 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical mechanics of extensive-width Bayesian neural networks near interpolation
May 30, 2025For three decades statistical mechanics has been providing a framework to analyse neural networks. However, the theoretically tractable models, e.g., perceptrons, random features models and kernel machines, or multi-index models and committee machines with few neurons, remained simple compared to those used in applications. In this paper we help reducing the gap between practical networks and their theoretical understanding through a statistical physics analysis of the supervised learning of a two-layer fully connected network with generic weight distribution and activation function, whose hidden layer is large but remains proportional to the inputs dimension. This makes it more realistic than infinitely wide networks where no feature learning occurs, but also more expressive than narrow ones or with fixed inner weights. We focus on the Bayes-optimal learning in the teacher-student scenario, i.e., with a dataset generated by another network with the same architecture. We operate around interpolation, where the number of trainable parameters and of data are comparable and feature learning emerges. Our analysis uncovers a rich phenomenology with various learning transitions as the number of data increases. In particular, the more strongly the features (i.e., hidden neurons of the target) contribute to the observed responses, the less data is needed to learn them. Moreover, when the data is scarce, the model only learns non-linear combinations of the teacher weights, rather than "specialising" by aligning its weights with the teacher's. Specialisation occurs only when enough data becomes available, but it can be hard to find for practical training algorithms, possibly due to statistical-to-computational~gaps.
Information-theoretic reduction of deep neural networks to linear models in the overparametrized proportional regime
May 06, 2025We rigorously analyse fully-trained neural networks of arbitrary depth in the Bayesian optimal setting in the so-called proportional scaling regime where the number of training samples and width of the input and all inner layers diverge proportionally. We prove an information-theoretic equivalence between the Bayesian deep neural network model trained from data generated by a teacher with matching architecture, and a simpler model of optimal inference in a generalized linear model. This equivalence enables us to compute the optimal generalization error