 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCough-E: A multimodal, privacy-preserving cough detection algorithm for the edge
Oct 31, 2024

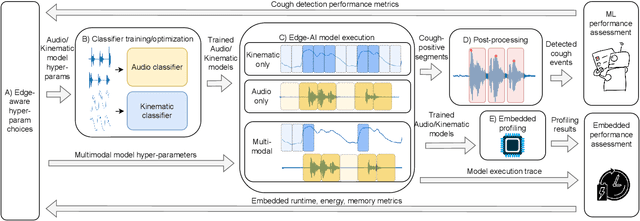

Continuous cough monitors can greatly aid doctors in home monitoring and treatment of respiratory diseases. Although many algorithms have been proposed, they still face limitations in data privacy and short-term monitoring. Edge-AI offers a promising solution by processing privacy-sensitive data near the source, but challenges arise in deploying resource-intensive algorithms on constrained devices. From a suitable selection of audio and kinematic signals, our methodology aims at the optimal selection of features via Recursive Feature Elimination with Cross-Validation (RFECV), which exploits the explainability of the selected XGB model. Additionally, it analyzes the use of Mel spectrogram features, instead of the more common MFCC. Moreover, a set of hyperparameters for a multimodal implementation of the classifier is explored. Finally, it evaluates the performance based on clinically relevant event-based metrics. We apply our methodology to develop Cough-E, an energy-efficient, multimodal and edge AI cough detection algorithm. It exploits audio and kinematic data in two distinct classifiers, jointly cooperating for a balanced energy and performance trade-off. We demonstrate that our algorithm can be executed in real-time on an ARM Cortex M33 microcontroller. Cough-E achieves a 70.56\% energy saving when compared to the audio-only approach, at the cost of a 1.26\% relative performance drop, resulting in a 0.78 F1-score. Both Cough-E and the edge-aware model optimization methodology are publicly available as open-source code. This approach demonstrates the benefits of the proposed hardware-aware methodology to enable privacy-preserving cough monitors on the edge, paving the way to efficient cough monitoring.
How to Count Coughs: An Event-Based Framework for Evaluating Automatic Cough Detection Algorithm Performance
Jun 03, 2024Chronic cough disorders are widespread and challenging to assess because they rely on subjective patient questionnaires about cough frequency. Wearable devices running Machine Learning (ML) algorithms are promising for quantifying daily coughs, providing clinicians with objective metrics to track symptoms and evaluate treatments. However, there is a mismatch between state-of-the-art metrics for cough counting algorithms and the information relevant to clinicians. Most works focus on distinguishing cough from non-cough samples, which does not directly provide clinically relevant outcomes such as the number of cough events or their temporal patterns. In addition, typical metrics such as specificity and accuracy can be biased by class imbalance. We propose using event-based evaluation metrics aligned with clinical guidelines on significant cough counting endpoints. We use an ML classifier to illustrate the shortcomings of traditional sample-based accuracy measurements, highlighting their variance due to dataset class imbalance and sample window length. We also present an open-source event-based evaluation framework to test algorithm performance in identifying cough events and rejecting false positives. We provide examples and best practice guidelines in event-based cough counting as a necessary first step to assess algorithm performance with clinical relevance.
A Semi-Supervised Algorithm for Improving the Consistency of Crowdsourced Datasets: The COVID-19 Case Study on Respiratory Disorder Classification
Sep 09, 2022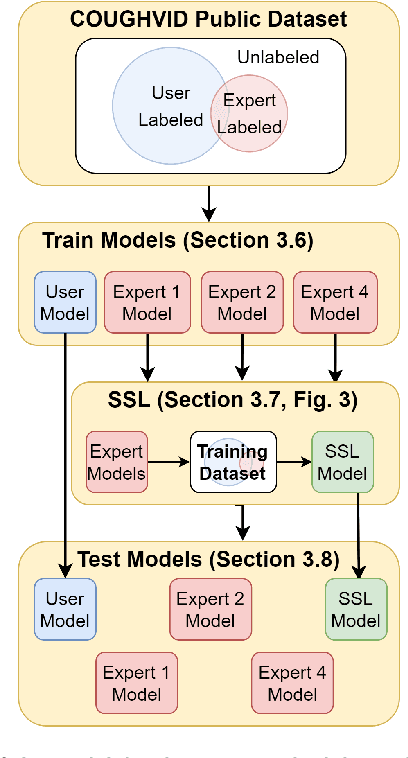

