 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimPER: A Minimalist Approach to Preference Alignment without Hyperparameters
Feb 04, 2025



Existing preference optimization objectives for language model alignment require additional hyperparameters that must be extensively tuned to achieve optimal performance, increasing both the complexity and time required for fine-tuning large language models. In this paper, we propose a simple yet effective hyperparameter-free preference optimization algorithm for alignment. We observe that promising performance can be achieved simply by optimizing inverse perplexity, which is calculated as the inverse of the exponentiated average log-likelihood of the chosen and rejected responses in the preference dataset. The resulting simple learning objective, SimPER, is easy to implement and eliminates the need for expensive hyperparameter tuning and a reference model, making it both computationally and memory efficient. Extensive experiments on widely used real-world benchmarks, including MT-Bench, AlpacaEval 2, and 10 key benchmarks of the Open LLM Leaderboard with 5 base models, demonstrate that SimPER consistently and significantly outperforms existing approaches-even without any hyperparameters or a reference model . For example, despite its simplicity, SimPER outperforms state-of-the-art methods by up to 5.7 points on AlpacaEval 2 and achieves the highest average ranking across 10 benchmarks on the Open LLM Leaderboard. The source code for SimPER is publicly available at: https://github.com/tengxiao1/SimPER.
ERGNN: Spectral Graph Neural Network with Explicitly-optimized Rational Graph Filters
Dec 26, 2024



Approximation-based spectral graph neural networks, which construct graph filters with function approximation, have shown substantial performance in graph learning tasks. Despite their great success, existing works primarily employ polynomial approximation to construct the filters, whereas another superior option, namely ration approximation, remains underexplored. Although a handful of prior works have attempted to deploy the rational approximation, their implementations often involve intensive computational demands or still resort to polynomial approximations, hindering full potential of the rational graph filters. To address the issues, this paper introduces ERGNN, a novel spectral GNN with explicitly-optimized rational filter. ERGNN adopts a unique two-step framework that sequentially applies the numerator filter and the denominator filter to the input signals, thus streamlining the model paradigm while enabling explicit optimization of both numerator and denominator of the rational filter. Extensive experiments validate the superiority of ERGNN over state-of-the-art methods, establishing it as a practical solution for deploying rational-based GNNs.
A Decade of Deep Learning: A Survey on The Magnificent Seven
Dec 13, 2024Deep learning has fundamentally reshaped the landscape of artificial intelligence over the past decade, enabling remarkable achievements across diverse domains. At the heart of these developments lie multi-layered neural network architectures that excel at automatic feature extraction, leading to significant improvements in machine learning tasks. To demystify these advances and offer accessible guidance, we present a comprehensive overview of the most influential deep learning algorithms selected through a broad-based survey of the field. Our discussion centers on pivotal architectures, including Residual Networks, Transformers, Generative Adversarial Networks, Variational Autoencoders, Graph Neural Networks, Contrastive Language-Image Pre-training, and Diffusion models. We detail their historical context, highlight their mathematical foundations and algorithmic principles, and examine subsequent variants, extensions, and practical considerations such as training methodologies, normalization techniques, and learning rate schedules. Beyond historical and technical insights, we also address their applications, challenges, and potential research directions. This survey aims to serve as a practical manual for both newcomers seeking an entry point into cutting-edge deep learning methods and experienced researchers transitioning into this rapidly evolving domain.
