 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Anything Match Your Target: Universal Adversarial Perturbations against Closed-Source MLLMs via Multi-Crop Routed Meta Optimization
Jan 30, 2026Targeted adversarial attacks on closed-source multimodal large language models (MLLMs) have been increasingly explored under black-box transfer, yet prior methods are predominantly sample-specific and offer limited reusability across inputs. We instead study a more stringent setting, Universal Targeted Transferable Adversarial Attacks (UTTAA), where a single perturbation must consistently steer arbitrary inputs toward a specified target across unknown commercial MLLMs. Naively adapting existing sample-wise attacks to this universal setting faces three core difficulties: (i) target supervision becomes high-variance due to target-crop randomness, (ii) token-wise matching is unreliable because universality suppresses image-specific cues that would otherwise anchor alignment, and (iii) few-source per-target adaptation is highly initialization-sensitive, which can degrade the attainable performance. In this work, we propose MCRMO-Attack, which stabilizes supervision via Multi-Crop Aggregation with an Attention-Guided Crop, improves token-level reliability through alignability-gated Token Routing, and meta-learns a cross-target perturbation prior that yields stronger per-target solutions. Across commercial MLLMs, we boost unseen-image attack success rate by +23.7\% on GPT-4o and +19.9\% on Gemini-2.0 over the strongest universal baseline.
Semantic Deep Hiding for Robust Unlearnable Examples
Jun 25, 2024Ensuring data privacy and protection has become paramount in the era of deep learning. Unlearnable examples are proposed to mislead the deep learning models and prevent data from unauthorized exploration by adding small perturbations to data. However, such perturbations (e.g., noise, texture, color change) predominantly impact low-level features, making them vulnerable to common countermeasures. In contrast, semantic images with intricate shapes have a wealth of high-level features, making them more resilient to countermeasures and potential for producing robust unlearnable examples. In this paper, we propose a Deep Hiding (DH) scheme that adaptively hides semantic images enriched with high-level features. We employ an Invertible Neural Network (INN) to invisibly integrate predefined images, inherently hiding them with deceptive perturbations. To enhance data unlearnability, we introduce a Latent Feature Concentration module, designed to work with the INN, regularizing the intra-class variance of these perturbations. To further boost the robustness of unlearnable examples, we design a Semantic Images Generation module that produces hidden semantic images. By utilizing similar semantic information, this module generates similar semantic images for samples within the same classes, thereby enlarging the inter-class distance and narrowing the intra-class distance. Extensive experiments on CIFAR-10, CIFAR-100, and an ImageNet subset, against 18 countermeasures, reveal that our proposed method exhibits outstanding robustness for unlearnable examples, demonstrating its efficacy in preventing unauthorized data exploitation.
BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
Dec 06, 2023Large Multimodal Models (LMMs) such as GPT-4V and LLaVA have shown remarkable capabilities in visual reasoning with common image styles. However, their robustness against diverse style shifts, crucial for practical applications, remains largely unexplored. In this paper, we propose a new benchmark, BenchLMM, to assess the robustness of LMMs against three different styles: artistic image style, imaging sensor style, and application style, where each style has five sub-styles. Utilizing BenchLMM, we comprehensively evaluate state-of-the-art LMMs and reveal: 1) LMMs generally suffer performance degradation when working with other styles; 2) An LMM performs better than another model in common style does not guarantee its superior performance in other styles; 3) LMMs' reasoning capability can be enhanced by prompting LMMs to predict the style first, based on which we propose a versatile and training-free method for improving LMMs; 4) An intelligent LMM is expected to interpret the causes of its errors when facing stylistic variations. We hope that our benchmark and analysis can shed new light on developing more intelligent and versatile LMMs.
