 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRejecting Cognitivism: Computational Phenomenology for Deep Learning
Feb 16, 2023We propose a non-representationalist framework for deep learning relying on a novel method: computational phenomenology, a dialogue between the first-person perspective (relying on phenomenology) and the mechanisms of computational models. We thereby reject the modern cognitivist interpretation of deep learning, according to which artificial neural networks encode representations of external entities. This interpretation mainly relies on neuro-representationalism, a position that combines a strong ontological commitment towards scientific theoretical entities and the idea that the brain operates on symbolic representations of these entities. We proceed as follows: after offering a review of cognitivism and neuro-representationalism in the field of deep learning, we first elaborate a phenomenological critique of these positions; we then sketch out computational phenomenology and distinguish it from existing alternatives; finally we apply this new method to deep learning models trained on specific tasks, in order to formulate a conceptual framework of deep-learning, that allows one to think of artificial neural networks' mechanisms in terms of lived experience.
BYOL-S: Learning Self-supervised Speech Representations by Bootstrapping
Jun 30, 2022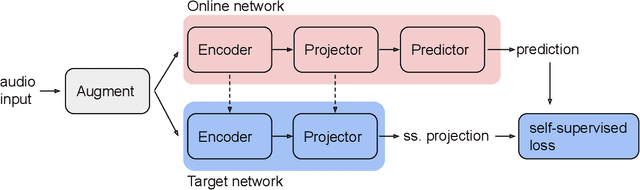



Methods for extracting audio and speech features have been studied since pioneering work on spectrum analysis decades ago. Recent efforts are guided by the ambition to develop general-purpose audio representations. For example, deep neural networks can extract optimal embeddings if they are trained on large audio datasets. This work extends existing methods based on self-supervised learning by bootstrapping, proposes various encoder architectures, and explores the effects of using different pre-training datasets. Lastly, we present a novel training framework to come up with a hybrid audio representation, which combines handcrafted and data-driven learned audio features. All the proposed representations were evaluated within the HEAR NeurIPS 2021 challenge for auditory scene classification and timestamp detection tasks. Our results indicate that the hybrid model with a convolutional transformer as the encoder yields superior performance in most HEAR challenge tasks.
