 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoften to Defend: Towards Adversarial Robustness via Self-Guided Label Refinement
Mar 14, 2024Adversarial training (AT) is currently one of the most effective ways to obtain the robustness of deep neural networks against adversarial attacks. However, most AT methods suffer from robust overfitting, i.e., a significant generalization gap in adversarial robustness between the training and testing curves. In this paper, we first identify a connection between robust overfitting and the excessive memorization of noisy labels in AT from a view of gradient norm. As such label noise is mainly caused by a distribution mismatch and improper label assignments, we are motivated to propose a label refinement approach for AT. Specifically, our Self-Guided Label Refinement first self-refines a more accurate and informative label distribution from over-confident hard labels, and then it calibrates the training by dynamically incorporating knowledge from self-distilled models into the current model and thus requiring no external teachers. Empirical results demonstrate that our method can simultaneously boost the standard accuracy and robust performance across multiple benchmark datasets, attack types, and architectures. In addition, we also provide a set of analyses from the perspectives of information theory to dive into our method and suggest the importance of soft labels for robust generalization.
On the Diversity and Realism of Distilled Dataset: An Efficient Dataset Distillation Paradigm
Dec 06, 2023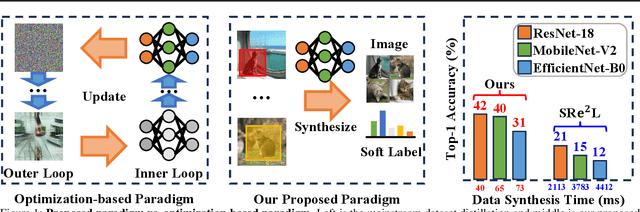
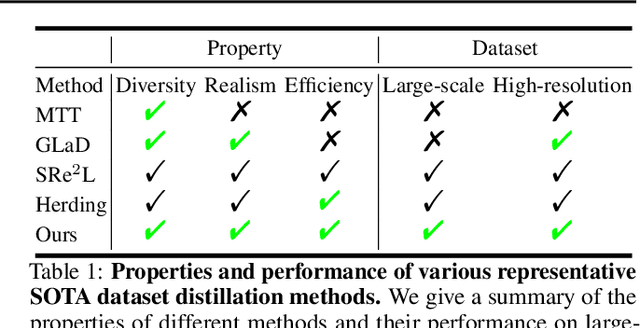

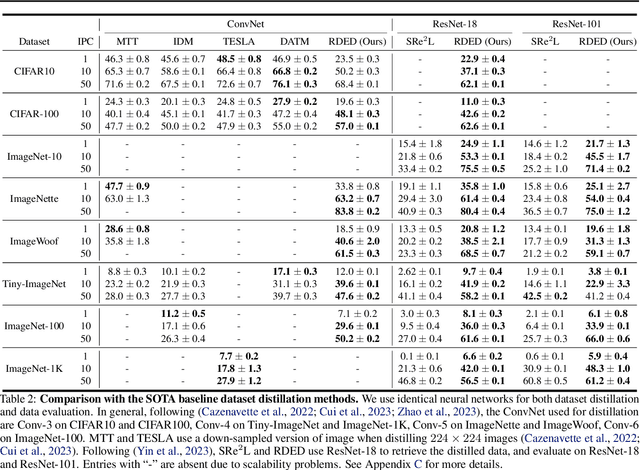
Contemporary machine learning requires training large neural networks on massive datasets and thus faces the challenges of high computational demands. Dataset distillation, as a recent emerging strategy, aims to compress real-world datasets for efficient training. However, this line of research currently struggle with large-scale and high-resolution datasets, hindering its practicality and feasibility. To this end, we re-examine the existing dataset distillation methods and identify three properties required for large-scale real-world applications, namely, realism, diversity, and efficiency. As a remedy, we propose RDED, a novel computationally-efficient yet effective data distillation paradigm, to enable both diversity and realism of the distilled data. Extensive empirical results over various neural architectures and datasets demonstrate the advancement of RDED: we can distill the full ImageNet-1K to a small dataset comprising 10 images per class within 7 minutes, achieving a notable 42% top-1 accuracy with ResNet-18 on a single RTX-4090 GPU (while the SOTA only achieves 21% but requires 6 hours).
Stable and Efficient Adversarial Training through Local Linearization
Oct 11, 2022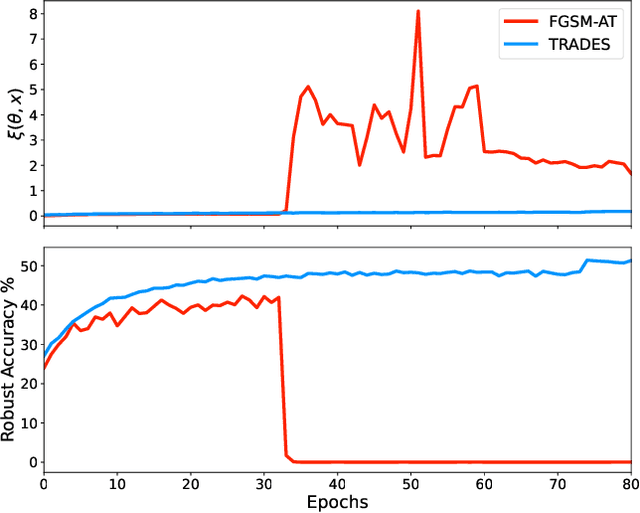

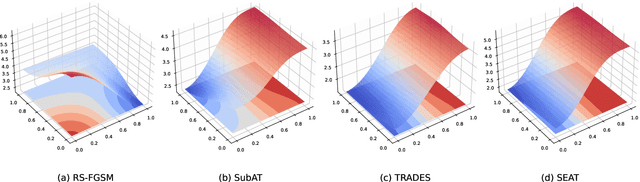
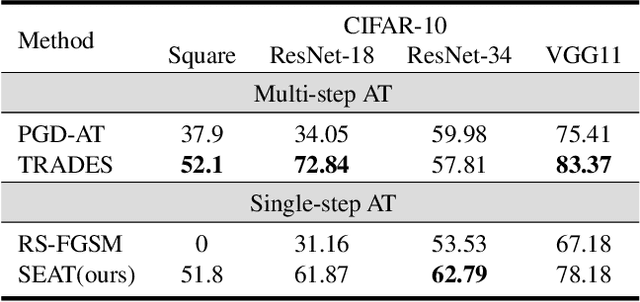
There has been a recent surge in single-step adversarial training as it shows robustness and efficiency. However, a phenomenon referred to as ``catastrophic overfitting" has been observed, which is prevalent in single-step defenses and may frustrate attempts to use FGSM adversarial training. To address this issue, we propose a novel method, Stable and Efficient Adversarial Training (SEAT), which mitigates catastrophic overfitting by harnessing on local properties that distinguish a robust model from that of a catastrophic overfitted model. The proposed SEAT has strong theoretical justifications, in that minimizing the SEAT loss can be shown to favour smooth empirical risk, thereby leading to robustness. Experimental results demonstrate that the proposed method successfully mitigates catastrophic overfitting, yielding superior performance amongst efficient defenses. Our single-step method can reach 51% robust accuracy for CIFAR-10 with $l_\infty$ perturbations of radius $8/255$ under a strong PGD-50 attack, matching the performance of a 10-step iterative adversarial training at merely 3% computational cost.