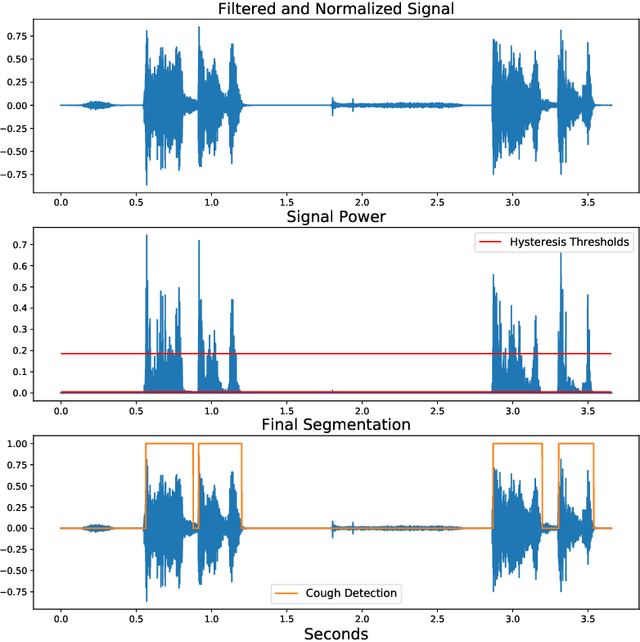
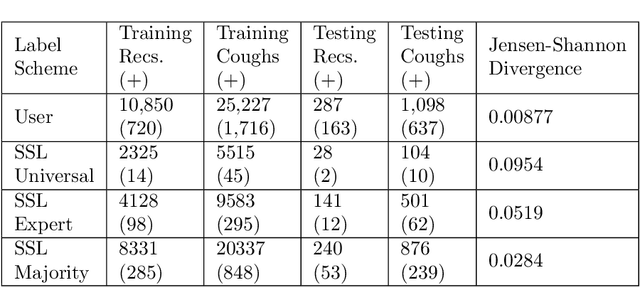
Cough audio signal classification is a potentially useful tool in screening for respiratory disorders, such as COVID-19. Since it is dangerous to collect data from patients with such contagious diseases, many research teams have turned to crowdsourcing to quickly gather cough sound data, as it was done to generate the COUGHVID dataset. The COUGHVID dataset enlisted expert physicians to diagnose the underlying diseases present in a limited number of uploaded recordings. However, this approach suffers from potential mislabeling of the coughs, as well as notable disagreement between experts. In this work, we use a semi-supervised learning (SSL) approach to improve the labeling consistency of the COUGHVID dataset and the robustness of COVID-19 versus healthy cough sound classification. First, we leverage existing SSL expert knowledge aggregation techniques to overcome the labeling inconsistencies and sparsity in the dataset. Next, our SSL approach is used to identify a subsample of re-labeled COUGHVID audio samples that can be used to train or augment future cough classification models. The consistency of the re-labeled data is demonstrated in that it exhibits a high degree of class separability, 3x higher than that of the user-labeled data, despite the expert label inconsistency present in the original dataset. Furthermore, the spectral differences in the user-labeled audio segments are amplified in the re-labeled data, resulting in significantly different power spectral densities between healthy and COVID-19 coughs, which demonstrates both the increased consistency of the new dataset and its explainability from an acoustic perspective. Finally, we demonstrate how the re-labeled dataset can be used to train a cough classifier. This SSL approach can be used to combine the medical knowledge of several experts to improve the database consistency for any diagnostic classification task.
Hybrid Handcrafted and Learnable Audio Representation for Analysis of Speech Under Cognitive and Physical Load
Mar 30, 2022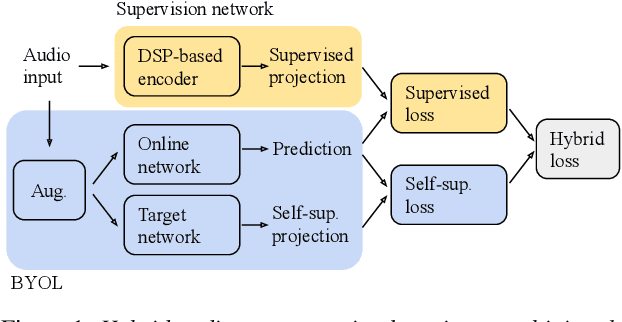