Hybrid Handcrafted and Learnable Audio Representation for Analysis of Speech Under Cognitive and Physical Load
Mar 30, 2022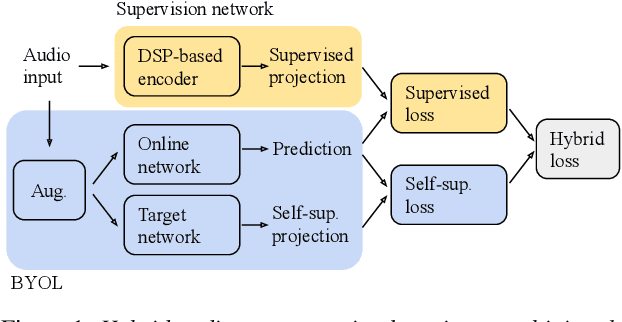

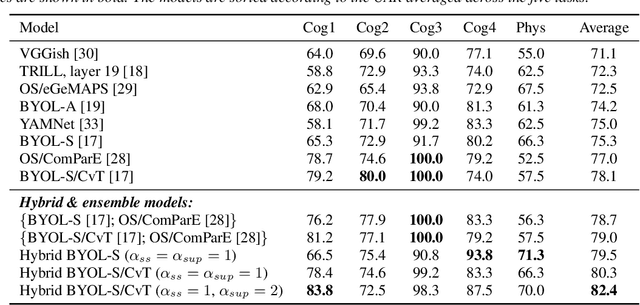
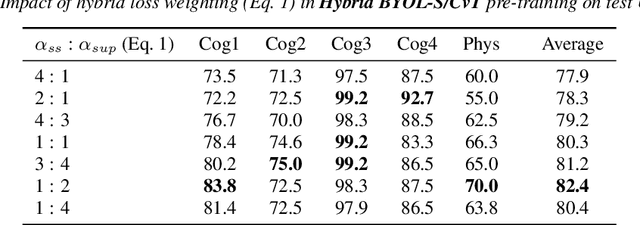
As a neurophysiological response to threat or adverse conditions, stress can affect cognition, emotion and behaviour with potentially detrimental effects on health in the case of sustained exposure. Since the affective content of speech is inherently modulated by an individual's physical and mental state, a substantial body of research has been devoted to the study of paralinguistic correlates of stress-inducing task load. Historically, voice stress analysis (VSA) has been conducted using conventional digital signal processing (DSP) techniques. Despite the development of modern methods based on deep neural networks (DNNs), accurately detecting stress in speech remains difficult due to the wide variety of stressors and considerable variability in the individual stress perception. To that end, we introduce a set of five datasets for task load detection in speech. The voice recordings were collected as either cognitive or physical stress was induced in the cohort of volunteers, with a cumulative number of more than a hundred speakers. We used the datasets to design and evaluate a novel self-supervised audio representation that leverages the effectiveness of handcrafted features (DSP-based) and the complexity of data-driven DNN representations. Notably, the proposed approach outperformed both extensive handcrafted feature sets and novel DNN-based audio representation learning approaches.
SERAB: A multi-lingual benchmark for speech emotion recognition
Oct 07, 2021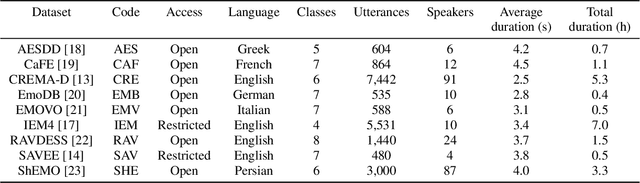
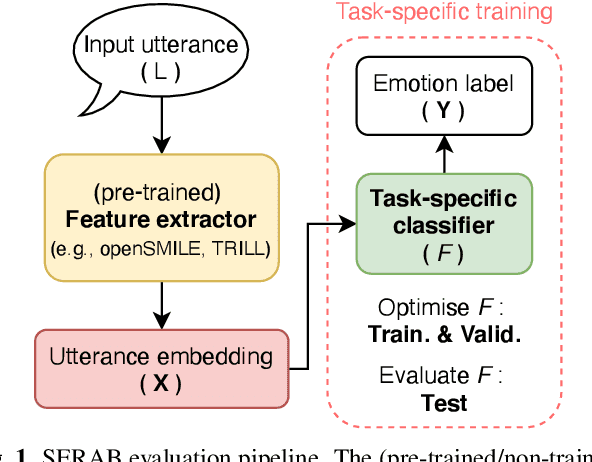
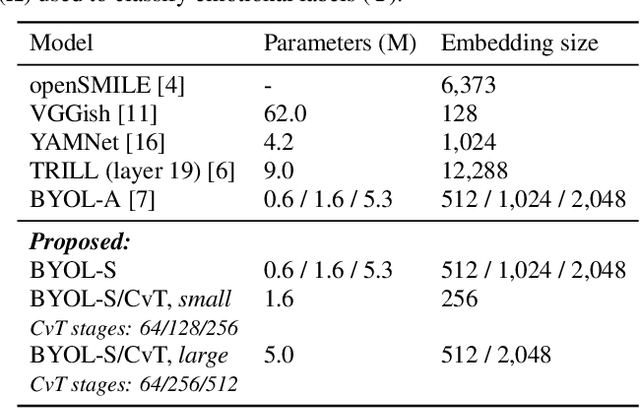
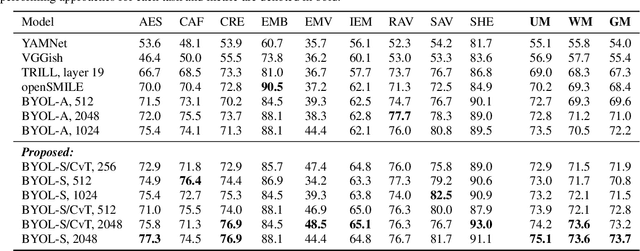
