 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Pedestrian Crossing Intention from Egocentric Vision via Vision Language Models
Jun 08, 2026Egocentric vision offers a first-person view of human perception and decision making, yet its potential for traffic-safety prediction remains underexplored. In this work, we study the decoding of pedestrian crossing intentions from short egocentric video clips. We approach this by formulating the task as a closed-ended visual question answering (VQA) problem and leveraging vision language models (VLMs) to predict the pedestrians' intent. We first benchmark three families of state-of-the-art VLMs in a zero-shot setting, finding that they achieve moderate gains over random guessing but exhibit limited higher-level traffic reasoning. Motivated by these findings, we further adapt VLMs to the target task using parameter-efficient fine-tuning. Our results show that the fine-tuned models substantially outperform their zero-shot counterparts and achieve a 9\% accuracy improvement over a specialized transformer-based baseline. Finally, we demonstrate that incorporating additional contextual cues, including ego motion, vehicle motion, and eye gaze, further improves predictive performance. In particular, the fine-tuned Qwen3-VL-2B model guided by eye gaze and ego motion achieves a 14.5% accuracy improvement over the transformer baseline, establishing a new state of the art for egocentric pedestrian intent decoding.
Eye Gaze-Informed and Context-Aware Pedestrian Trajectory Prediction in Shared Spaces with Automated Shuttles: A Virtual Reality Study
Mar 20, 2026The integration of Automated Shuttles into shared urban spaces presents unique challenges due to the absence of traffic rules and the complex pedestrian interactions. Accurately anticipating pedestrian behavior in such unstructured environments is therefore critical for ensuring both safety and efficiency. This paper presents a Virtual Reality (VR) study that captures how pedestrians interact with automated shuttles across diverse scenarios, including varying approach angles and navigating in continuous traffic. We identify critical behavior patterns present in pedestrians' decision-making in shared spaces, including hesitation, evasive maneuvers, gaze allocation, and proxemic adjustments. To model pedestrian behavior, we propose GazeX-LSTM, a multimodal eye gaze-informed and context-aware prediction model that integrates pedestrians' trajectories, fine-grained eye gaze dynamics, and contextual factors. We shift prediction from a vehicle- to a human-centered perspective by leveraging eye-tracking data to capture pedestrian attention. We systematically validate the unique and irreplaceable predictive power of eye gaze over head orientation alone, further enhancing performance by integrating contextual variables. Notably, the combination of eye gaze data and contextual information produces super-additive improvements on pedestrian behavior prediction accuracy, revealing the complementary relationship between visual attention and situational contexts. Together, our findings provide the first evidence that eye gaze-informed modeling fundamentally advances pedestrian behavior prediction and highlight the critical role of situational contexts in shared-space interactions. This paves the way for safer and more adaptive automated vehicle technologies that account for how people perceive and act in complex shared spaces.
Motion Style Transfer: Modular Low-Rank Adaptation for Deep Motion Forecasting
Nov 06, 2022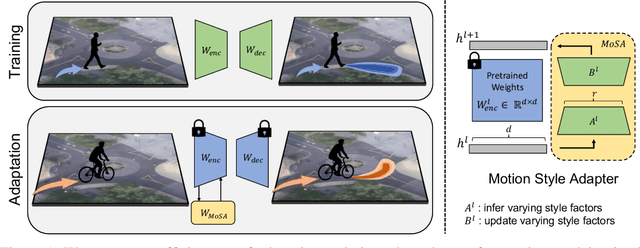
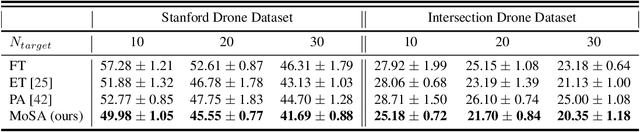
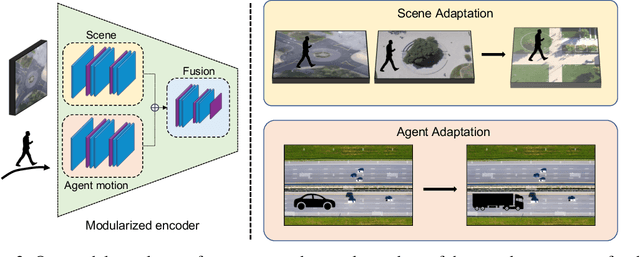

Deep motion forecasting models have achieved great success when trained on a massive amount of data. Yet, they often perform poorly when training data is limited. To address this challenge, we propose a transfer learning approach for efficiently adapting pre-trained forecasting models to new domains, such as unseen agent types and scene contexts. Unlike the conventional fine-tuning approach that updates the whole encoder, our main idea is to reduce the amount of tunable parameters that can precisely account for the target domain-specific motion style. To this end, we introduce two components that exploit our prior knowledge of motion style shifts: (i) a low-rank motion style adapter that projects and adjusts the style features at a low-dimensional bottleneck; and (ii) a modular adapter strategy that disentangles the features of scene context and motion history to facilitate a fine-grained choice of adaptation layers. Through extensive experimentation, we show that our proposed adapter design, coined MoSA, outperforms prior methods on several forecasting benchmarks.
