 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Black Box: Theory and Mechanism of Large Language Models
Jan 06, 2026The rapid emergence of Large Language Models (LLMs) has precipitated a profound paradigm shift in Artificial Intelligence, delivering monumental engineering successes that increasingly impact modern society. However, a critical paradox persists within the current field: despite the empirical efficacy, our theoretical understanding of LLMs remains disproportionately nascent, forcing these systems to be treated largely as ``black boxes''. To address this theoretical fragmentation, this survey proposes a unified lifecycle-based taxonomy that organizes the research landscape into six distinct stages: Data Preparation, Model Preparation, Training, Alignment, Inference, and Evaluation. Within this framework, we provide a systematic review of the foundational theories and internal mechanisms driving LLM performance. Specifically, we analyze core theoretical issues such as the mathematical justification for data mixtures, the representational limits of various architectures, and the optimization dynamics of alignment algorithms. Moving beyond current best practices, we identify critical frontier challenges, including the theoretical limits of synthetic data self-improvement, the mathematical bounds of safety guarantees, and the mechanistic origins of emergent intelligence. By connecting empirical observations with rigorous scientific inquiry, this work provides a structured roadmap for transitioning LLM development from engineering heuristics toward a principled scientific discipline.
LoRA-Null: Low-Rank Adaptation via Null Space for Large Language Models
Mar 04, 2025Low-Rank Adaptation (LoRA) is the leading parameter-efficient fine-tuning method for Large Language Models (LLMs). However, the fine-tuned LLMs encounter the issue of catastrophic forgetting of the pre-trained world knowledge. To address this issue, inspired by theoretical insights of null space, we propose LoRA-Null, i.e., Low-Rank Adaptation via null space, which builds adapters initialized from the null space of the pre-trained knowledge activation. Concretely, we randomly collect a few data samples and capture their activations after passing through the LLM layer. We perform Singular Value Decomposition on the input activations to obtain their null space. We use the projection of the pre-trained weights onto the null space as the initialization for adapters. Experimental results demonstrate that this initialization approach can effectively preserve the original pre-trained world knowledge of the LLMs during fine-tuning. Additionally, if we freeze the values of the down-projection matrices during fine-tuning, it achieves even better preservation of the pre-trained world knowledge. LoRA-Null effectively preserves pre-trained world knowledge while maintaining strong fine-tuning performance, as validated by extensive experiments on LLaMA series (LLaMA2, LLaMA3, LLaMA3.1, and LLaMA3.2) across Code, Math, and Instruction Following tasks. We also provide a theoretical guarantee for the capacity of LoRA-Null to retain pre-trained knowledge. Code is in https://github.com/HungerPWAY/LoRA-Null.
ADePT: Adaptive Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning
Jan 06, 2025



Prompt Tuning (PT) enables the adaptation of Pre-trained Large Language Models (PLMs) to downstream tasks by optimizing a small amount of soft virtual tokens, which are prepended to the input token embeddings. Recently, Decomposed Prompt Tuning (DePT) has demonstrated superior adaptation capabilities by decomposing the soft prompt into a shorter soft prompt and a pair of low-rank matrices. The product of the pair of low-rank matrices is added to the input token embeddings to offset them. Additionally, DePT achieves faster inference compared to PT due to the shorter soft prompt. However, in this paper, we find that the position-based token embedding offsets of DePT restricts its ability to generalize across diverse model inputs, and that the shared embedding offsets across many token embeddings result in sub-optimization. To tackle these issues, we introduce \textbf{A}daptive \textbf{De}composed \textbf{P}rompt \textbf{T}uning (ADePT), which is composed of a short soft prompt and a shallow token-shared feed-forward neural network. ADePT utilizes the token-shared feed-forward neural network to learn the embedding offsets for each token, enabling adaptive embedding offsets that vary according to the model input and better optimization of token embedding offsets. This enables ADePT to achieve superior adaptation performance without requiring more inference time or additional trainable parameters compared to vanilla PT and its variants. In comprehensive experiments across 23 natural language processing (NLP) tasks and 4 typical PLMs of different scales, we show that ADePT consistently surpasses the leading parameter-efficient fine-tuning (PEFT) methods, and even outperforms the full fine-tuning baseline in certain scenarios. Code is available at \url{https://github.com/HungerPWAY/ADePT}.
Fine-grained Iterative Attention Network for TemporalLanguage Localization in Videos
Aug 06, 2020
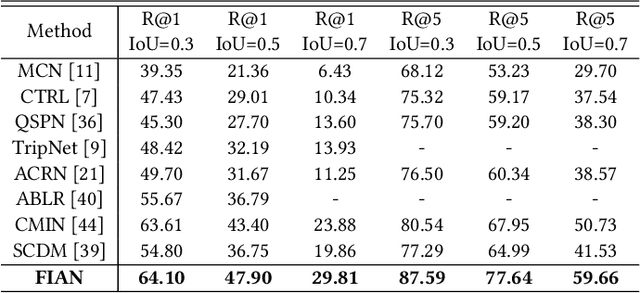
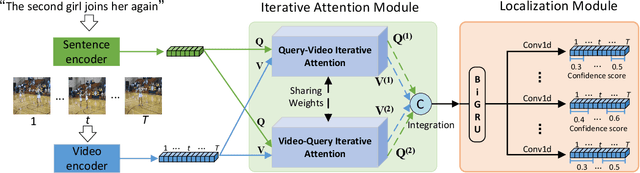
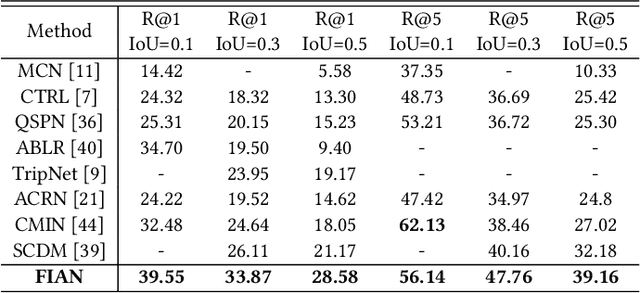
Temporal language localization in videos aims to ground one video segment in an untrimmed video based on a given sentence query. To tackle this task, designing an effective model to extract ground-ing information from both visual and textual modalities is crucial. However, most previous attempts in this field only focus on unidirectional interactions from video to query, which emphasizes which words to listen and attends to sentence information via vanilla soft attention, but clues from query-by-video interactions implying where to look are not taken into consideration. In this paper, we propose a Fine-grained Iterative Attention Network (FIAN) that consists of an iterative attention module for bilateral query-video in-formation extraction. Specifically, in the iterative attention module, each word in the query is first enhanced by attending to each frame in the video through fine-grained attention, then video iteratively attends to the integrated query. Finally, both video and query information is utilized to provide robust cross-modal representation for further moment localization. In addition, to better predict the target segment, we propose a content-oriented localization strategy instead of applying recent anchor-based localization. We evaluate the proposed method on three challenging public benchmarks: Ac-tivityNet Captions, TACoS, and Charades-STA. FIAN significantly outperforms the state-of-the-art approaches.