 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA large-scale nanocrystal database with aligned synthesis and properties enabling generative inverse design
Jan 04, 2026The synthesis of nanocrystals has been highly dependent on trial-and-error, due to the complex correlation between synthesis parameters and physicochemical properties. Although deep learning offers a potential methodology to achieve generative inverse design, it is still hindered by the scarcity of high-quality datasets that align nanocrystal synthesis routes with their properties. Here, we present the construction of a large-scale, aligned Nanocrystal Synthesis-Property (NSP) database and demonstrate its capability for generative inverse design. To extract structured synthesis routes and their corresponding product properties from literature, we develop NanoExtractor, a large language model (LLM) enhanced by well-designed augmentation strategies. NanoExtractor is validated against human experts, achieving a weighted average score of 88% on the test set, significantly outperforming chemistry-specialized (3%) and general-purpose LLMs (38%). The resulting NSP database contains nearly 160,000 aligned entries and serves as training data for our NanoDesigner, an LLM for inverse synthesis design. The generative capability of NanoDesigner is validated through the successful design of viable synthesis routes for both well-established PbSe nanocrystals and rarely reported MgF2 nanocrystals. Notably, the model recommends a counter-intuitive, non-stoichiometric precursor ratio (1:1) for MgF2 nanocrystals, which is experimentally confirmed as critical for suppressing byproducts. Our work bridges the gap between unstructured literature and data-driven synthesis, and also establishes a powerful human-AI collaborative paradigm for accelerating nanocrystal discovery.
RobuSTereo: Robust Zero-Shot Stereo Matching under Adverse Weather
Jul 02, 2025Learning-based stereo matching models struggle in adverse weather conditions due to the scarcity of corresponding training data and the challenges in extracting discriminative features from degraded images. These limitations significantly hinder zero-shot generalization to out-of-distribution weather conditions. In this paper, we propose \textbf{RobuSTereo}, a novel framework that enhances the zero-shot generalization of stereo matching models under adverse weather by addressing both data scarcity and feature extraction challenges. First, we introduce a diffusion-based simulation pipeline with a stereo consistency module, which generates high-quality stereo data tailored for adverse conditions. By training stereo matching models on our synthetic datasets, we reduce the domain gap between clean and degraded images, significantly improving the models' robustness to unseen weather conditions. The stereo consistency module ensures structural alignment across synthesized image pairs, preserving geometric integrity and enhancing depth estimation accuracy. Second, we design a robust feature encoder that combines a specialized ConvNet with a denoising transformer to extract stable and reliable features from degraded images. The ConvNet captures fine-grained local structures, while the denoising transformer refines global representations, effectively mitigating the impact of noise, low visibility, and weather-induced distortions. This enables more accurate disparity estimation even under challenging visual conditions. Extensive experiments demonstrate that \textbf{RobuSTereo} significantly improves the robustness and generalization of stereo matching models across diverse adverse weather scenarios.
Flow-Anything: Learning Real-World Optical Flow Estimation from Large-Scale Single-view Images
Jun 09, 2025Optical flow estimation is a crucial subfield of computer vision, serving as a foundation for video tasks. However, the real-world robustness is limited by animated synthetic datasets for training. This introduces domain gaps when applied to real-world applications and limits the benefits of scaling up datasets. To address these challenges, we propose \textbf{Flow-Anything}, a large-scale data generation framework designed to learn optical flow estimation from any single-view images in the real world. We employ two effective steps to make data scaling-up promising. First, we convert a single-view image into a 3D representation using advanced monocular depth estimation networks. This allows us to render optical flow and novel view images under a virtual camera. Second, we develop an Object-Independent Volume Rendering module and a Depth-Aware Inpainting module to model the dynamic objects in the 3D representation. These two steps allow us to generate realistic datasets for training from large-scale single-view images, namely \textbf{FA-Flow Dataset}. For the first time, we demonstrate the benefits of generating optical flow training data from large-scale real-world images, outperforming the most advanced unsupervised methods and supervised methods on synthetic datasets. Moreover, our models serve as a foundation model and enhance the performance of various downstream video tasks.
