 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Graph Representation Learning by Contrastive Regularization
Paper and Code
Jan 27, 2021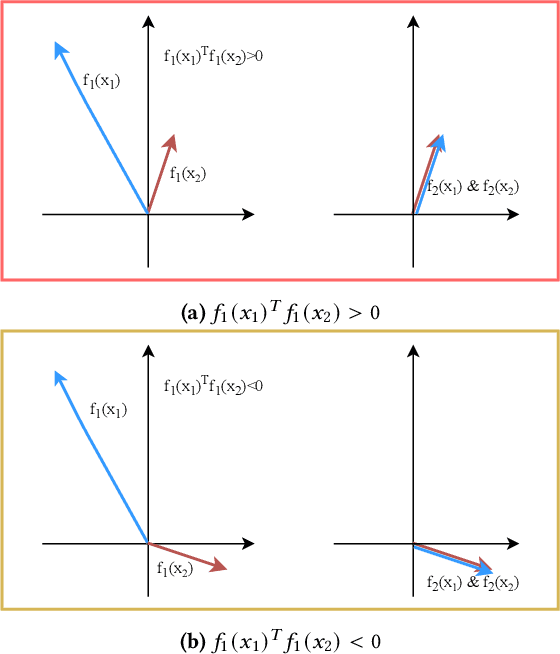
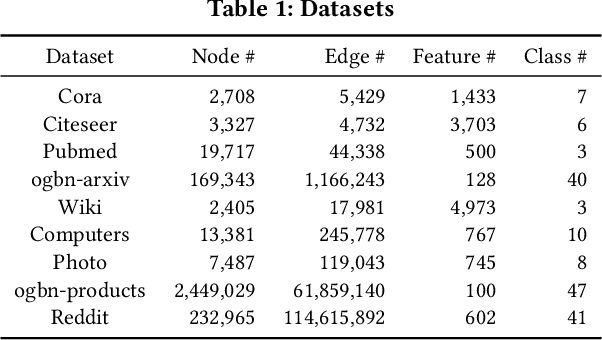
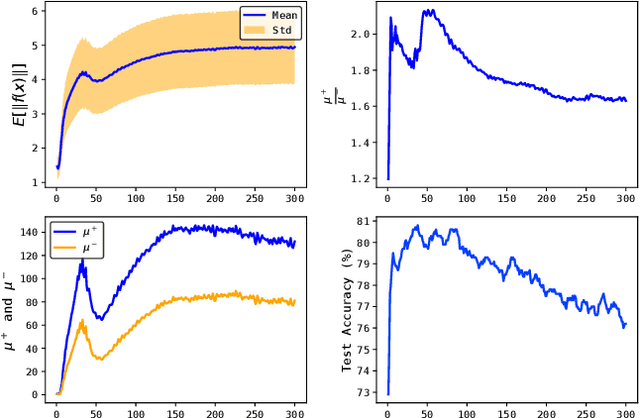
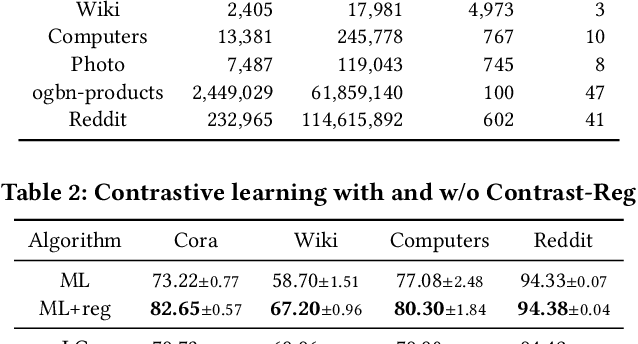
Graph representation learning is an important task with applications in various areas such as online social networks, e-commerce networks, WWW, and semantic webs. For unsupervised graph representation learning, many algorithms such as Node2Vec and Graph-SAGE make use of "negative sampling" and/or noise contrastive estimation loss. This bears similar ideas to contrastive learning, which "contrasts" the node representation similarities of semantically similar (positive) pairs against those of negative pairs. However, despite the success of contrastive learning, we found that directly applying this technique to graph representation learning models (e.g., graph convolutional networks) does not always work. We theoretically analyze the generalization performance and propose a light-weight regularization term that avoids the high scales of node representations' norms and the high variance among them to improve the generalization performance. Our experimental results further validate that this regularization term significantly improves the representation quality across different node similarity definitions and outperforms the state-of-the-art methods.