Using Machine Learning to generate an open-access cropland map from satellite images time series in the Indian Himalayan Region
Mar 28, 2022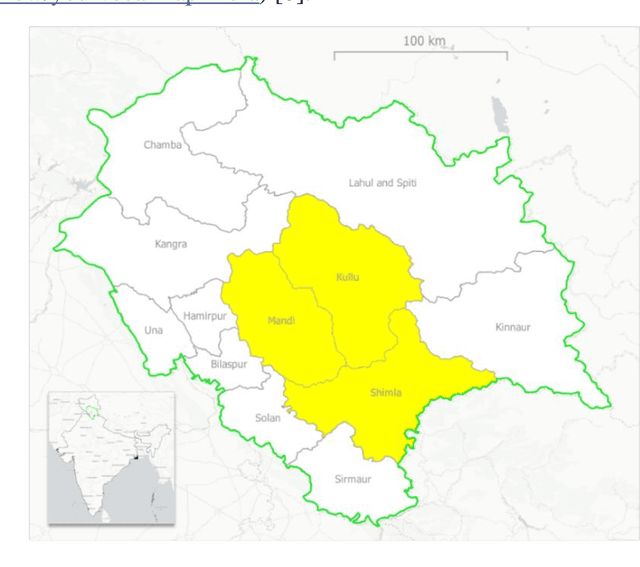
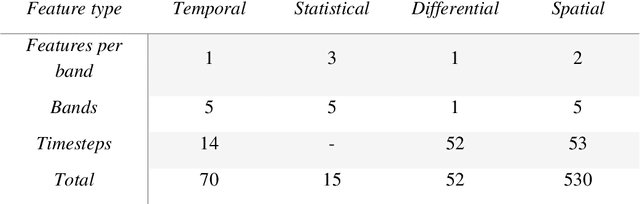
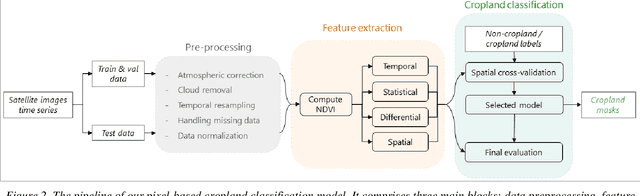
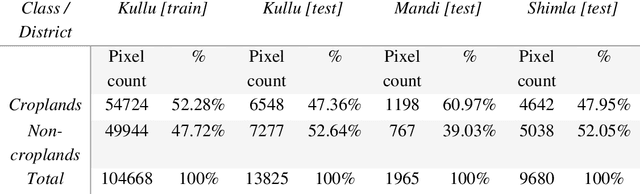
Crop maps are crucial for agricultural monitoring and food management and can additionally support domain-specific applications, such as setting cold supply chain infrastructure in developing countries. Machine learning (ML) models, combined with freely-available satellite imagery, can be used to produce cost-effective and high spatial-resolution crop maps. However, accessing ground truth data for supervised learning is especially challenging in developing countries due to factors such as smallholding and fragmented geography, which often results in a lack of crop type maps or even reliable cropland maps. Our area of interest for this study lies in Himachal Pradesh, India, where we aim at producing an open-access binary cropland map at 10-meter resolution for the Kullu, Shimla, and Mandi districts. To this end, we developed an ML pipeline that relies on Sentinel-2 satellite images time series. We investigated two pixel-based supervised classifiers, support vector machines (SVM) and random forest (RF), which are used to classify per-pixel time series for binary cropland mapping. The ground truth data used for training, validation and testing was manually annotated from a combination of field survey reference points and visual interpretation of very high resolution (VHR) imagery. We trained and validated the models via spatial cross-validation to account for local spatial autocorrelation and selected the RF model due to overall robustness and lower computational cost. We tested the generalization capability of the chosen model at the pixel level by computing the accuracy, recall, precision, and F1-score on hold-out test sets of each district, achieving an average accuracy for the RF (our best model) of 87%. We used this model to generate a cropland map for three districts of Himachal Pradesh, spanning 14,600 km2, which improves the resolution and quality of existing public maps.