MGM: Global Understanding of Audience Overlap Graphs for Predicting the Factuality and the Bias of News Media
Dec 12, 2024



In the current era of rapidly growing digital data, evaluating the political bias and factuality of news outlets has become more important for seeking reliable information online. In this work, we study the classification problem of profiling news media from the lens of political bias and factuality. Traditional profiling methods, such as Pre-trained Language Models (PLMs) and Graph Neural Networks (GNNs) have shown promising results, but they face notable challenges. PLMs focus solely on textual features, causing them to overlook the complex relationships between entities, while GNNs often struggle with media graphs containing disconnected components and insufficient labels. To address these limitations, we propose MediaGraphMind (MGM), an effective solution within a variational Expectation-Maximization (EM) framework. Instead of relying on limited neighboring nodes, MGM leverages features, structural patterns, and label information from globally similar nodes. Such a framework not only enables GNNs to capture long-range dependencies for learning expressive node representations but also enhances PLMs by integrating structural information and therefore improving the performance of both models. The extensive experiments demonstrate the effectiveness of the proposed framework and achieve new state-of-the-art results. Further, we share our repository1 which contains the dataset, code, and documentation
DuSEGO: Dual Second-order Equivariant Graph Ordinary Differential Equation
Nov 15, 2024
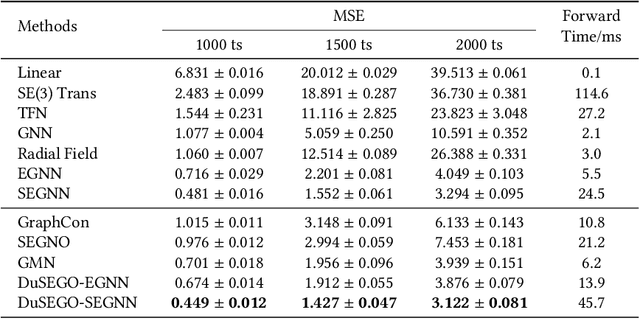
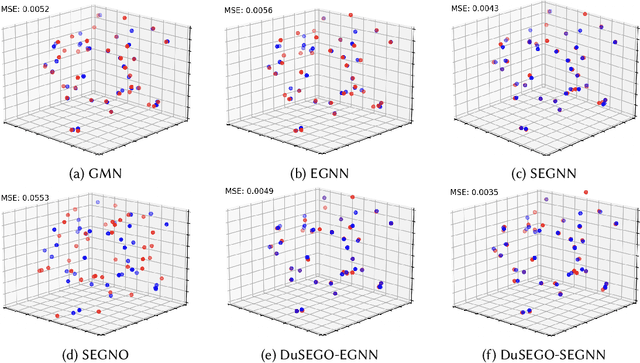
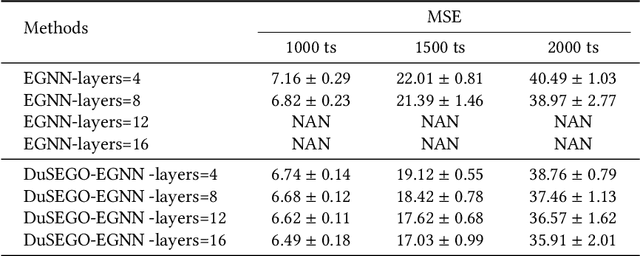
Graph Neural Networks (GNNs) with equivariant properties have achieved significant success in modeling complex dynamic systems and molecular properties. However, their expressiveness ability is limited by: (1) Existing methods often overlook the over-smoothing issue caused by traditional GNN models, as well as the gradient explosion or vanishing problems in deep GNNs. (2) Most models operate on first-order information, neglecting that the real world often consists of second-order systems, which further limits the model's representation capabilities. To address these issues, we propose the \textbf{Du}al \textbf{S}econd-order \textbf{E}quivariant \textbf{G}raph \textbf{O}rdinary Differential Equation (\method{}) for equivariant representation. Specifically, \method{} apply the dual second-order equivariant graph ordinary differential equations (Graph ODEs) on graph embeddings and node coordinates, simultaneously. Theoretically, we first prove that \method{} maintains the equivariant property. Furthermore, we provide theoretical insights showing that \method{} effectively alleviates the over-smoothing problem in both feature representation and coordinate update. Additionally, we demonstrate that the proposed \method{} mitigates the exploding and vanishing gradients problem, facilitating the training of deep multi-layer GNNs. Extensive experiments on benchmark datasets validate the superiority of the proposed \method{} compared to baselines.
