 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow transformers learn structured data: insights from hierarchical filtering
Aug 27, 2024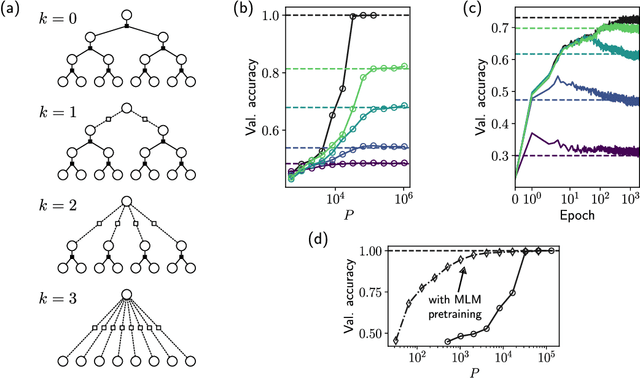
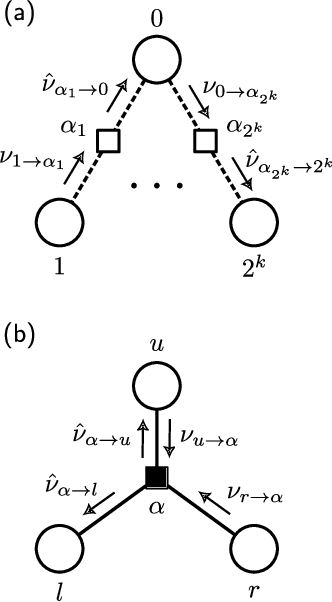
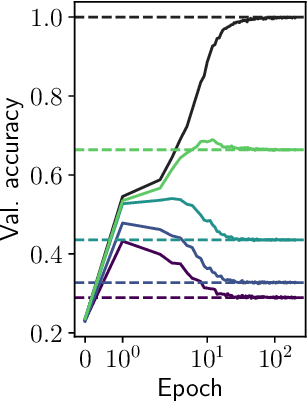

We introduce a hierarchical filtering procedure for generative models of sequences on trees, enabling control over the range of positional correlations in the data. Leveraging this controlled setting, we provide evidence that vanilla encoder-only transformer architectures can implement the optimal Belief Propagation algorithm on both root classification and masked language modeling tasks. Correlations at larger distances corresponding to increasing layers of the hierarchy are sequentially included as the network is trained. We analyze how the transformer layers succeed by focusing on attention maps from models trained with varying degrees of filtering. These attention maps show clear evidence for iterative hierarchical reconstruction of correlations, and we can relate these observations to a plausible implementation of the exact inference algorithm for the network sizes considered.