into benign ones. Besides, we extract the relation maps from intermediate-layer transformation and enforce the relation maps of the backdoored model to be consistent with that of the teacher model, thereby ensuring model accuracy while further reducing the influence of backdoors. Extensive experimental results show that by fine-tuning a teacher model with only 3% of the clean data, GRAPHNAD can reduce the attack success rate to below 5%.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


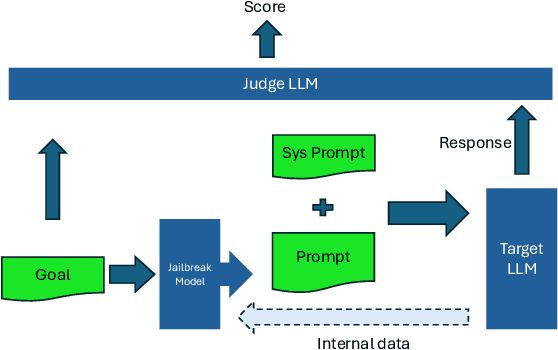
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
"No Matter What You Do!": Mitigating Backdoor Attacks in Graph Neural Networks
Oct 02, 2024



Recent studies have exposed that GNNs are vulnerable to several adversarial attacks, among which backdoor attack is one of the toughest. Similar to Deep Neural Networks (DNNs), backdoor attacks in GNNs lie in the fact that the attacker modifies a portion of graph data by embedding triggers and enforces the model to learn the trigger feature during the model training process. Despite the massive prior backdoor defense works on DNNs, defending against backdoor attacks in GNNs is largely unexplored, severely hindering the widespread application of GNNs in real-world tasks. To bridge this gap, we present GCleaner, the first backdoor mitigation method on GNNs. GCleaner can mitigate the presence of the backdoor logic within backdoored GNNs by reversing the backdoor learning procedure, aiming to restore the model performance to a level similar to that is directly trained on the original clean dataset. To achieve this objective, we ask: How to recover universal and hard backdoor triggers in GNNs? How to unlearn the backdoor trigger feature while maintaining the model performance? We conduct the graph trigger recovery via the explanation method to identify optimal trigger locations, facilitating the search of universal and hard backdoor triggers in the feature space of the backdoored model through maximal similarity. Subsequently, we introduce the backdoor unlearning mechanism, which combines knowledge distillation and gradient-based explainable knowledge for fine-grained backdoor erasure. Extensive experimental evaluations on four benchmark datasets demonstrate that GCleaner can reduce the backdoor attack success rate to 10% with only 1% of clean data, and has almost negligible degradation in model performance, which far outperforms the state-of-the-art (SOTA) defense methods.
A Systematic Literature Review on Explainability for Machine/Deep Learning-based Software Engineering Research
Jan 26, 2024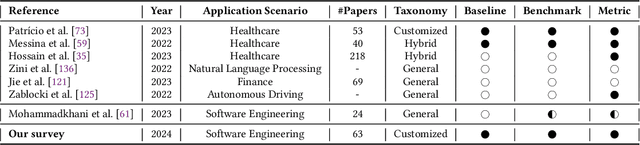
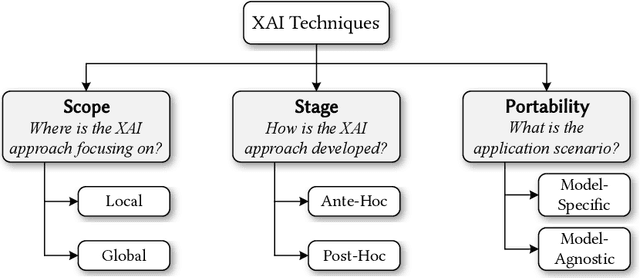
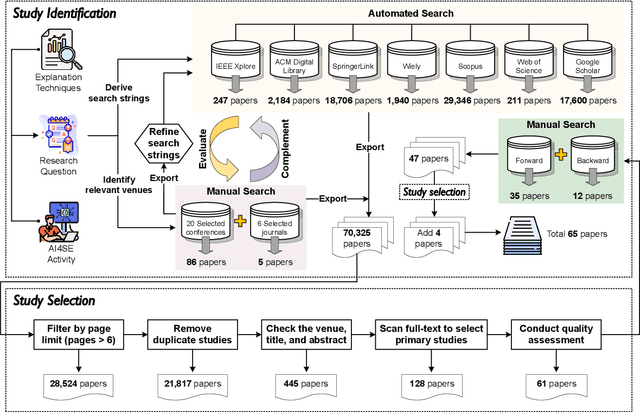
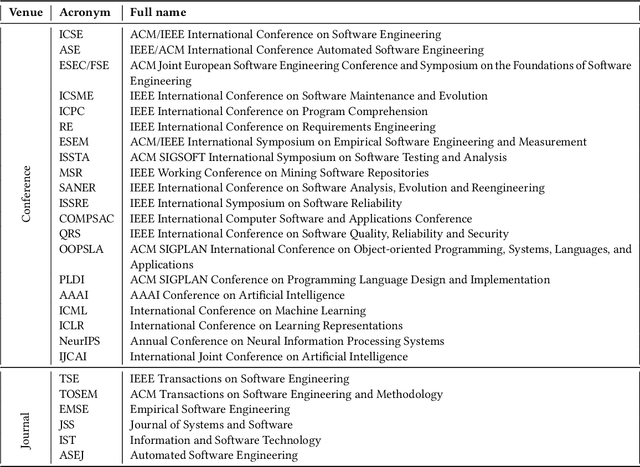
The remarkable achievements of Artificial Intelligence (AI) algorithms, particularly in Machine Learning (ML) and Deep Learning (DL), have fueled their extensive deployment across multiple sectors, including Software Engineering (SE). However, due to their black-box nature, these promising AI-driven SE models are still far from being deployed in practice. This lack of explainability poses unwanted risks for their applications in critical tasks, such as vulnerability detection, where decision-making transparency is of paramount importance. This paper endeavors to elucidate this interdisciplinary domain by presenting a systematic literature review of approaches that aim to improve the explainability of AI models within the context of SE. The review canvasses work appearing in the most prominent SE & AI conferences and journals, and spans 63 papers across 21 unique SE tasks. Based on three key Research Questions (RQs), we aim to (1) summarize the SE tasks where XAI techniques have shown success to date; (2) classify and analyze different XAI techniques; and (3) investigate existing evaluation approaches. Based on our findings, we identified a set of challenges remaining to be addressed in existing studies, together with a roadmap highlighting potential opportunities we deemed appropriate and important for future work.
Unraveling Feature Extraction Mechanisms in Neural Networks
Oct 26, 2023