Degree Distribution based Spiking Graph Networks for Domain Adaptation
Oct 10, 2024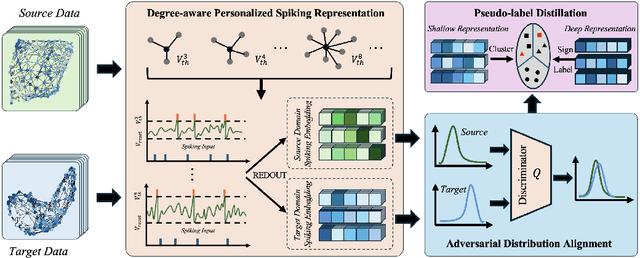
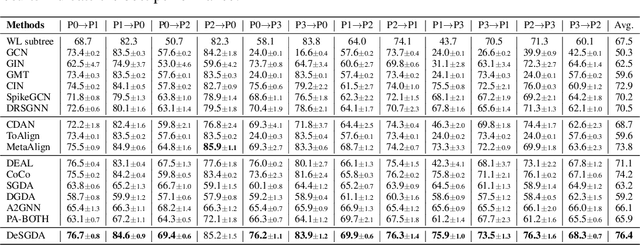

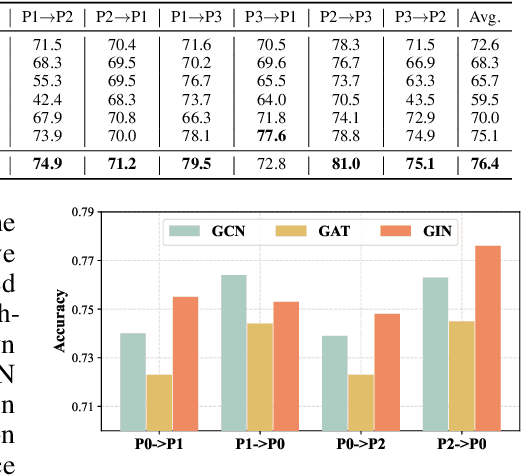
Spiking Graph Networks (SGNs) have garnered significant attraction from both researchers and industry due to their ability to address energy consumption challenges in graph classification. However, SGNs are only effective for in-distribution data and cannot tackle out-of-distribution data. In this paper, we first propose the domain adaptation problem in SGNs, and introduce a novel framework named Degree-aware Spiking Graph Domain Adaptation for Classification. The proposed DeSGDA addresses the spiking graph domain adaptation problem by three aspects: node degree-aware personalized spiking representation, adversarial feature distribution alignment, and pseudo-label distillation. First, we introduce the personalized spiking representation method for generating degree-dependent spiking signals. Specifically, the threshold of triggering a spike is determined by the node degree, allowing this personalized approach to capture more expressive information for classification. Then, we propose the graph feature distribution alignment module that is adversarially trained using membrane potential against a domain discriminator. Such an alignment module can efficiently maintain high performance and low energy consumption in the case of inconsistent distribution. Additionally, we extract consistent predictions across two spaces to create reliable pseudo-labels, effectively leveraging unlabeled data to enhance graph classification performance. Extensive experiments on benchmark datasets validate the superiority of the proposed DeSGDA compared with competitive baselines.
Improving the Expressiveness of $K$-hop Message-Passing GNNs by Injecting Contextualized Substructure Information
Jun 27, 2024Graph neural networks (GNNs) have become the \textit{de facto} standard for representational learning in graphs, and have achieved state-of-the-art performance in many graph-related tasks; however, it has been shown that the expressive power of standard GNNs are equivalent maximally to 1-dimensional Weisfeiler-Lehman (1-WL) Test. Recently, there is a line of works aiming to enhance the expressive power of graph neural networks. One line of such works aim at developing $K$-hop message-passing GNNs where node representation is updated by aggregating information from not only direct neighbors but all neighbors within $K$-hop of the node. Another line of works leverages subgraph information to enhance the expressive power which is proven to be strictly more powerful than 1-WL test. In this work, we discuss the limitation of $K$-hop message-passing GNNs and propose \textit{substructure encoding function} to uplift the expressive power of any $K$-hop message-passing GNN. We further inject contextualized substructure information to enhance the expressiveness of $K$-hop message-passing GNNs. Our method is provably more powerful than previous works on $K$-hop graph neural networks and 1-WL subgraph GNNs, which is a specific type of subgraph based GNN models, and not less powerful than 3-WL. Empirically, our proposed method set new state-of-the-art performance or achieves comparable performance for a variety of datasets. Our code is available at \url{https://github.com/tianyao-aka/Expresive_K_hop_GNNs}.