Recent developments in speech emotion recognition (SER) often leverage deep neural networks (DNNs). Comparing and benchmarking different DNN models can often be tedious due to the use of different datasets and evaluation protocols. To facilitate the process, here, we present the Speech Emotion Recognition Adaptation Benchmark (SERAB), a framework for evaluating the performance and generalization capacity of different approaches for utterance-level SER. The benchmark is composed of nine datasets for SER in six languages. Since the datasets have different sizes and numbers of emotional classes, the proposed setup is particularly suitable for estimating the generalization capacity of pre-trained DNN-based feature extractors. We used the proposed framework to evaluate a selection of standard hand-crafted feature sets and state-of-the-art DNN representations. The results highlight that using only a subset of the data included in SERAB can result in biased evaluation, while compliance with the proposed protocol can circumvent this issue.
Speech-VGG: A deep feature extractor for speech processing
Oct 22, 2019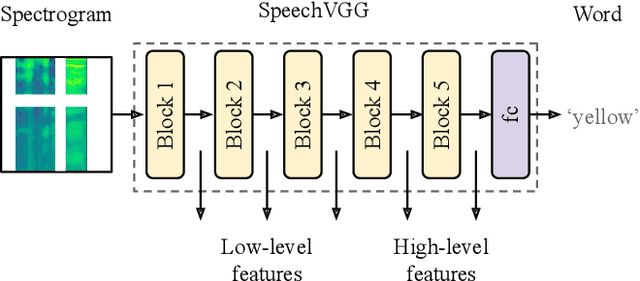
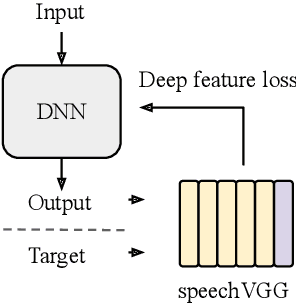

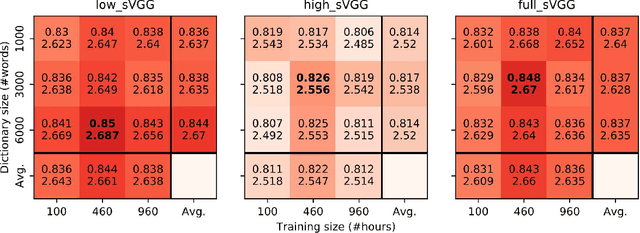
A growing number of studies in the field of speech processing employ feature losses to train deep learning systems. While the application of this framework typically yields beneficial results, the question of what's the optimal setup for extracting transferable speech features to compute losses remains underexplored. In this study, we extend our previous work on speechVGG, a deep feature extractor for training speech processing frameworks. The extractor is based on the classic VGG-16 convolutional neural network re-trained to identify words from the log magnitude STFT features. To estimate the influence of different hyperparameters on the extractor's performance, we applied several configurations of speechVGG to train a system for informed speech inpainting, the context-based recovery of missing parts from time-frequency masked speech segments. We show that changing the size of the dictionary and the size of the dataset used to pre-train the speechVGG notably modulates task performance of the main framework.
