 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a biologically more accurate spider robot to study active vibration sensing
Jan 23, 2026Orb-weaving spiders detect prey on a web using vibration sensors at leg joints. They often dynamically crouch their legs during prey sensing, likely an active sensing strategy. However, how leg crouching enhances sensing is poorly understood, because measuring system vibrations in behaving animals is difficult. We use robophysical modeling to study this problem. Our previous spider robot had only four legs, simplified leg morphology, and a shallow crouching range of motion. Here, we developed a new spider robot, with eight legs, each with four joints that better approximated spider leg morphology. Leg exoskeletons were 3-D printed and joint stiffness was tuned using integrated silicone molding with variable materials and geometry. Tendon-driven actuation allowed a motor in the body to crouch all eight legs deeply as spiders do, while accelerometers at leg joints record leg vibrations. Experiments showed that our new spider robot reproduced key vibration features observed in the previous robot while improving biological accuracy. Our new robot provides a biologically more accurate robophysical model for studying how leg behaviors modulate vibration sensing on a web.
A Survey of AI Methods for Geometry Preparation and Mesh Generation in Engineering Simulation
Dec 16, 2025Artificial intelligence is beginning to ease long-standing bottlenecks in the CAD-to-mesh pipeline. This survey reviews recent advances where machine learning aids part classification, mesh quality prediction, and defeaturing. We explore methods that improve unstructured and block-structured meshing, support volumetric parameterizations, and accelerate parallel mesh generation. We also examine emerging tools for scripting automation, including reinforcement learning and large language models. Across these efforts, AI acts as an assistive technology, extending the capabilities of traditional geometry and meshing tools. The survey highlights representative methods, practical deployments, and key research challenges that will shape the next generation of data-driven meshing workflows.
BOTS-LM: Training Large Language Models for Setswana
Aug 05, 2024In this work we present BOTS-LM, a series of bilingual language models proficient in both Setswana and English. Leveraging recent advancements in data availability and efficient fine-tuning, BOTS-LM achieves performance similar to models significantly larger than itself while maintaining computational efficiency. Our initial release features an 8 billion parameter generative large language model, with upcoming 0.5 billion and 1 billion parameter large language models and a 278 million parameter encoder-only model soon to be released. We find the 8 billion parameter model significantly outperforms Llama-3-70B and Aya 23 on English-Setswana translation tasks, approaching the performance of dedicated machine translation models, while approaching 70B parameter performance on Setswana reasoning as measured by a machine translated subset of the MMLU benchmark. To accompany the BOTS-LM series of language models, we release the largest Setswana web dataset, SetsText, totalling over 267 million tokens. In addition, we release the largest machine translated Setswana dataset, the first and largest synthetic Setswana dataset, training and evaluation code, training logs, and MMLU-tsn, a machine translated subset of MMLU.
Efficient Transformer Knowledge Distillation: A Performance Review
Nov 22, 2023As pretrained transformer language models continue to achieve state-of-the-art performance, the Natural Language Processing community has pushed for advances in model compression and efficient attention mechanisms to address high computational requirements and limited input sequence length. Despite these separate efforts, no investigation has been done into the intersection of these two fields. In this work, we provide an evaluation of model compression via knowledge distillation on efficient attention transformers. We provide cost-performance trade-offs for the compression of state-of-the-art efficient attention architectures and the gains made in performance in comparison to their full attention counterparts. Furthermore, we introduce a new long-context Named Entity Recognition dataset, GONERD, to train and test the performance of NER models on long sequences. We find that distilled efficient attention transformers can preserve a significant amount of original model performance, preserving up to 98.6% across short-context tasks (GLUE, SQUAD, CoNLL-2003), up to 94.6% across long-context Question-and-Answering tasks (HotpotQA, TriviaQA), and up to 98.8% on long-context Named Entity Recognition (GONERD), while decreasing inference times by up to 57.8%. We find that, for most models on most tasks, performing knowledge distillation is an effective method to yield high-performing efficient attention models with low costs.
GuacaMol: Benchmarking Models for De Novo Molecular Design
Nov 22, 2018

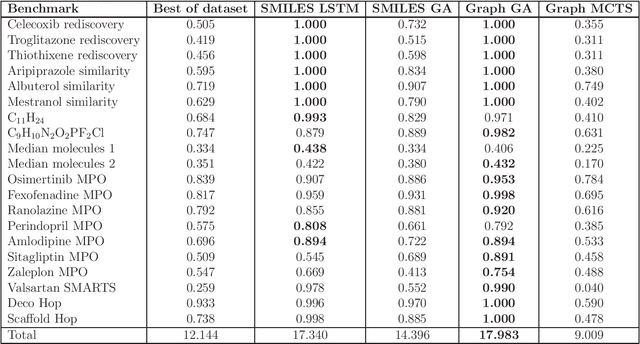
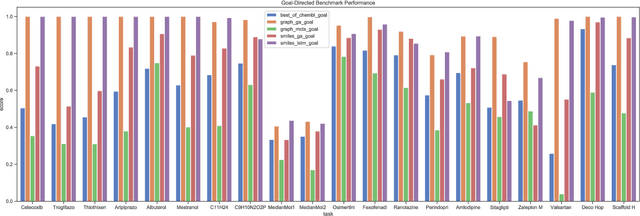
De novo design seeks to generate molecules with required property profiles by virtual design-make-test cycles. With the emergence of deep learning and neural generative models in many application areas, models for molecular design based on neural networks appeared recently and show promising results. However, the new models have not been profiled on consistent tasks, and comparative studies to well-established algorithms have only seldom been performed. To standardize the assessment of both classical and neural models for de novo molecular design, we propose an evaluation framework, GuacaMol, based on a suite of standardized benchmarks. The benchmark tasks encompass measuring the fidelity of the models to reproduce the property distribution of the training sets, the ability to generate novel molecules, the exploration and exploitation of chemical space, and a variety of single and multi-objective optimization tasks. The benchmarking framework is available as an open-source Python package.