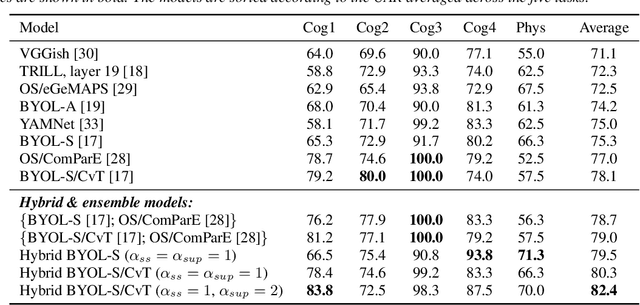
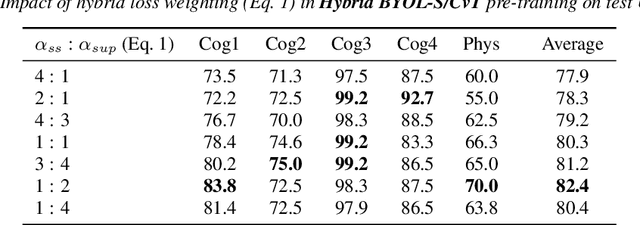
As a neurophysiological response to threat or adverse conditions, stress can affect cognition, emotion and behaviour with potentially detrimental effects on health in the case of sustained exposure. Since the affective content of speech is inherently modulated by an individual's physical and mental state, a substantial body of research has been devoted to the study of paralinguistic correlates of stress-inducing task load. Historically, voice stress analysis (VSA) has been conducted using conventional digital signal processing (DSP) techniques. Despite the development of modern methods based on deep neural networks (DNNs), accurately detecting stress in speech remains difficult due to the wide variety of stressors and considerable variability in the individual stress perception. To that end, we introduce a set of five datasets for task load detection in speech. The voice recordings were collected as either cognitive or physical stress was induced in the cohort of volunteers, with a cumulative number of more than a hundred speakers. We used the datasets to design and evaluate a novel self-supervised audio representation that leverages the effectiveness of handcrafted features (DSP-based) and the complexity of data-driven DNN representations. Notably, the proposed approach outperformed both extensive handcrafted feature sets and novel DNN-based audio representation learning approaches.
Wearable and Continuous Prediction of Passage of Time Perception for Monitoring Mental Health
May 03, 2021

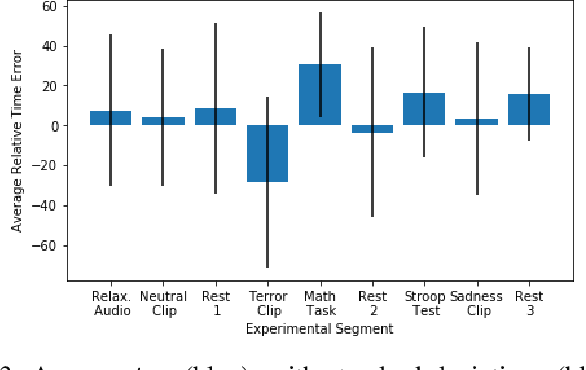
A person's passage of time perception (POTP) is strongly linked to their mental state and stress response, and can therefore provide an easily quantifiable means of continuous mental health monitoring. In this work, we develop a custom experiment and Machine Learning (ML) models for predicting POTP from biomarkers acquired from wearable biosensors. We first confirm that individuals experience time passing slower than usual during fear or sadness (p = 0.046) and faster than usual during cognitive tasks (p = 2 x 10^-5). Then, we group together the experimental segments associated with fast, slow, and normal POTP, and train a ML model to classify between these states based on a person's biomarkers. The classifier had a weighted average F-1 score of 79%, with the fast-passing time class having the highest F-1 score of 93%. Next, we classify each individual's POTP regardless of the task at hand, achieving an F-1 score of 77.1% when distinguishing time passing faster rather than slower than usual. In the two classifiers, biomarkers derived from the respiration, electrocardiogram, skin conductance, and skin temperature signals contributed most to the classifier output, thus enabling real-time POTP monitoring using noninvasive, wearable biosensors.