Temporal Coherent Test-Time Optimization for Robust Video Classification
Feb 28, 2023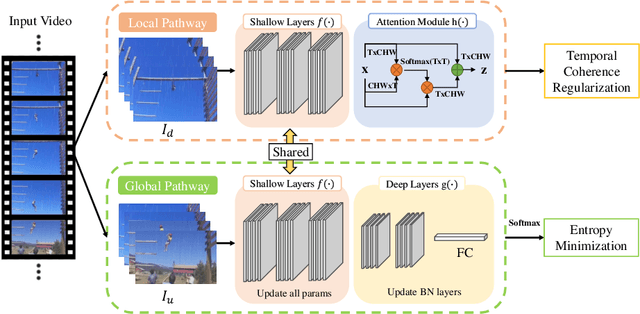
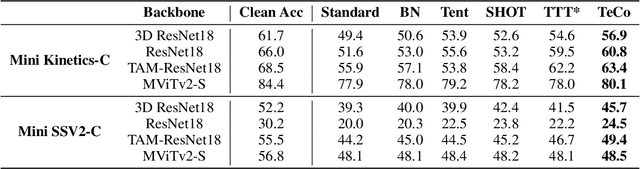
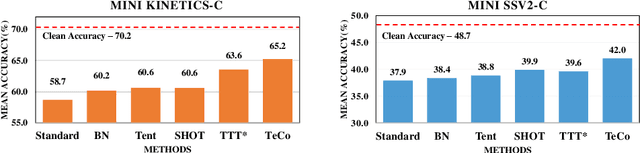

Deep neural networks are likely to fail when the test data is corrupted in real-world deployment (e.g., blur, weather, etc.). Test-time optimization is an effective way that adapts models to generalize to corrupted data during testing, which has been shown in the image domain. However, the techniques for improving video classification corruption robustness remain few. In this work, we propose a Temporal Coherent Test-time Optimization framework (TeCo) to utilize spatio-temporal information in test-time optimization for robust video classification. To exploit information in video with self-supervised learning, TeCo uses global content from video clips and optimizes models for entropy minimization. TeCo minimizes the entropy of the prediction based on the global content from video clips. Meanwhile, it also feeds local content to regularize the temporal coherence at the feature level. TeCo retains the generalization ability of various video classification models and achieves significant improvements in corruption robustness across Mini Kinetics-C and Mini SSV2-C. Furthermore, TeCo sets a new baseline in video classification corruption robustness via test-time optimization.
Benchmarking the Robustness of Spatial-Temporal Models Against Corruptions
Oct 13, 2021
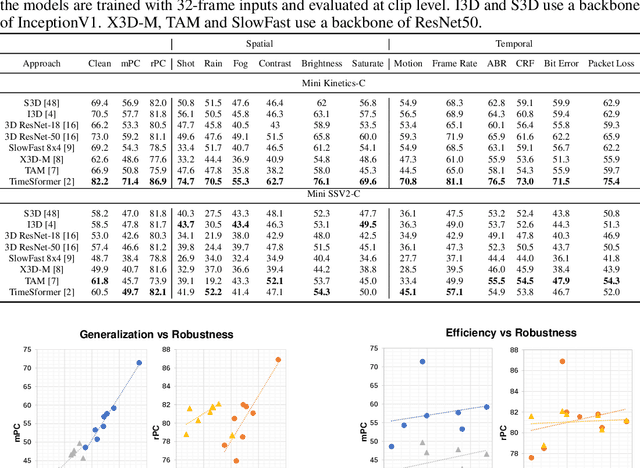
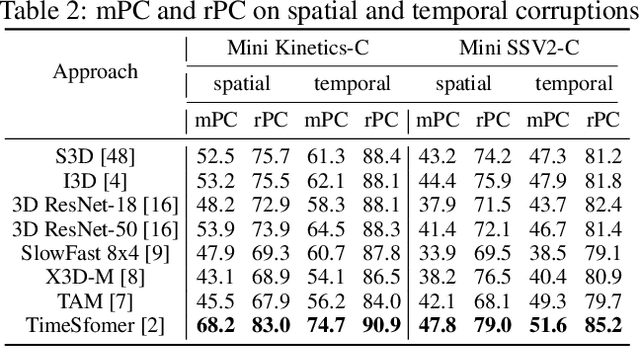
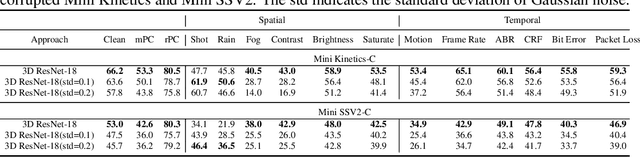
The state-of-the-art deep neural networks are vulnerable to common corruptions (e.g., input data degradations, distortions, and disturbances caused by weather changes, system error, and processing). While much progress has been made in analyzing and improving the robustness of models in image understanding, the robustness in video understanding is largely unexplored. In this paper, we establish a corruption robustness benchmark, Mini Kinetics-C and Mini SSV2-C, which considers temporal corruptions beyond spatial corruptions in images. We make the first attempt to conduct an exhaustive study on the corruption robustness of established CNN-based and Transformer-based spatial-temporal models. The study provides some guidance on robust model design and training: Transformer-based model performs better than CNN-based models on corruption robustness; the generalization ability of spatial-temporal models implies robustness against temporal corruptions; model corruption robustness (especially robustness in the temporal domain) enhances with computational cost and model capacity, which may contradict the current trend of improving the computational efficiency of models. Moreover, we find the robustness intervention for image-related tasks (e.g., training models with noise) may not work for spatial-temporal models.