for deep neural networks in this regime. We thus prove the "deep Gaussian equivalence principle" conjectured in Cui et al. (2023) (arXiv:2302.00375). Our result highlights that in order to escape this "trivialisation" of deep neural networks (in the sense of reduction to a linear model) happening in the strongly overparametrized proportional regime, models trained from much more data have to be considered.
Optimal generalisation and learning transition in extensive-width shallow neural networks near interpolation
Jan 30, 2025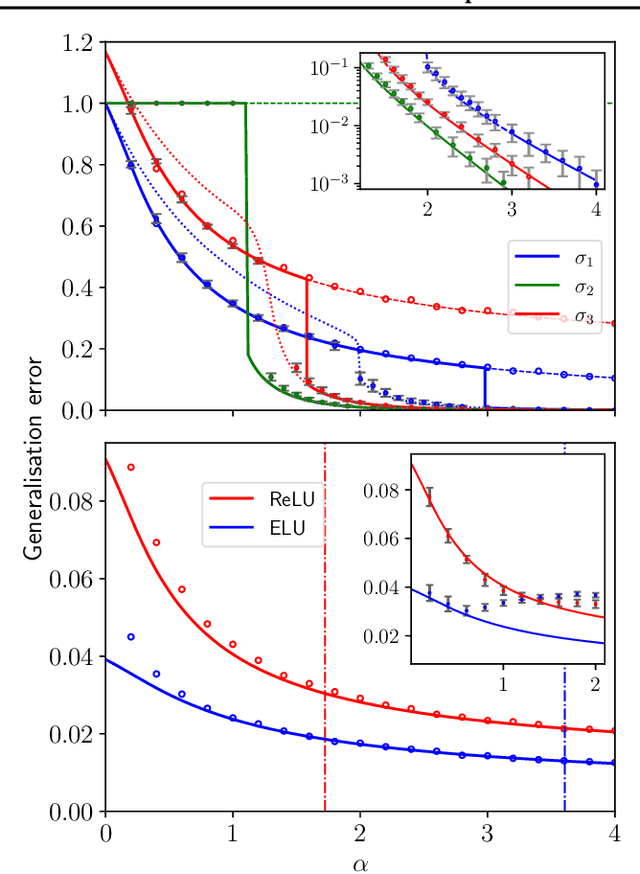

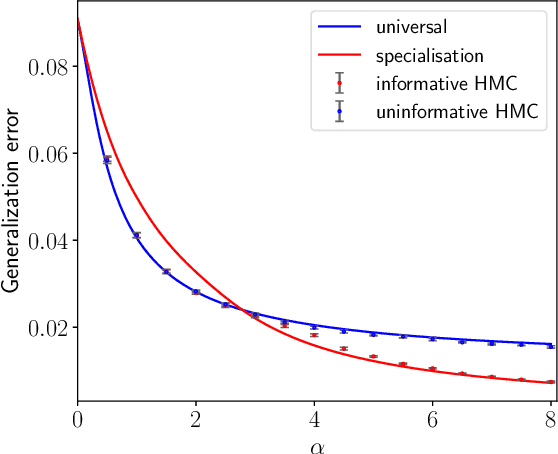
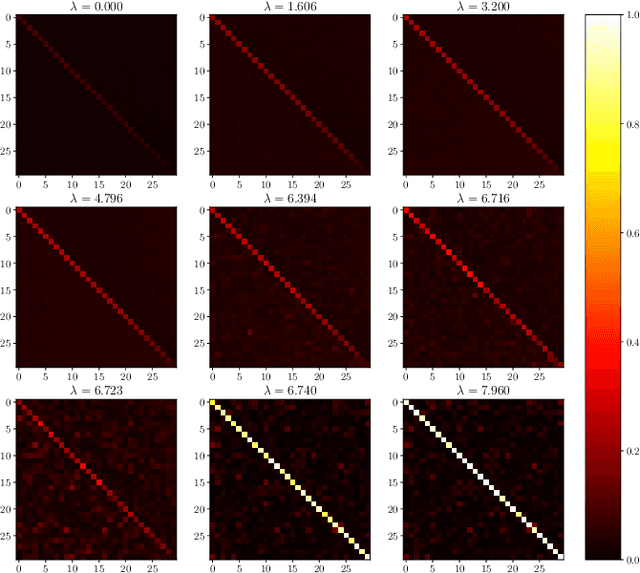
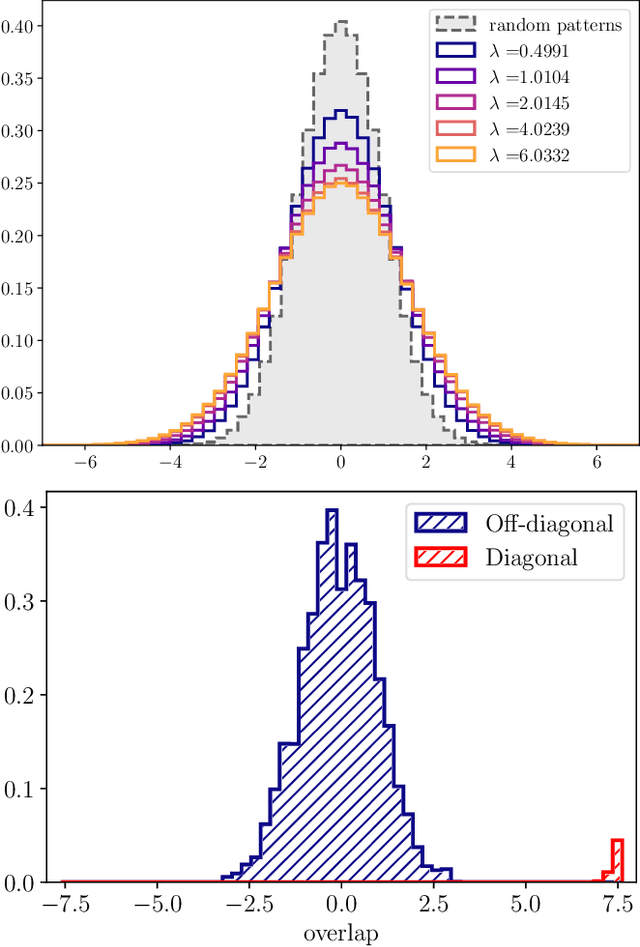
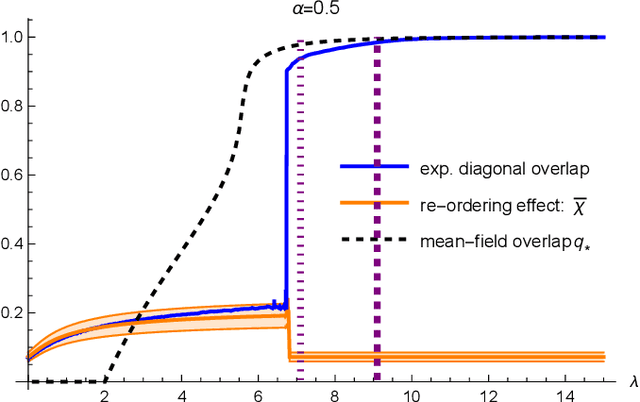
We consider a teacher-student model of supervised learning with a fully-trained 2-layer neural network whose width $k$ and input dimension $d$ are large and proportional. We compute the Bayes-optimal generalisation error of the network for any activation function in the regime where the number of training data $n$ scales quadratically with the input dimension, i.e., around the interpolation threshold where the number of trainable parameters $kd+k$ and of data points $n$ are comparable. Our analysis tackles generic weight distributions. Focusing on binary weights, we uncover a discontinuous phase transition separating a "universal" phase from a "specialisation" phase. In the first, the generalisation error is independent of the weight distribution and decays slowly with the sampling rate $n/d^2$, with the student learning only some non-linear combinations of the teacher weights. In the latter, the error is weight distribution-dependent and decays faster due to the alignment of the student towards the teacher network. We thus unveil the existence of a highly predictive solution near interpolation, which is however potentially hard to find.
On the phase diagram of extensive-rank symmetric matrix denoising beyond rotational invariance
Nov 04, 2024
Matrix denoising is central to signal processing and machine learning. Its analysis when the matrix to infer has a factorised structure with a rank growing proportionally to its dimension remains a challenge, except when it is rotationally invariant. In this case the information theoretic limits and a Bayes-optimal denoising algorithm, called rotational invariant estimator [1,2], are known. Beyond this setting few results can be found. The reason is that the model is not a usual spin system because of the growing rank dimension, nor a matrix model due to the