Boosting Zero-shot Stereo Matching using Large-scale Mixed Images Sources in the Real World
May 13, 2025Stereo matching methods rely on dense pixel-wise ground truth labels, which are laborious to obtain, especially for real-world datasets. The scarcity of labeled data and domain gaps between synthetic and real-world images also pose notable challenges. In this paper, we propose a novel framework, \textbf{BooSTer}, that leverages both vision foundation models and large-scale mixed image sources, including synthetic, real, and single-view images. First, to fully unleash the potential of large-scale single-view images, we design a data generation strategy combining monocular depth estimation and diffusion models to generate dense stereo matching data from single-view images. Second, to tackle sparse labels in real-world datasets, we transfer knowledge from monocular depth estimation models, using pseudo-mono depth labels and a dynamic scale- and shift-invariant loss for additional supervision. Furthermore, we incorporate vision foundation model as an encoder to extract robust and transferable features, boosting accuracy and generalization. Extensive experiments on benchmark datasets demonstrate the effectiveness of our approach, achieving significant improvements in accuracy over existing methods, particularly in scenarios with limited labeled data and domain shifts.
Relation-Guided Adversarial Learning for Data-free Knowledge Transfer
Dec 16, 2024Data-free knowledge distillation transfers knowledge by recovering training data from a pre-trained model. Despite the recent success of seeking global data diversity, the diversity within each class and the similarity among different classes are largely overlooked, resulting in data homogeneity and limited performance. In this paper, we introduce a novel Relation-Guided Adversarial Learning method with triplet losses, which solves the homogeneity problem from two aspects. To be specific, our method aims to promote both intra-class diversity and inter-class confusion of the generated samples. To this end, we design two phases, an image synthesis phase and a student training phase. In the image synthesis phase, we construct an optimization process to push away samples with the same labels and pull close samples with different labels, leading to intra-class diversity and inter-class confusion, respectively. Then, in the student training phase, we perform an opposite optimization, which adversarially attempts to reduce the distance of samples of the same classes and enlarge the distance of samples of different classes. To mitigate the conflict of seeking high global diversity and keeping inter-class confusing, we propose a focal weighted sampling strategy by selecting the negative in the triplets unevenly within a finite range of distance. RGAL shows significant improvement over previous state-of-the-art methods in accuracy and data efficiency. Besides, RGAL can be inserted into state-of-the-art methods on various data-free knowledge transfer applications. Experiments on various benchmarks demonstrate the effectiveness and generalizability of our proposed method on various tasks, specially data-free knowledge distillation, data-free quantization, and non-exemplar incremental learning. Our code is available at https://github.com/Sharpiless/RGAL.
