 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical mechanics of extensive-width Bayesian neural networks near interpolation
May 30, 2025For three decades statistical mechanics has been providing a framework to analyse neural networks. However, the theoretically tractable models, e.g., perceptrons, random features models and kernel machines, or multi-index models and committee machines with few neurons, remained simple compared to those used in applications. In this paper we help reducing the gap between practical networks and their theoretical understanding through a statistical physics analysis of the supervised learning of a two-layer fully connected network with generic weight distribution and activation function, whose hidden layer is large but remains proportional to the inputs dimension. This makes it more realistic than infinitely wide networks where no feature learning occurs, but also more expressive than narrow ones or with fixed inner weights. We focus on the Bayes-optimal learning in the teacher-student scenario, i.e., with a dataset generated by another network with the same architecture. We operate around interpolation, where the number of trainable parameters and of data are comparable and feature learning emerges. Our analysis uncovers a rich phenomenology with various learning transitions as the number of data increases. In particular, the more strongly the features (i.e., hidden neurons of the target) contribute to the observed responses, the less data is needed to learn them. Moreover, when the data is scarce, the model only learns non-linear combinations of the teacher weights, rather than "specialising" by aligning its weights with the teacher's. Specialisation occurs only when enough data becomes available, but it can be hard to find for practical training algorithms, possibly due to statistical-to-computational~gaps.
Optimal generalisation and learning transition in extensive-width shallow neural networks near interpolation
Jan 30, 2025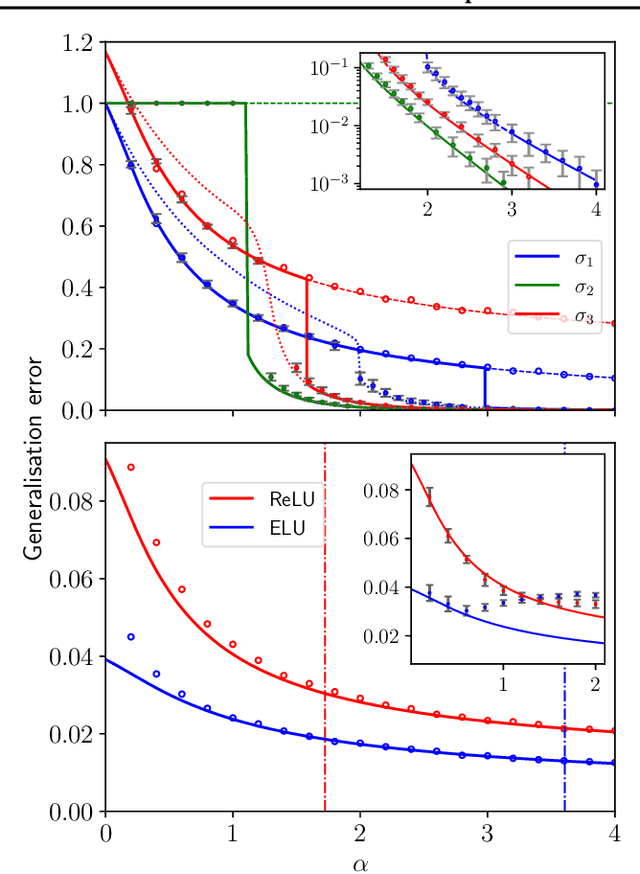

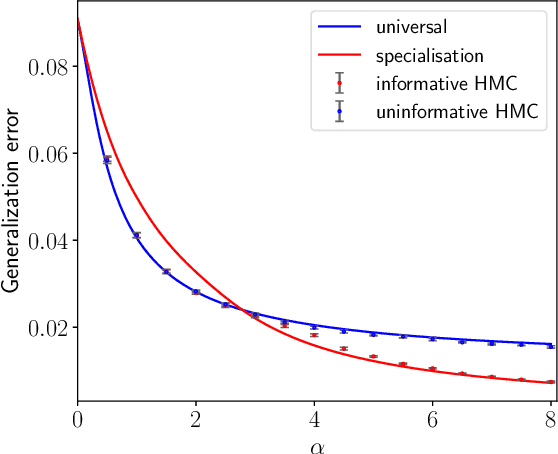
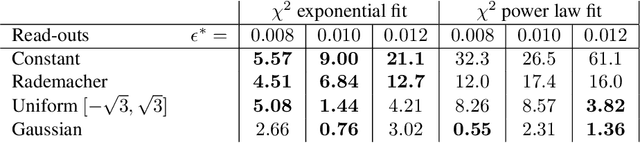
We consider a teacher-student model of supervised learning with a fully-trained 2-layer neural network whose width $k$ and input dimension $d$ are large and proportional. We compute the Bayes-optimal generalisation error of the network for any activation function in the regime where the number of training data $n$ scales quadratically with the input dimension, i.e., around the interpolation threshold where the number of trainable parameters $kd+k$ and of data points $n$ are comparable. Our analysis tackles generic weight distributions. Focusing on binary weights, we uncover a discontinuous phase transition separating a "universal" phase from a "specialisation" phase. In the first, the generalisation error is independent of the weight distribution and decays slowly with the sampling rate $n/d^2$, with the student learning only some non-linear combinations of the teacher weights. In the latter, the error is weight distribution-dependent and decays faster due to the alignment of the student towards the teacher network. We thus unveil the existence of a highly predictive solution near interpolation, which is however potentially hard to find.
