 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAR: Towards Beam-Search-Aware Optimization for Recommendation with Large Language Models
Jan 30, 2026Recent years have witnessed a rapid surge in research leveraging Large Language Models (LLMs) for recommendation. These methods typically employ supervised fine-tuning (SFT) to adapt LLMs to recommendation scenarios, and utilize beam search during inference to efficiently retrieve $B$ top-ranked recommended items. However, we identify a critical training-inference inconsistency: while SFT optimizes the overall probability of positive items, it does not guarantee that such items will be retrieved by beam search even if they possess high overall probabilities. Due to the greedy pruning mechanism, beam search can prematurely discard a positive item once its prefix probability is insufficient. To address this inconsistency, we propose BEAR (Beam-SEarch-Aware Regularization), a novel fine-tuning objective that explicitly accounts for beam search behavior during training. Rather than directly simulating beam search for each instance during training, which is computationally prohibitive, BEAR enforces a relaxed necessary condition: each token in a positive item must rank within the top-$B$ candidate tokens at each decoding step. This objective effectively mitigates the risk of incorrect pruning while incurring negligible computational overhead compared to standard SFT. Extensive experiments across four real-world datasets demonstrate that BEAR significantly outperforms strong baselines. Code will be released upon acceptance.
TopKGAT: A Top-K Objective-Driven Architecture for Recommendation
Jan 26, 2026Recommendation systems (RS) aim to retrieve the top-K items most relevant to users, with metrics such as Precision@K and Recall@K commonly used to assess effectiveness. The architecture of an RS model acts as an inductive bias, shaping the patterns the model is inclined to learn. In recent years, numerous recommendation architectures have emerged, spanning traditional matrix factorization, deep neural networks, and graph neural networks. However, their designs are often not explicitly aligned with the top-K objective, thereby limiting their effectiveness. To address this limitation, we propose TopKGAT, a novel recommendation architecture directly derived from a differentiable approximation of top-K metrics. The forward computation of a single TopKGAT layer is intrinsically aligned with the gradient ascent dynamics of the Precision@K metric, enabling the model to naturally improve top-K recommendation accuracy. Structurally, TopKGAT resembles a graph attention network and can be implemented efficiently. Extensive experiments on four benchmark datasets demonstrate that TopKGAT consistently outperforms state-of-the-art baselines. The code is available at https://github.com/StupidThree/TopKGAT.
Learning Multi-Modal Mobility Dynamics for Generalized Next Location Recommendation
Dec 27, 2025The precise prediction of human mobility has produced significant socioeconomic impacts, such as location recommendations and evacuation suggestions. However, existing methods suffer from limited generalization capability: unimodal approaches are constrained by data sparsity and inherent biases, while multi-modal methods struggle to effectively capture mobility dynamics caused by the semantic gap between static multi-modal representation and spatial-temporal dynamics. Therefore, we leverage multi-modal spatial-temporal knowledge to characterize mobility dynamics for the location recommendation task, dubbed as \textbf{M}ulti-\textbf{M}odal \textbf{Mob}ility (\textbf{M}$^3$\textbf{ob}). First, we construct a unified spatial-temporal relational graph (STRG) for multi-modal representation, by leveraging the functional semantics and spatial-temporal knowledge captured by the large language models (LLMs)-enhanced spatial-temporal knowledge graph (STKG). Second, we design a gating mechanism to fuse spatial-temporal graph representations of different modalities, and propose an STKG-guided cross-modal alignment to inject spatial-temporal dynamic knowledge into the static image modality. Extensive experiments on six public datasets show that our proposed method not only achieves consistent improvements in normal scenarios but also exhibits significant generalization ability in abnormal scenarios.
Dual-branch Spatial-Temporal Self-supervised Representation for Enhanced Road Network Learning
Nov 10, 2025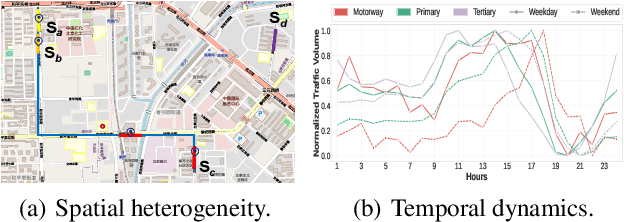



Road network representation learning (RNRL) has attracted increasing attention from both researchers and practitioners as various spatiotemporal tasks are emerging. Recent advanced methods leverage Graph Neural Networks (GNNs) and contrastive learning to characterize the spatial structure of road segments in a self-supervised paradigm. However, spatial heterogeneity and temporal dynamics of road networks raise severe challenges to the neighborhood smoothing mechanism of self-supervised GNNs. To address these issues, we propose a $\textbf{D}$ual-branch $\textbf{S}$patial-$\textbf{T}$emporal self-supervised representation framework for enhanced road representations, termed as DST. On one hand, DST designs a mix-hop transition matrix for graph convolution to incorporate dynamic relations of roads from trajectories. Besides, DST contrasts road representations of the vanilla road network against that of the hypergraph in a spatial self-supervised way. The hypergraph is newly built based on three types of hyperedges to capture long-range relations. On the other hand, DST performs next token prediction as the temporal self-supervised task on the sequences of traffic dynamics based on a causal Transformer, which is further regularized by differentiating traffic modes of weekdays from those of weekends. Extensive experiments against state-of-the-art methods verify the superiority of our proposed framework. Moreover, the comprehensive spatiotemporal modeling facilitates DST to excel in zero-shot learning scenarios.
Soften to Defend: Towards Adversarial Robustness via Self-Guided Label Refinement
Mar 14, 2024Adversarial training (AT) is currently one of the most effective ways to obtain the robustness of deep neural networks against adversarial attacks. However, most AT methods suffer from robust overfitting, i.e., a significant generalization gap in adversarial robustness between the training and testing curves. In this paper, we first identify a connection between robust overfitting and the excessive memorization of noisy labels in AT from a view of gradient norm. As such label noise is mainly caused by a distribution mismatch and improper label assignments, we are motivated to propose a label refinement approach for AT. Specifically, our Self-Guided Label Refinement first self-refines a more accurate and informative label distribution from over-confident hard labels, and then it calibrates the training by dynamically incorporating knowledge from self-distilled models into the current model and thus requiring no external teachers. Empirical results demonstrate that our method can simultaneously boost the standard accuracy and robust performance across multiple benchmark datasets, attack types, and architectures. In addition, we also provide a set of analyses from the perspectives of information theory to dive into our method and suggest the importance of soft labels for robust generalization.