lack of rotation symmetry, but rather a hybrid between the two. In this paper we make progress towards the understanding of Bayesian matrix denoising when the hidden signal is a factored matrix $XX^\intercal$ that is not rotationally invariant. Monte Carlo simulations suggest the existence of a denoising-factorisation transition separating a phase where denoising using the rotational invariant estimator remains Bayes-optimal due to universality properties of the same nature as in random matrix theory, from one where universality breaks down and better denoising is possible by exploiting the signal's prior and factorised structure, though algorithmically hard. We also argue that it is only beyond the transition that factorisation, i.e., estimating $X$ itself, becomes possible up to sign and permutation ambiguities. On the theoretical side, we combine mean-field techniques in an interpretable multiscale fashion in order to access the minimum mean-square error and mutual information. Interestingly, our alternative method yields equations which can be reproduced using the replica approach of [3]. Using numerical insights, we then delimit the portion of the phase diagram where this mean-field theory is reliable, and correct it using universality when it is not. Our ansatz matches well the numerics when accounting for finite size effects.
Information limits and Thouless-Anderson-Palmer equations for spiked matrix models with structured noise
May 31, 2024

We consider a prototypical problem of Bayesian inference for a structured spiked model: a low-rank signal is corrupted by additive noise. While both information-theoretic and algorithmic limits are well understood when the noise is i.i.d. Gaussian, the more realistic case of structured noise still proves to be challenging. To capture the structure while maintaining mathematical tractability, a line of work has focused on rotationally invariant noise. However, existing studies either provide sub-optimal algorithms or they are limited to a special class of noise ensembles. In this paper, we establish the first characterization of the information-theoretic limits for a noise matrix drawn from a general trace ensemble. These limits are then achieved by an efficient algorithm inspired by the theory of adaptive Thouless-Anderson-Palmer (TAP) equations. Our approach leverages tools from statistical physics (replica method) and random matrix theory (generalized spherical integrals), and it unveils the equivalence between the rotationally invariant model and a surrogate Gaussian model.