Feature learning in finite-width Bayesian deep linear networks with multiple outputs and convolutional layers
Jun 05, 2024Deep linear networks have been extensively studied, as they provide simplified models of deep learning. However, little is known in the case of finite-width architectures with multiple outputs and convolutional layers. In this manuscript, we provide rigorous results for the statistics of functions implemented by the aforementioned class of networks, thus moving closer to a complete characterization of feature learning in the Bayesian setting. Our results include: (i) an exact and elementary non-asymptotic integral representation for the joint prior distribution over the outputs, given in terms of a mixture of Gaussians; (ii) an analytical formula for the posterior distribution in the case of squared error loss function (Gaussian likelihood); (iii) a quantitative description of the feature learning infinite-width regime, using large deviation theory. From a physical perspective, deep architectures with multiple outputs or convolutional layers represent different manifestations of kernel shape renormalization, and our work provides a dictionary that translates this physics intuition and terminology into rigorous Bayesian statistics.
Restoring balance: principled under/oversampling of data for optimal classification
May 15, 2024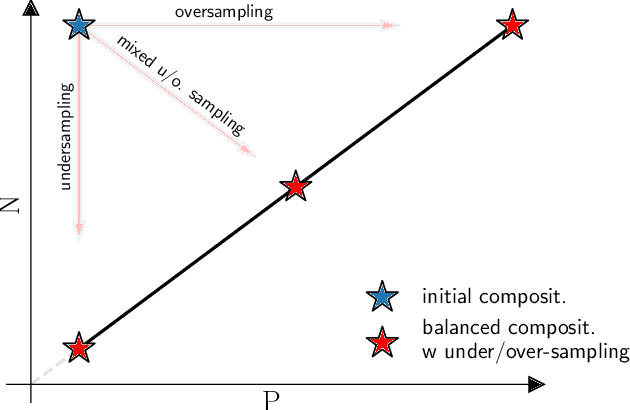


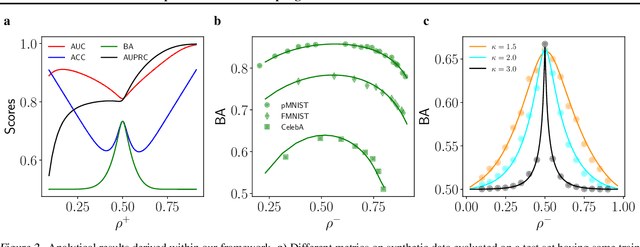
Class imbalance in real-world data poses a common bottleneck for machine learning tasks, since achieving good generalization on under-represented examples is often challenging. Mitigation strategies, such as under or oversampling the data depending on their abundances, are routinely proposed and tested empirically, but how they should adapt to the data statistics remains poorly understood. In this work, we determine exact analytical expressions of the generalization curves in the high-dimensional regime for linear classifiers (Support Vector Machines). We also provide a sharp prediction of the effects of under/oversampling strategies depending on class imbalance, first and second moments of the data, and the metrics of performance considered. We show that mixed strategies involving under and oversampling of data lead to performance improvement. Through numerical experiments, we show the relevance of our theoretical predictions on real datasets, on deeper architectures and with sampling strategies based on unsupervised probabilistic models.