Deep Learning Models for Colloidal Nanocrystal Synthesis
Dec 14, 2024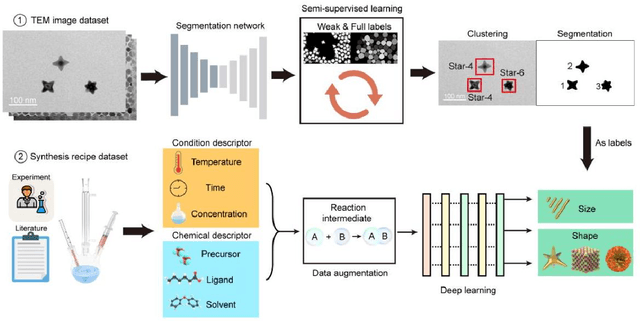
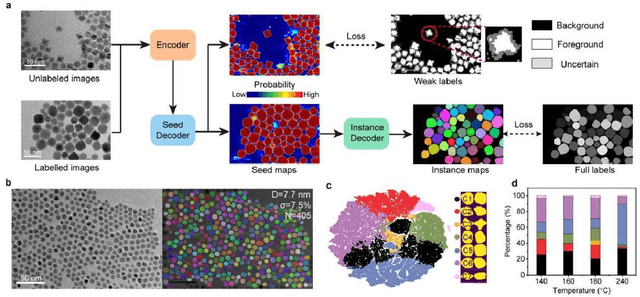
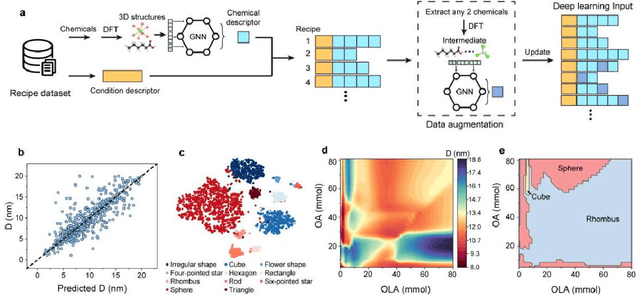
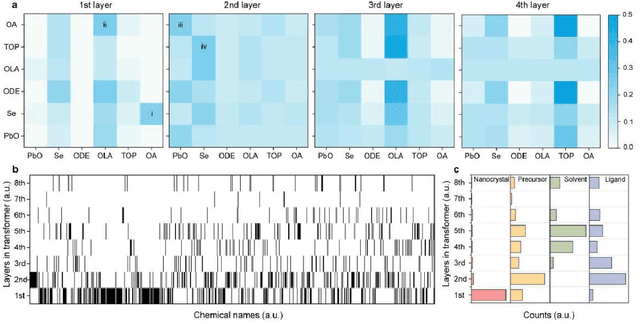
Colloidal synthesis of nanocrystals usually includes complex chemical reactions and multi-step crystallization processes. Despite the great success in the past 30 years, it remains challenging to clarify the correlations between synthetic parameters of chemical reaction and physical properties of nanocrystals. Here, we developed a deep learning-based nanocrystal synthesis model that correlates synthetic parameters with the final size and shape of target nanocrystals, using a dataset of 3500 recipes covering 348 distinct nanocrystal compositions. The size and shape labels were obtained from transmission electron microscope images using a segmentation model trained with a semi-supervised algorithm on a dataset comprising 1.2 million nanocrystals. By applying the reaction intermediate-based data augmentation method and elaborated descriptors, the synthesis model was able to predict nanocrystal's size with a mean absolute error of 1.39 nm, while reaching an 89% average accuracy for shape classification. The synthesis model shows knowledge transfer capabilities across different nanocrystals with inputs of new recipes. With that, the influence of chemicals on the final size of nanocrystals was further evaluated, revealing the importance order of nanocrystal composition, precursor or ligand, and solvent. Overall, the deep learning-based nanocrystal synthesis model offers a powerful tool to expedite the development of high-quality nanocrystals.
Mono2Stereo: Monocular Knowledge Transfer for Enhanced Stereo Matching
Nov 14, 2024



The generalization and performance of stereo matching networks are limited due to the domain gap of the existing synthetic datasets and the sparseness of GT labels in the real datasets. In contrast, monocular depth estimation has achieved significant advancements, benefiting from large-scale depth datasets and self-supervised strategies. To bridge the performance gap between monocular depth estimation and stereo matching, we propose leveraging monocular knowledge transfer to enhance stereo matching, namely Mono2Stereo. We introduce knowledge transfer with a two-stage training process, comprising synthetic data pre-training and real-world data fine-tuning. In the pre-training stage, we design a data generation pipeline that synthesizes stereo training data from monocular images. This pipeline utilizes monocular depth for warping and novel view synthesis and employs our proposed Edge-Aware (EA) inpainting module to fill in missing contents in the generated images. In the fine-tuning stage, we introduce a Sparse-to-Dense Knowledge Distillation (S2DKD) strategy encouraging the distributions of predictions to align with dense monocular depths. This strategy mitigates issues with edge blurring in sparse real-world labels and enhances overall consistency. Experimental results demonstrate that our pre-trained model exhibits strong zero-shot generalization capabilities. Furthermore, domain-specific fine-tuning using our pre-trained model and S2DKD strategy significantly increments in-domain performance. The code will be made available soon.