Elevating Spectral GNNs through Enhanced Band-pass Filter Approximation
Apr 15, 2024Spectral Graph Neural Networks (GNNs) have attracted great attention due to their capacity to capture patterns in the frequency domains with essential graph filters. Polynomial-based ones (namely poly-GNNs), which approximately construct graph filters with conventional or rational polynomials, are routinely adopted in practice for their substantial performances on graph learning tasks. However, previous poly-GNNs aim at achieving overall lower approximation error on different types of filters, e.g., low-pass and high-pass, but ignore a key question: \textit{which type of filter warrants greater attention for poly-GNNs?} In this paper, we first show that poly-GNN with a better approximation for band-pass graph filters performs better on graph learning tasks. This insight further sheds light on critical issues of existing poly-GNNs, i.e., those poly-GNNs achieve trivial performance in approximating band-pass graph filters, hindering the great potential of poly-GNNs. To tackle the issues, we propose a novel poly-GNN named TrigoNet. TrigoNet constructs different graph filters with novel trigonometric polynomial, and achieves leading performance in approximating band-pass graph filters against other polynomials. By applying Taylor expansion and deserting nonlinearity, TrigoNet achieves noticeable efficiency among baselines. Extensive experiments show the advantages of TrigoNet in both accuracy performances and efficiency.
Weakly Supervised Deep Hyperspherical Quantization for Image Retrieval
Apr 07, 2024Deep quantization methods have shown high efficiency on large-scale image retrieval. However, current models heavily rely on ground-truth information, hindering the application of quantization in label-hungry scenarios. A more realistic demand is to learn from inexhaustible uploaded images that are associated with informal tags provided by amateur users. Though such sketchy tags do not obviously reveal the labels, they actually contain useful semantic information for supervising deep quantization. To this end, we propose Weakly-Supervised Deep Hyperspherical Quantization (WSDHQ), which is the first work to learn deep quantization from weakly tagged images. Specifically, 1) we use word embeddings to represent the tags and enhance their semantic information based on a tag correlation graph. 2) To better preserve semantic information in quantization codes and reduce quantization error, we jointly learn semantics-preserving embeddings and supervised quantizer on hypersphere by employing a well-designed fusion layer and tailor-made loss functions. Extensive experiments show that WSDHQ can achieve state-of-art performance on weakly-supervised compact coding. Code is available at https://github.com/gimpong/AAAI21-WSDHQ.
Spectral GNN via Two-dimensional (2-D) Graph Convolution
Apr 06, 2024Spectral Graph Neural Networks (GNNs) have achieved tremendous success in graph learning. As an essential part of spectral GNNs, spectral graph convolution extracts crucial frequency information in graph data, leading to superior performance of spectral GNNs in downstream tasks. However, in this paper, we show that existing spectral GNNs remain critical drawbacks in performing the spectral graph convolution. Specifically, considering the spectral graph convolution as a construction operation towards target output, we prove that existing popular convolution paradigms cannot construct the target output with mild conditions on input graph signals, causing spectral GNNs to fall into suboptimal solutions. To address the issues, we rethink the spectral graph convolution from a more general two-dimensional (2-D) signal convolution perspective and propose a new convolution paradigm, named 2-D graph convolution. We prove that 2-D graph convolution unifies existing graph convolution paradigms, and is capable to construct arbitrary target output. Based on the proposed 2-D graph convolution, we further propose ChebNet2D, an efficient and effective GNN implementation of 2-D graph convolution through applying Chebyshev interpolation. Extensive experiments on benchmark datasets demonstrate both effectiveness and efficiency of the ChebNet2D.