 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Robustness of Spatial-Temporal Models Against Corruptions
Paper and Code

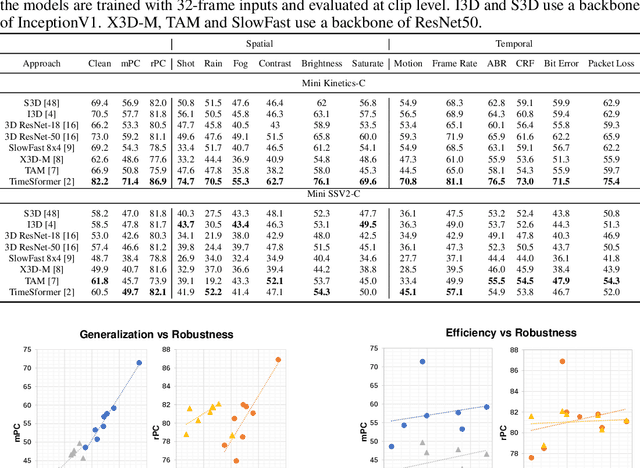
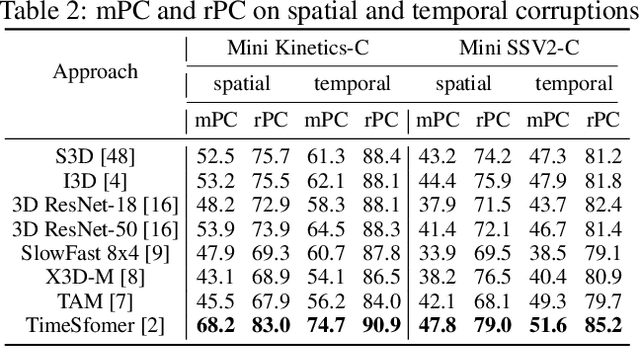
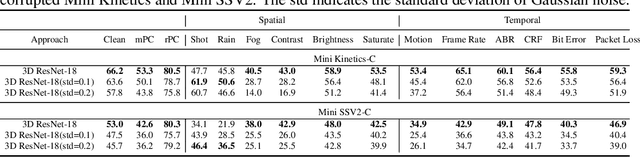
The state-of-the-art deep neural networks are vulnerable to common corruptions (e.g., input data degradations, distortions, and disturbances caused by weather changes, system error, and processing). While much progress has been made in analyzing and improving the robustness of models in image understanding, the robustness in video understanding is largely unexplored. In this paper, we establish a corruption robustness benchmark, Mini Kinetics-C and Mini SSV2-C, which considers temporal corruptions beyond spatial corruptions in images. We make the first attempt to conduct an exhaustive study on the corruption robustness of established CNN-based and Transformer-based spatial-temporal models. The study provides some guidance on robust model design and training: Transformer-based model performs better than CNN-based models on corruption robustness; the generalization ability of spatial-temporal models implies robustness against temporal corruptions; model corruption robustness (especially robustness in the temporal domain) enhances with computational cost and model capacity, which may contradict the current trend of improving the computational efficiency of models. Moreover, we find the robustness intervention for image-related tasks (e.g., training models with noise) may not work for spatial-temporal models.