The Decimation Scheme for Symmetric Matrix Factorization
Jul 31, 2023Matrix factorization is an inference problem that has acquired importance due to its vast range of applications that go from dictionary learning to recommendation systems and machine learning with deep networks. The study of its fundamental statistical limits represents a true challenge, and despite a decade-long history of efforts in the community, there is still no closed formula able to describe its optimal performances in the case where the rank of the matrix scales linearly with its size. In the present paper, we study this extensive rank problem, extending the alternative 'decimation' procedure that we recently introduced, and carry out a thorough study of its performance. Decimation aims at recovering one column/line of the factors at a time, by mapping the problem into a sequence of neural network models of associative memory at a tunable temperature. Though being sub-optimal, decimation has the advantage of being theoretically analyzable. We extend its scope and analysis to two families of matrices. For a large class of compactly supported priors, we show that the replica symmetric free entropy of the neural network models takes a universal form in the low temperature limit. For sparse Ising prior, we show that the storage capacity of the neural network models diverges as sparsity in the patterns increases, and we introduce a simple algorithm based on a ground state search that implements decimation and performs matrix factorization, with no need of an informative initialization.
Fundamental limits of overparametrized shallow neural networks for supervised learning
Jul 11, 2023
We carry out an information-theoretical analysis of a two-layer neural network trained from input-output pairs generated by a teacher network with matching architecture, in overparametrized regimes. Our results come in the form of bounds relating i) the mutual information between training data and network weights, or ii) the Bayes-optimal generalization error, to the same quantities but for a simpler (generalized) linear model for which explicit expressions are rigorously known. Our bounds, which are expressed in terms of the number of training samples, input dimension and number of hidden units, thus yield fundamental performance limits for any neural network (and actually any learning procedure) trained from limited data generated according to our two-layer teacher neural network model. The proof relies on rigorous tools from spin glasses and is guided by ``Gaussian equivalence principles'' lying at the core of numerous recent analyses of neural networks. With respect to the existing literature, which is either non-rigorous or restricted to the case of the learning of the readout weights only, our results are information-theoretic (i.e. are not specific to any learning algorithm) and, importantly, cover a setting where all the network parameters are trained.
Matrix factorization with neural networks
Dec 05, 2022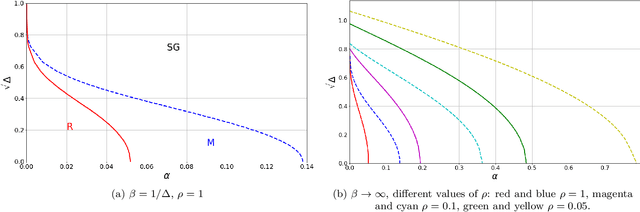
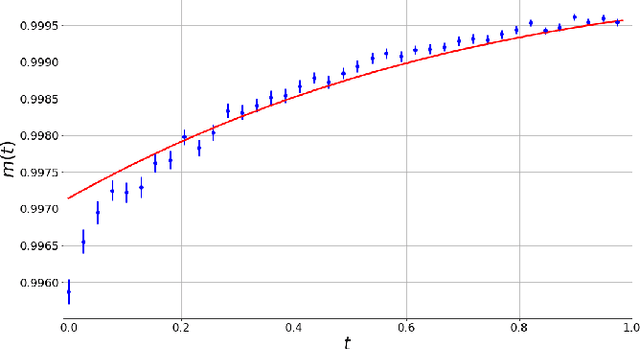
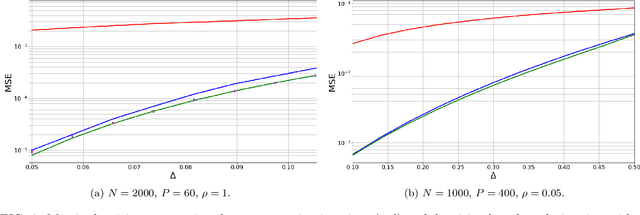
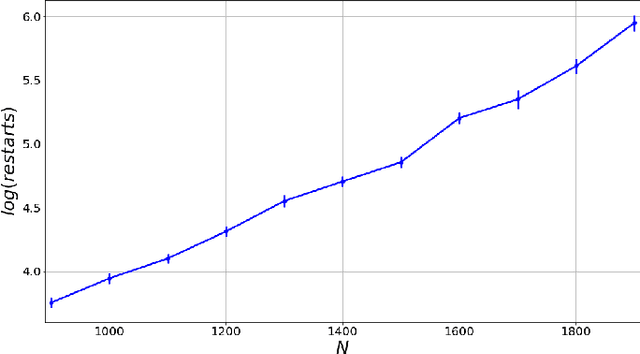
Matrix factorization is an important mathematical problem encountered in the context of dictionary learning, recommendation systems and machine learning. We introduce a new `decimation' scheme that maps it to neural network models of associative memory and provide a detailed theoretical analysis of its performance, showing that decimation is able to factorize extensive-rank matrices and to denoise them efficiently. We introduce a decimation algorithm based on ground-state search of the neural network, which shows performances that match the theoretical prediction.
