 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitated machine learning for image-based fruit quality assessment in developing countries
Paper and Code

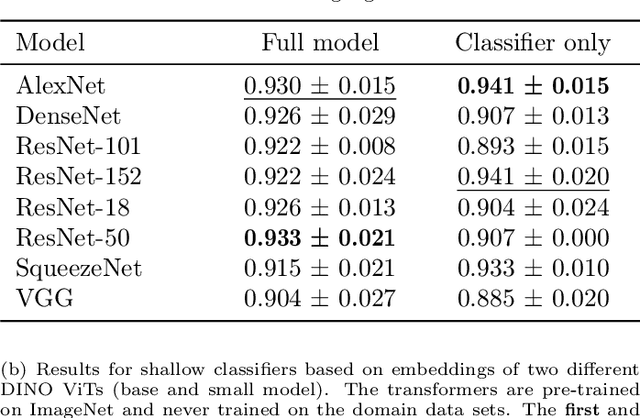
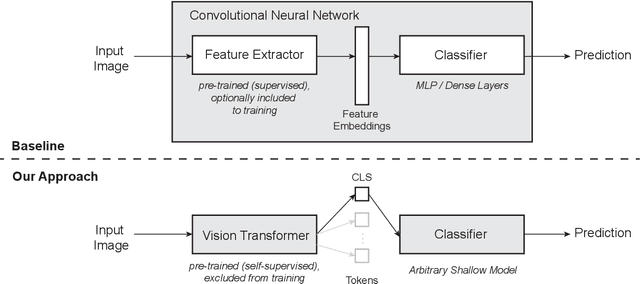
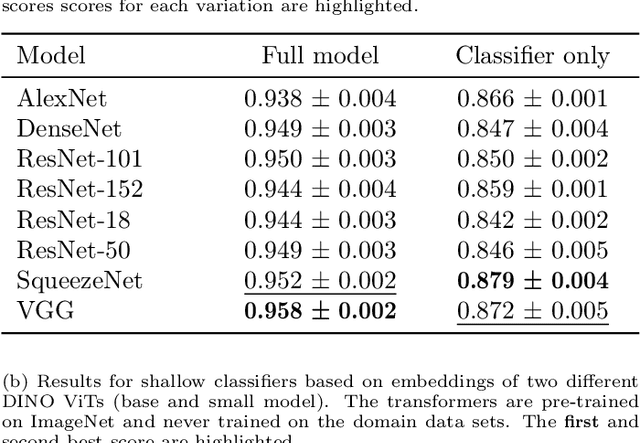
Automated image classification is a common task for supervised machine learning in food science. An example is the image-based classification of the fruit's external quality or ripeness. For this purpose, deep convolutional neural networks (CNNs) are typically used. These models usually require a large number of labeled training samples and enhanced computational resources. While commercial fruit sorting lines readily meet these requirements, the use of machine learning approaches can be hindered by these prerequisites, especially for smallholder farmers in the developing world. We propose an alternative method based on pre-trained vision transformers (ViTs) that is particularly suitable for domains with low availability of data and limited computational resources. It can be easily implemented with limited resources on a standard device, which can democratize the use of these models for smartphone-based image classification in developing countries. We demonstrate the competitiveness of our method by benchmarking two different classification tasks on domain data sets of banana and apple fruits with well-established CNN approaches. Our method achieves a classification accuracy of less than one percent below the best-performing CNN (0.950 vs. 0.958) on a training data set of 3745 images. At the same time, our method is superior when only a small number of labeled training samples is available. It requires three times less data to achieve a 0.90 accuracy compared to CNNs. In addition, visualizations of low-dimensional feature embeddings show that the model used in our study extracts excellent features from unseen data without allocating labels.