 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSRA: Joint Mean Opinion Score and Room Acoustics Speech Quality Assessment
Apr 04, 2022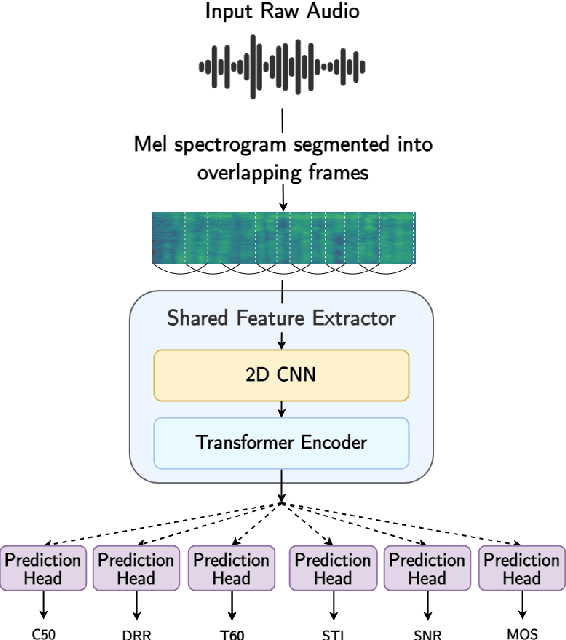
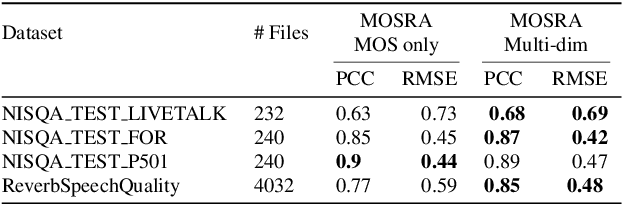
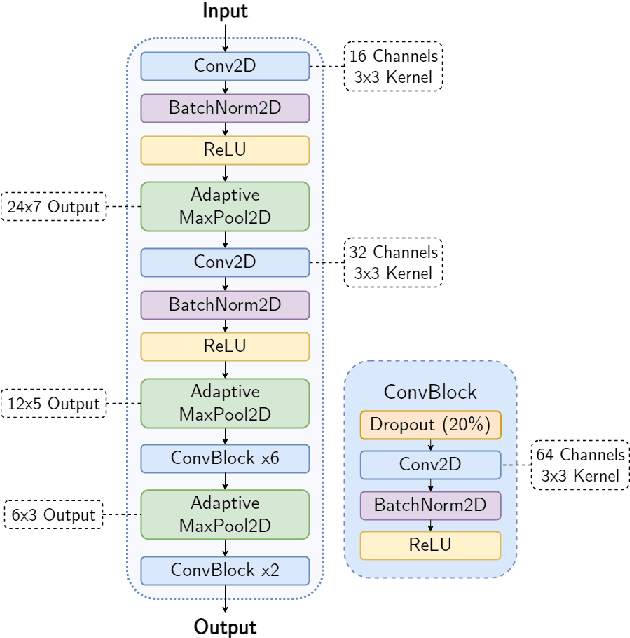
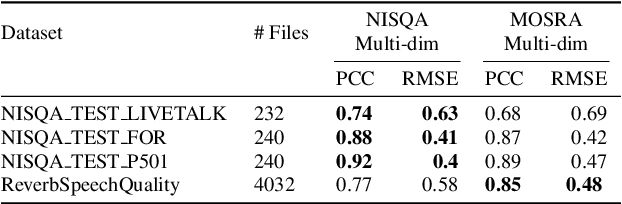
The acoustic environment can degrade speech quality during communication (e.g., video call, remote presentation, outside voice recording), and its impact is often unknown. Objective metrics for speech quality have proven challenging to develop given the multi-dimensionality of factors that affect speech quality and the difficulty of collecting labeled data. Hypothesizing the impact of acoustics on speech quality, this paper presents MOSRA: a non-intrusive multi-dimensional speech quality metric that can predict room acoustics parameters (SNR, STI, T60, DRR, and C50) alongside the overall mean opinion score (MOS) for speech quality. By explicitly optimizing the model to learn these room acoustics parameters, we can extract more informative features and improve the generalization for the MOS task when the training data is limited. Furthermore, we also show that this joint training method enhances the blind estimation of room acoustics, improving the performance of current state-of-the-art models. An additional side-effect of this joint prediction is the improvement in the explainability of the predictions, which is a valuable feature for many applications.
