 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalize Filters! Classical Wisdom for Deep Vision
Jun 04, 2025Classical image filters, such as those for averaging or differencing, are carefully normalized to ensure consistency, interpretability, and to avoid artifacts like intensity shifts, halos, or ringing. In contrast, convolutional filters learned end-to-end in deep networks lack such constraints. Although they may resemble wavelets and blob/edge detectors, they are not normalized in the same or any way. Consequently, when images undergo atmospheric transfer, their responses become distorted, leading to incorrect outcomes. We address this limitation by proposing filter normalization, followed by learnable scaling and shifting, akin to batch normalization. This simple yet effective modification ensures that the filters are atmosphere-equivariant, enabling co-domain symmetry. By integrating classical filtering principles into deep learning (applicable to both convolutional neural networks and convolution-dependent vision transformers), our method achieves significant improvements on artificial and natural intensity variation benchmarks. Our ResNet34 could even outperform CLIP by a large margin. Our analysis reveals that unnormalized filters degrade performance, whereas filter normalization regularizes learning, promotes diversity, and improves robustness and generalization.
Human in-the-Loop Estimation of Cluster Count in Datasets via Similarity-Driven Nested Importance Sampling
Dec 08, 2023Identifying the number of clusters serves as a preliminary goal for many data analysis tasks. A common approach to this problem is to vary the number of clusters in a clustering algorithm (e.g., 'k' in $k$-means) and pick the value that best explains the data. However, the count estimates can be unreliable especially when the image similarity is poor. Human feedback on the pairwise similarity can be used to improve the clustering, but existing approaches do not guarantee accurate count estimates. We propose an approach to produce estimates of the cluster counts in a large dataset given an approximate pairwise similarity. Our framework samples edges guided by the pairwise similarity, and we collect human feedback to construct a statistical estimate of the cluster count. On the technical front we have developed a nested importance sampling approach that yields (asymptotically) unbiased estimates of the cluster count with confidence intervals which can guide human effort. Compared to naive sampling, our similarity-driven sampling produces more accurate estimates of counts and tighter confidence intervals. We evaluate our method on a benchmark of six fine-grained image classification datasets achieving low error rates on the estimated number of clusters with significantly less human labeling effort compared to baselines and alternative active clustering approaches.
DISCount: Counting in Large Image Collections with Detector-Based Importance Sampling
Jun 05, 2023



Many modern applications use computer vision to detect and count objects in massive image collections. However, when the detection task is very difficult or in the presence of domain shifts, the counts may be inaccurate even with significant investments in training data and model development. We propose DISCount -- a detector-based importance sampling framework for counting in large image collections that integrates an imperfect detector with human-in-the-loop screening to produce unbiased estimates of counts. We propose techniques for solving counting problems over multiple spatial or temporal regions using a small number of screened samples and estimate confidence intervals. This enables end-users to stop screening when estimates are sufficiently accurate, which is often the goal in a scientific study. On the technical side we develop variance reduction techniques based on control variates and prove the (conditional) unbiasedness of the estimators. DISCount leads to a 9-12x reduction in the labeling costs over naive screening for tasks we consider, such as counting birds in radar imagery or estimating damaged buildings in satellite imagery, and also surpasses alternative covariate-based screening approaches in efficiency.
Domain Adaptor Networks for Hyperspectral Image Recognition
Aug 03, 2021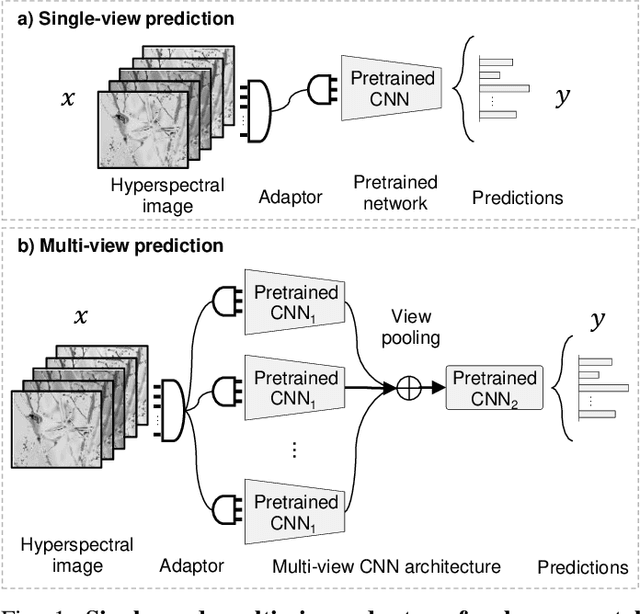