Random features and polynomial rules
Feb 15, 2024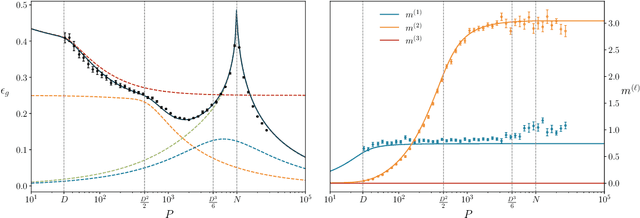

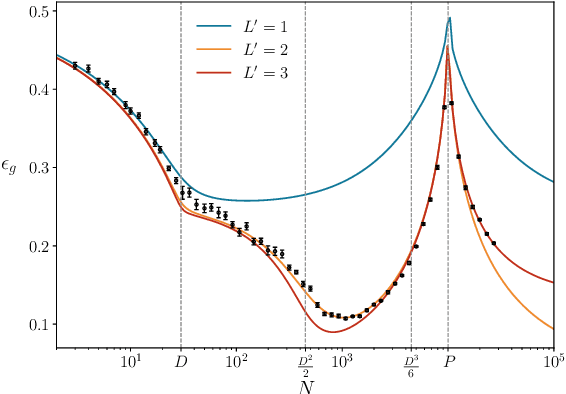
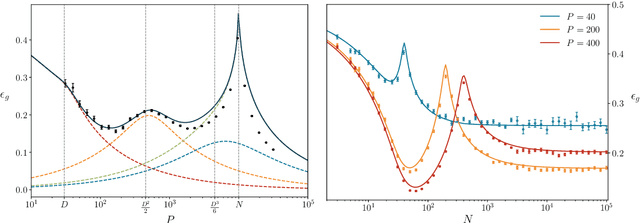
Random features models play a distinguished role in the theory of deep learning, describing the behavior of neural networks close to their infinite-width limit. In this work, we present a thorough analysis of the generalization performance of random features models for generic supervised learning problems with Gaussian data. Our approach, built with tools from the statistical mechanics of disordered systems, maps the random features model to an equivalent polynomial model, and allows us to plot average generalization curves as functions of the two main control parameters of the problem: the number of random features $N$ and the size $P$ of the training set, both assumed to scale as powers in the input dimension $D$. Our results extend the case of proportional scaling between $N$, $P$ and $D$. They are in accordance with rigorous bounds known for certain particular learning tasks and are in quantitative agreement with numerical experiments performed over many order of magnitudes of $N$ and $P$. We find good agreement also far from the asymptotic limits where $D\to \infty$ and at least one between $P/D^K$, $N/D^L$ remains finite.
Beyond the storage capacity: data driven satisfiability transition
May 20, 2020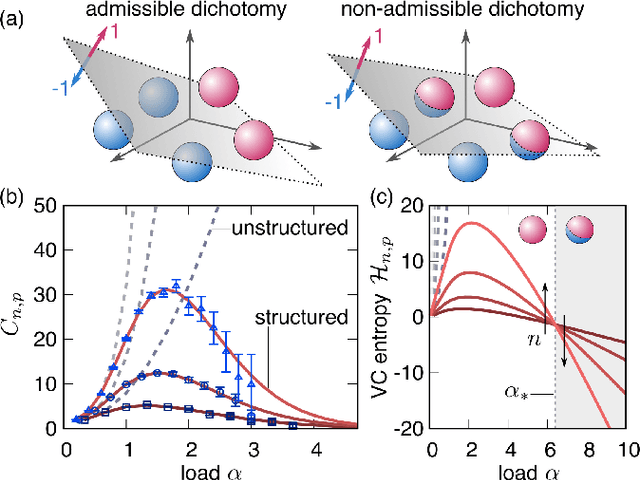
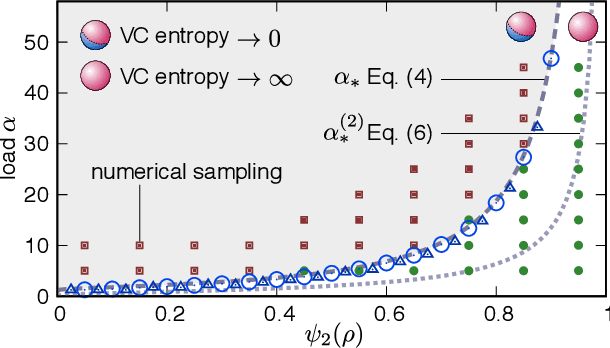
Data structure has a dramatic impact on the properties of neural networks, yet its significance in the established theoretical frameworks is poorly understood. Here we compute the Vapnik-Chervonenkis entropy of a kernel machine operating on data grouped into equally labelled subsets. At variance with the unstructured scenario, entropy is non-monotonic in the size of the training set, and displays an additional critical point besides the storage capacity. Remarkably, the same behavior occurs in margin classifiers even with randomly labelled data, as is elucidated by identifying the synaptic volume encoding the transition. These findings reveal aspects of expressivity lying beyond the condensed description provided by the storage capacity, and they indicate the path towards more realistic bounds for the generalization error of neural networks.