Deep speech inpainting of time-frequency masks
Oct 22, 2019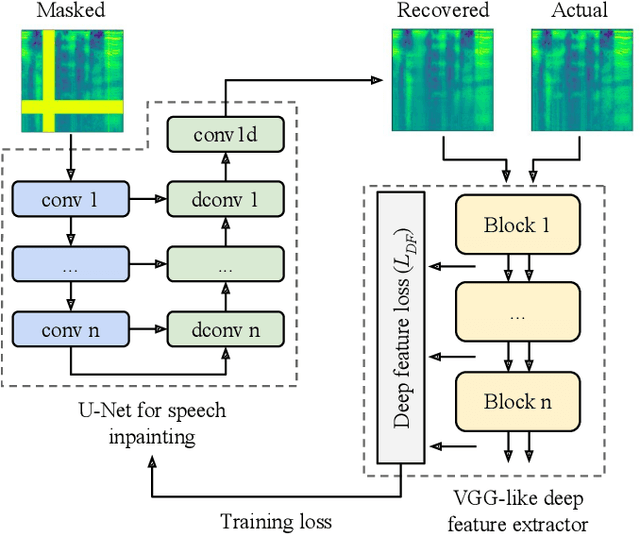
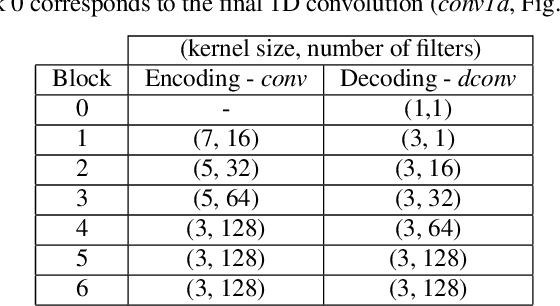
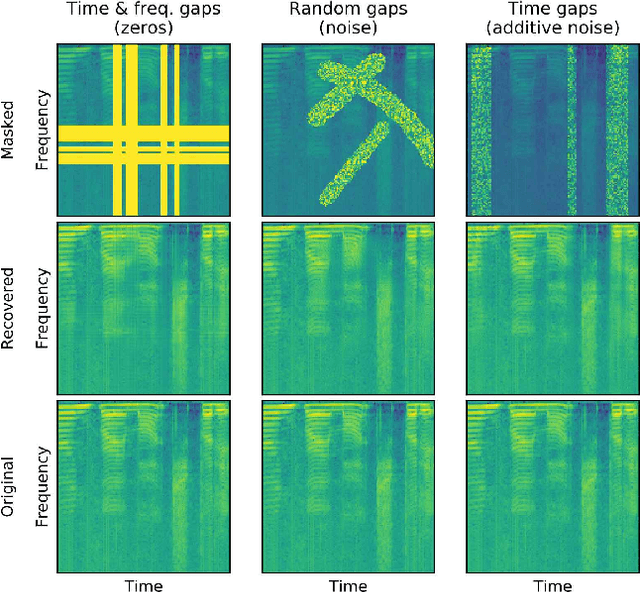
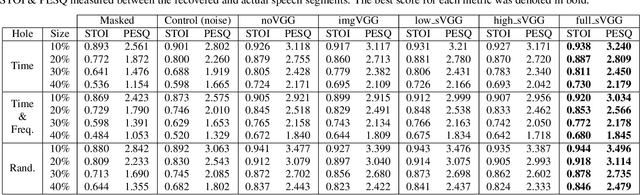
In particularly noisy environments, transient loud intrusions can completely overpower parts of the speech signal, leading to an inevitable loss of information. Recent algorithms for noise suppression often yield impressive results but tend to struggle when the signal-to-noise ratio (SNR) of the mixture is low or when parts of the signal are missing. To address these issues, here we introduce an end-to-end framework for the retrieval of missing or severely distorted parts of time-frequency representation of speech, from the short-term context, thus speech inpainting. The framework is based on a convolutional U-Net trained via deep feature losses, obtained through speechVGG, a deep speech feature extractor pre-trained on the word classification task. Our evaluation results demonstrate that the proposed framework is effective at recovering large portions of missing or distorted parts of speech. Specifically, it yields notable improvements in STOI & PESQ objective metrics, as assessed using the LibriSpeech dataset.