 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal transfer protocol by incremental layer defrosting
Paper and Code
Mar 02, 2023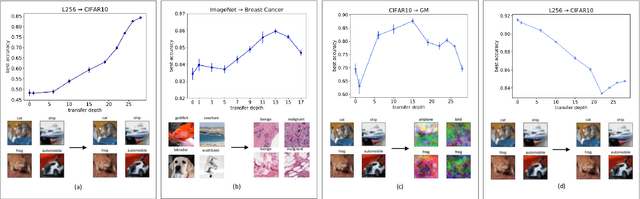
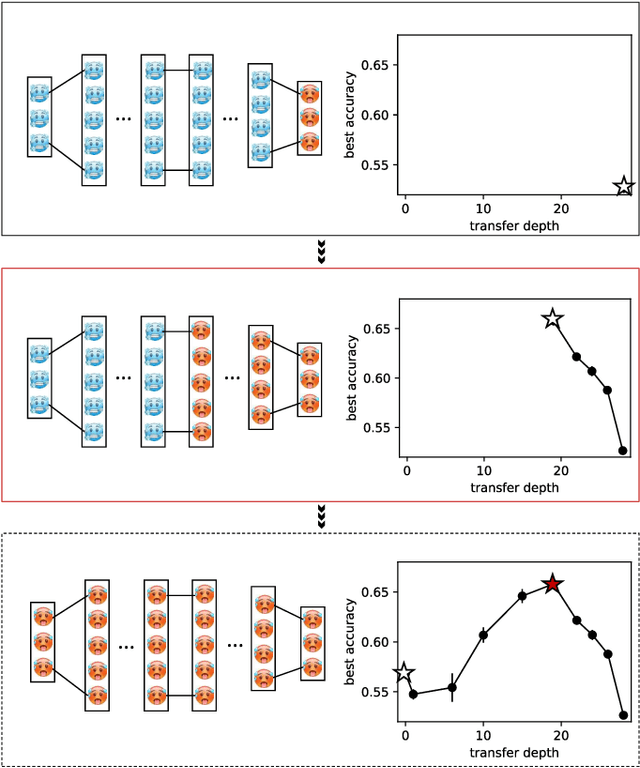
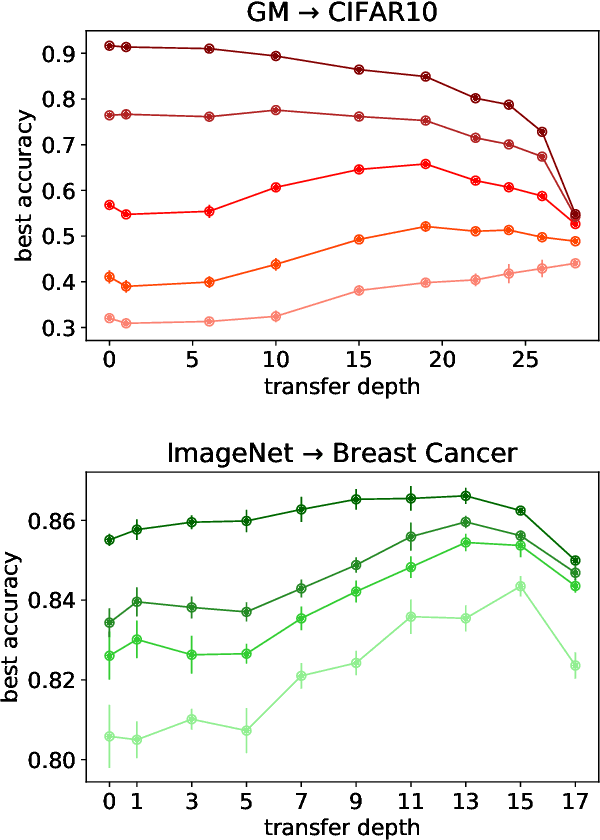
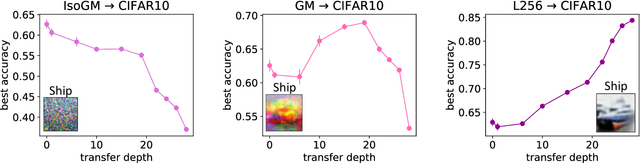
Transfer learning is a powerful tool enabling model training with limited amounts of data. This technique is particularly useful in real-world problems where data availability is often a serious limitation. The simplest transfer learning protocol is based on ``freezing" the feature-extractor layers of a network pre-trained on a data-rich source task, and then adapting only the last layers to a data-poor target task. This workflow is based on the assumption that the feature maps of the pre-trained model are qualitatively similar to the ones that would have been learned with enough data on the target task. In this work, we show that this protocol is often sub-optimal, and the largest performance gain may be achieved when smaller portions of the pre-trained network are kept frozen. In particular, we make use of a controlled framework to identify the optimal transfer depth, which turns out to depend non-trivially on the amount of available training data and on the degree of source-target task correlation. We then characterize transfer optimality by analyzing the internal representations of two networks trained from scratch on the source and the target task through multiple established similarity measures.