The underlying mechanism of neural networks in capturing precise knowledge has been the subject of consistent research efforts. In this work, we propose a theoretical approach based on Neural Tangent Kernels (NTKs) to investigate such mechanisms. Specifically, considering the infinite network width, we hypothesize the learning dynamics of target models may intuitively unravel the features they acquire from training data, deepening our insights into their internal mechanisms. We apply our approach to several fundamental models and reveal how these models leverage statistical features during gradient descent and how they are integrated into final decisions. We also discovered that the choice of activation function can affect feature extraction. For instance, the use of the \textit{ReLU} activation function could potentially introduce a bias in features, providing a plausible explanation for its replacement with alternative functions in recent pre-trained language models. Additionally, we find that while self-attention and CNN models may exhibit limitations in learning n-grams, multiplication-based models seem to excel in this area. We verify these theoretical findings through experiments and find that they can be applied to analyze language modeling tasks, which can be regarded as a special variant of classification. Our contributions offer insights into the roles and capacities of fundamental components within large language models, thereby aiding the broader understanding of these complex systems.
Implicit N-grams Induced by Recurrence
May 05, 2022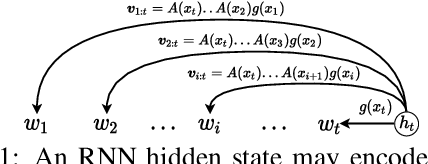


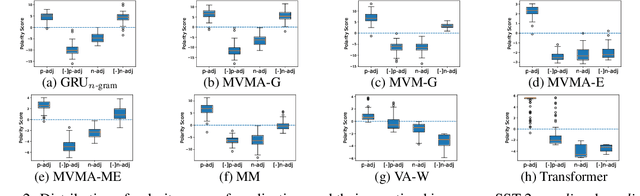
Although self-attention based models such as Transformers have achieved remarkable successes on natural language processing (NLP) tasks, recent studies reveal that they have limitations on modeling sequential transformations (Hahn, 2020), which may prompt re-examinations of recurrent neural networks (RNNs) that demonstrated impressive results on handling sequential data. Despite many prior attempts to interpret RNNs, their internal mechanisms have not been fully understood, and the question on how exactly they capture sequential features remains largely unclear. In this work, we present a study that shows there actually exist some explainable components that reside within the hidden states, which are reminiscent of the classical n-grams features. We evaluated such extracted explainable features from trained RNNs on downstream sentiment analysis tasks and found they could be used to model interesting linguistic phenomena such as negation and intensification. Furthermore, we examined the efficacy of using such n-gram components alone as encoders on tasks such as sentiment analysis and language modeling, revealing they could be playing important roles in contributing to the overall performance of RNNs. We hope our findings could add interpretability to RNN architectures, and also provide inspirations for proposing new architectures for sequential data.