Camera-LiDAR Cross-modality Gait Recognition
Jul 03, 2024

Gait recognition is a crucial biometric identification technique. Camera-based gait recognition has been widely applied in both research and industrial fields. LiDAR-based gait recognition has also begun to evolve most recently, due to the provision of 3D structural information. However, in certain applications, cameras fail to recognize persons, such as in low-light environments and long-distance recognition scenarios, where LiDARs work well. On the other hand, the deployment cost and complexity of LiDAR systems limit its wider application. Therefore, it is essential to consider cross-modality gait recognition between cameras and LiDARs for a broader range of applications. In this work, we propose the first cross-modality gait recognition framework between Camera and LiDAR, namely CL-Gait. It employs a two-stream network for feature embedding of both modalities. This poses a challenging recognition task due to the inherent matching between 3D and 2D data, exhibiting significant modality discrepancy. To align the feature spaces of the two modalities, i.e., camera silhouettes and LiDAR points, we propose a contrastive pre-training strategy to mitigate modality discrepancy. To make up for the absence of paired camera-LiDAR data for pre-training, we also introduce a strategy for generating data on a large scale. This strategy utilizes monocular depth estimated from single RGB images and virtual cameras to generate pseudo point clouds for contrastive pre-training. Extensive experiments show that the cross-modality gait recognition is very challenging but still contains potential and feasibility with our proposed model and pre-training strategy. To the best of our knowledge, this is the first work to address cross-modality gait recognition.
CascadeV-Det: Cascade Point Voting for 3D Object Detection
Jan 15, 2024Anchor-free object detectors are highly efficient in performing point-based prediction without the need for extra post-processing of anchors. However, different from the 2D grids, the 3D points used in these detectors are often far from the ground truth center, making it challenging to accurately regress the bounding boxes. To address this issue, we propose a Cascade Voting (CascadeV) strategy that provides high-quality 3D object detection with point-based prediction. Specifically, CascadeV performs cascade detection using a novel Cascade Voting decoder that combines two new components: Instance Aware Voting (IA-Voting) and a Cascade Point Assignment (CPA) module. The IA-Voting module updates the object features of updated proposal points within the bounding box using conditional inverse distance weighting. This approach prevents features from being aggregated outside the instance and helps improve the accuracy of object detection. Additionally, since model training can suffer from a lack of proposal points with high centerness, we have developed the CPA module to narrow down the positive assignment threshold with cascade stages. This approach relaxes the dependence on proposal centerness in the early stages while ensuring an ample quantity of positives with high centerness in the later stages. Experiments show that FCAF3D with our CascadeV achieves state-of-the-art 3D object detection results with 70.4\% mAP@0.25 and 51.6\% mAP@0.5 on SUN RGB-D and competitive results on ScanNet. Code will be released at https://github.com/Sharpiless/CascadeV-Det
LiDAR-based Person Re-identification
Dec 11, 2023Camera-based person re-identification (ReID) systems have been widely applied in the field of public security. However, cameras often lack the perception of 3D morphological information of human and are susceptible to various limitations, such as inadequate illumination, complex background, and personal privacy. In this paper, we propose a LiDAR-based ReID framework, ReID3D, that utilizes pre-training strategy to retrieve features of 3D body shape and introduces Graph-based Complementary Enhancement Encoder for extracting comprehensive features. Due to the lack of LiDAR datasets, we build LReID, the first LiDAR-based person ReID dataset, which is collected in several outdoor scenes with variations in natural conditions. Additionally, we introduce LReID-sync, a simulated pedestrian dataset designed for pre-training encoders with tasks of point cloud completion and shape parameter learning. Extensive experiments on LReID show that ReID3D achieves exceptional performance with a rank-1 accuracy of 94.0, highlighting the significant potential of LiDAR in addressing person ReID tasks. To the best of our knowledge, we are the first to propose a solution for LiDAR-based ReID. The code and datasets will be released soon.