 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Paradigm Representation and Alignment Transformer for Image Deraining
Paper and Code
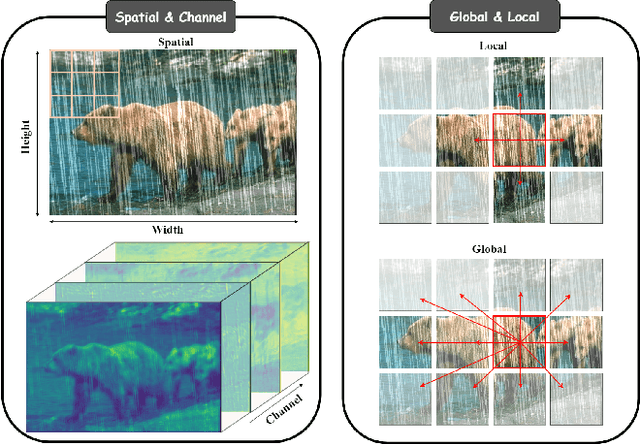
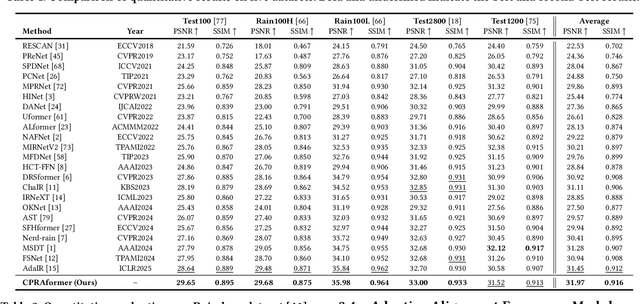
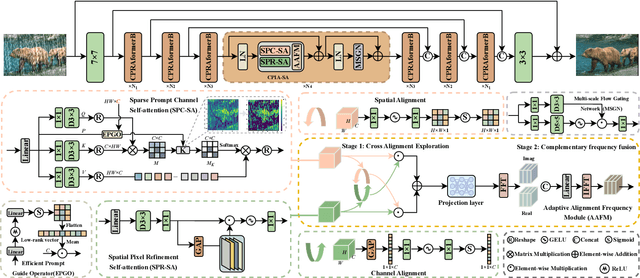
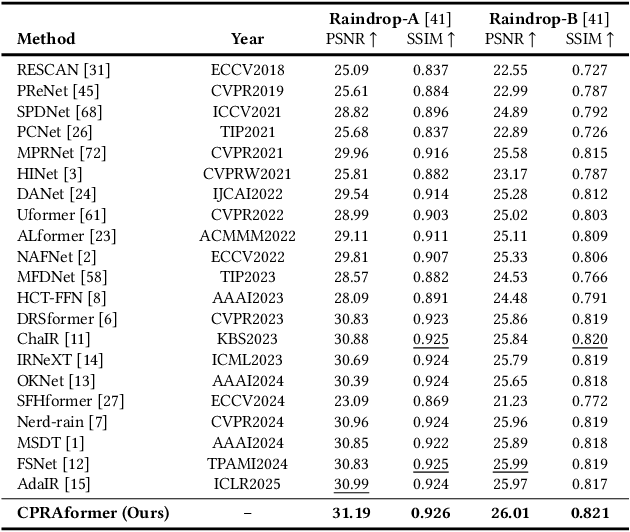
Transformer-based networks have achieved strong performance in low-level vision tasks like image deraining by utilizing spatial or channel-wise self-attention. However, irregular rain patterns and complex geometric overlaps challenge single-paradigm architectures, necessitating a unified framework to integrate complementary global-local and spatial-channel representations. To address this, we propose a novel Cross Paradigm Representation and Alignment Transformer (CPRAformer). Its core idea is the hierarchical representation and alignment, leveraging the strengths of both paradigms (spatial-channel and global-local) to aid image reconstruction. It bridges the gap within and between paradigms, aligning and coordinating them to enable deep interaction and fusion of features. Specifically, we use two types of self-attention in the Transformer blocks: sparse prompt channel self-attention (SPC-SA) and spatial pixel refinement self-attention (SPR-SA). SPC-SA enhances global channel dependencies through dynamic sparsity, while SPR-SA focuses on spatial rain distribution and fine-grained texture recovery. To address the feature misalignment and knowledge differences between them, we introduce the Adaptive Alignment Frequency Module (AAFM), which aligns and interacts with features in a two-stage progressive manner, enabling adaptive guidance and complementarity. This reduces the information gap within and between paradigms. Through this unified cross-paradigm dynamic interaction framework, we achieve the extraction of the most valuable interactive fusion information from the two paradigms. Extensive experiments demonstrate that our model achieves state-of-the-art performance on eight benchmark datasets and further validates CPRAformer's robustness in other image restoration tasks and downstream applications.