Hybrid Handcrafted and Learnable Audio Representation for Analysis of Speech Under Cognitive and Physical Load
Mar 30, 2022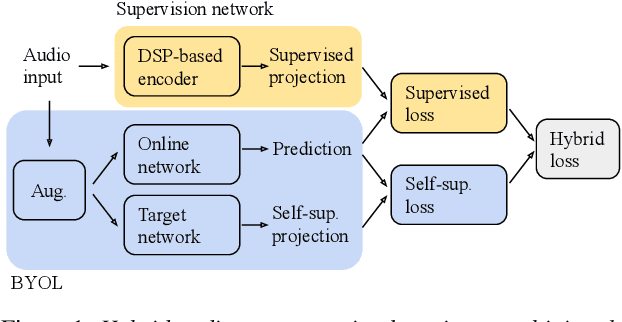

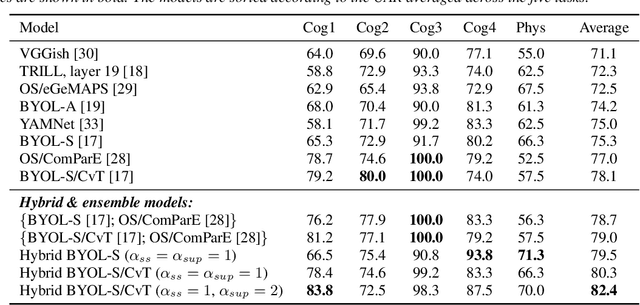
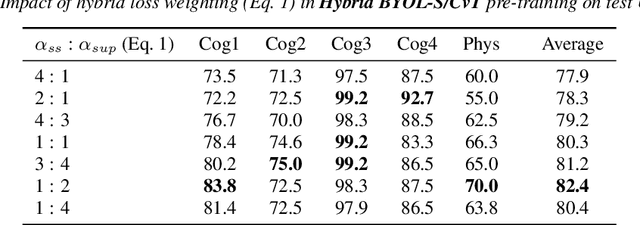
As a neurophysiological response to threat or adverse conditions, stress can affect cognition, emotion and behaviour with potentially detrimental effects on health in the case of sustained exposure. Since the affective content of speech is inherently modulated by an individual's physical and mental state, a substantial body of research has been devoted to the study of paralinguistic correlates of stress-inducing task load. Historically, voice stress analysis (VSA) has been conducted using conventional digital signal processing (DSP) techniques. Despite the development of modern methods based on deep neural networks (DNNs), accurately detecting stress in speech remains difficult due to the wide variety of stressors and considerable variability in the individual stress perception. To that end, we introduce a set of five datasets for task load detection in speech. The voice recordings were collected as either cognitive or physical stress was induced in the cohort of volunteers, with a cumulative number of more than a hundred speakers. We used the datasets to design and evaluate a novel self-supervised audio representation that leverages the effectiveness of handcrafted features (DSP-based) and the complexity of data-driven DNN representations. Notably, the proposed approach outperformed both extensive handcrafted feature sets and novel DNN-based audio representation learning approaches.
Spiking neural networks trained with backpropagation for low power neuromorphic implementation of voice activity detection
Oct 22, 2019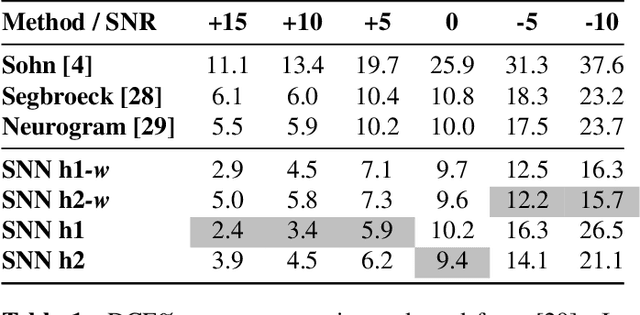
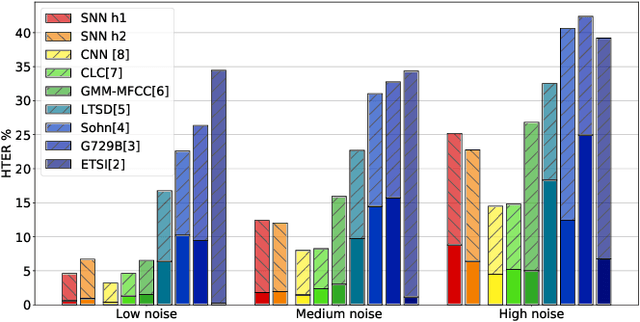
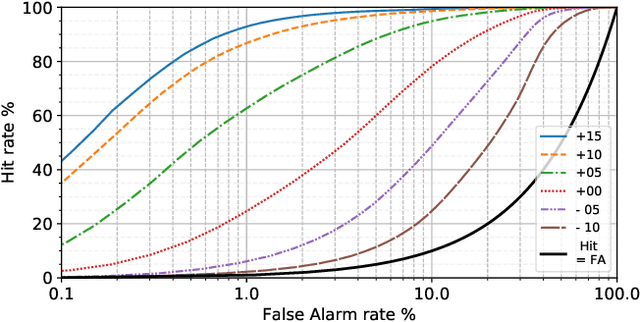
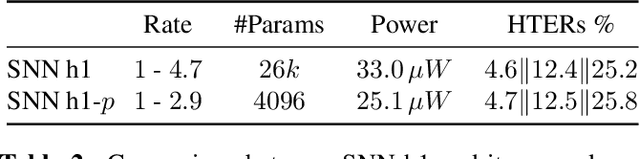
Recent advances in Voice Activity Detection (VAD) are driven by artificial and Recurrent Neural Networks (RNNs), however, using a VAD system in battery-operated devices requires further power efficiency. This can be achieved by neuromorphic hardware, which enables Spiking Neural Networks (SNNs) to perform inference at very low energy consumption. Spiking networks are characterized by their ability to process information efficiently, in a sparse cascade of binary events in time called spikes. However, a big performance gap separates artificial from spiking networks, mostly due to a lack of powerful SNN training algorithms. To overcome this problem we exploit an SNN model that can be recast into an RNN-like model and trained with known deep learning techniques. We describe an SNN training procedure that achieves low spiking activity and pruning algorithms to remove 85% of the network connections with no performance loss. The model achieves state-of-the-art performance with a fraction of power consumption comparing to other methods.