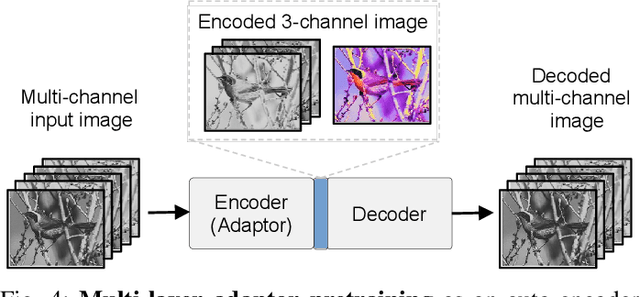
We consider the problem of adapting a network trained on three-channel color images to a hyperspectral domain with a large number of channels. To this end, we propose domain adaptor networks that map the input to be compatible with a network trained on large-scale color image datasets such as ImageNet. Adaptors enable learning on small hyperspectral datasets where training a network from scratch may not be effective. We investigate architectures and strategies for training adaptors and evaluate them on a benchmark consisting of multiple hyperspectral datasets. We find that simple schemes such as linear projection or subset selection are often the most effective, but can lead to a loss in performance in some cases. We also propose a novel multi-view adaptor where of the inputs are combined in an intermediate layer of the network in an order invariant manner that provides further improvements. We present extensive experiments by varying the number of training examples in the benchmark to characterize the accuracy and computational trade-offs offered by these adaptors.
StarcNet: Machine Learning for Star Cluster Identification
Dec 16, 2020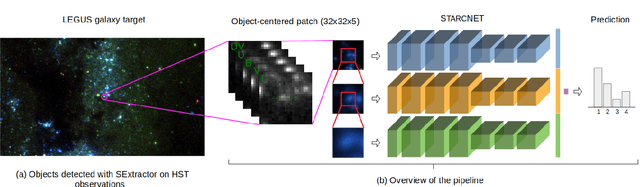

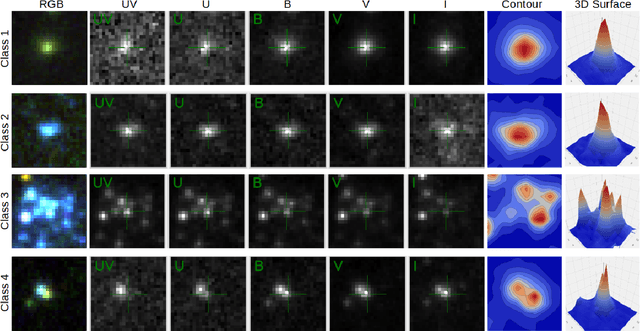

We present a machine learning (ML) pipeline to identify star clusters in the multi{color images of nearby galaxies, from observations obtained with the Hubble Space Telescope as part of the Treasury Project LEGUS (Legacy ExtraGalactic Ultraviolet Survey). StarcNet (STAR Cluster classification NETwork) is a multi-scale convolutional neural network (CNN) which achieves an accuracy of 68.6% (4 classes)/86.0% (2 classes: cluster/non-cluster) for star cluster classification in the images of the LEGUS galaxies, nearly matching human expert performance. We test the performance of StarcNet by applying pre-trained CNN model to galaxies not included in the training set, finding accuracies similar to the reference one. We test the effect of StarcNet predictions on the inferred cluster properties by comparing multi-color luminosity functions and mass-age plots from catalogs produced by StarcNet and by human-labeling; distributions in luminosity, color, and physical characteristics of star clusters are similar for the human and ML classified samples. There are two advantages to the ML approach: (1) reproducibility of the classifications: the ML algorithm's biases are fixed and can be measured for subsequent analysis; and (2) speed of classification: the algorithm requires minutes for tasks that humans require weeks to months to perform. By achieving comparable accuracy to human classifiers, StarcNet will enable extending classifications to a larger number of candidate samples than currently available, thus increasing significantly the statistics for cluster studies.