Bayes-optimal limits in structured PCA, and how to reach them
Oct 03, 2022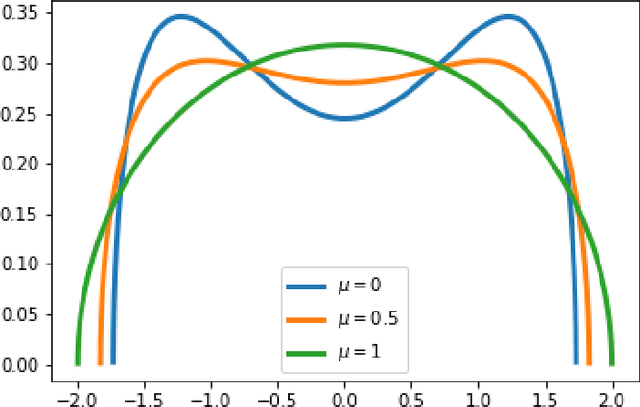
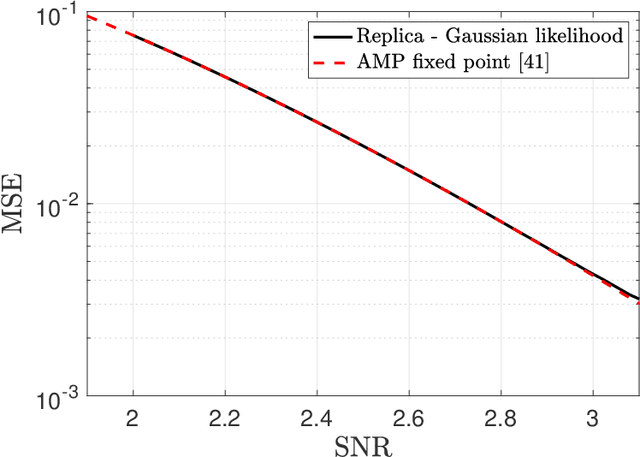

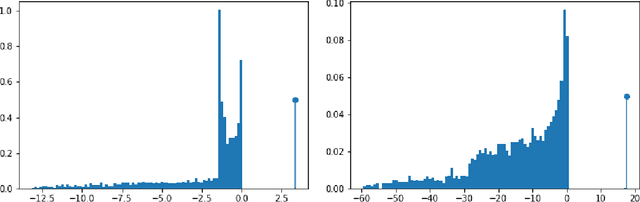
We study the paradigmatic spiked matrix model of principal components analysis, where the rank-one signal is corrupted by additive noise. While the noise is typically taken from a Wigner matrix with independent entries, here the potential acting on the eigenvalues has a quadratic plus a quartic component. The quartic term induces strong correlations between the matrix elements, which makes the setting relevant for applications but analytically challenging. Our work provides the first characterization of the Bayes-optimal limits for inference in this model with structured noise. If the signal prior is rotational-invariant, then we show that a spectral estimator is optimal. In contrast, for more general priors, the existing approximate message passing algorithm (AMP) falls short of achieving the information-theoretic limits, and we provide a justification for this sub-optimality. Finally, by generalizing the theory of Thouless-Anderson-Palmer equations, we cure the issue by proposing a novel AMP which matches the theoretical limits. Our information-theoretic analysis is based on the replica method, a powerful heuristic from statistical mechanics; instead, the novel AMP comes with a rigorous state evolution analysis tracking its performance in the high-dimensional limit. Even if we focus on a specific noise distribution, our methodology can be generalized to a wide class of trace ensembles, at the cost of more involved expressions.