 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAR: Towards Beam-Search-Aware Optimization for Recommendation with Large Language Models
Jan 30, 2026Recent years have witnessed a rapid surge in research leveraging Large Language Models (LLMs) for recommendation. These methods typically employ supervised fine-tuning (SFT) to adapt LLMs to recommendation scenarios, and utilize beam search during inference to efficiently retrieve $B$ top-ranked recommended items. However, we identify a critical training-inference inconsistency: while SFT optimizes the overall probability of positive items, it does not guarantee that such items will be retrieved by beam search even if they possess high overall probabilities. Due to the greedy pruning mechanism, beam search can prematurely discard a positive item once its prefix probability is insufficient. To address this inconsistency, we propose BEAR (Beam-SEarch-Aware Regularization), a novel fine-tuning objective that explicitly accounts for beam search behavior during training. Rather than directly simulating beam search for each instance during training, which is computationally prohibitive, BEAR enforces a relaxed necessary condition: each token in a positive item must rank within the top-$B$ candidate tokens at each decoding step. This objective effectively mitigates the risk of incorrect pruning while incurring negligible computational overhead compared to standard SFT. Extensive experiments across four real-world datasets demonstrate that BEAR significantly outperforms strong baselines. Code will be released upon acceptance.
TopKGAT: A Top-K Objective-Driven Architecture for Recommendation
Jan 26, 2026Recommendation systems (RS) aim to retrieve the top-K items most relevant to users, with metrics such as Precision@K and Recall@K commonly used to assess effectiveness. The architecture of an RS model acts as an inductive bias, shaping the patterns the model is inclined to learn. In recent years, numerous recommendation architectures have emerged, spanning traditional matrix factorization, deep neural networks, and graph neural networks. However, their designs are often not explicitly aligned with the top-K objective, thereby limiting their effectiveness. To address this limitation, we propose TopKGAT, a novel recommendation architecture directly derived from a differentiable approximation of top-K metrics. The forward computation of a single TopKGAT layer is intrinsically aligned with the gradient ascent dynamics of the Precision@K metric, enabling the model to naturally improve top-K recommendation accuracy. Structurally, TopKGAT resembles a graph attention network and can be implemented efficiently. Extensive experiments on four benchmark datasets demonstrate that TopKGAT consistently outperforms state-of-the-art baselines. The code is available at https://github.com/StupidThree/TopKGAT.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Curing Miracle Steps in LLM Mathematical Reasoning with Rubric Rewards
Oct 09, 2025Large language models for mathematical reasoning are typically trained with outcome-based rewards, which credit only the final answer. In our experiments, we observe that this paradigm is highly susceptible to reward hacking, leading to a substantial overestimation of a model's reasoning ability. This is evidenced by a high incidence of false positives - solutions that reach the correct final answer through an unsound reasoning process. Through a systematic analysis with human verification, we establish a taxonomy of these failure modes, identifying patterns like Miracle Steps - abrupt jumps to a correct output without a valid preceding derivation. Probing experiments suggest a strong association between these Miracle Steps and memorization, where the model appears to recall the answer directly rather than deriving it. To mitigate this systemic issue, we introduce the Rubric Reward Model (RRM), a process-oriented reward function that evaluates the entire reasoning trajectory against problem-specific rubrics. The generative RRM provides fine-grained, calibrated rewards (0-1) that explicitly penalize logical flaws and encourage rigorous deduction. When integrated into a reinforcement learning pipeline, RRM-based training consistently outperforms outcome-only supervision across four math benchmarks. Notably, it boosts Verified Pass@1024 on AIME2024 from 26.7% to 62.6% and reduces the incidence of Miracle Steps by 71%. Our work demonstrates that rewarding the solution process is crucial for building models that are not only more accurate but also more reliable.
Accurate Explanation Model for Image Classifiers using Class Association Embedding
Jun 12, 2024Image classification is a primary task in data analysis where explainable models are crucially demanded in various applications. Although amounts of methods have been proposed to obtain explainable knowledge from the black-box classifiers, these approaches lack the efficiency of extracting global knowledge regarding the classification task, thus is vulnerable to local traps and often leads to poor accuracy. In this study, we propose a generative explanation model that combines the advantages of global and local knowledge for explaining image classifiers. We develop a representation learning method called class association embedding (CAE), which encodes each sample into a pair of separated class-associated and individual codes. Recombining the individual code of a given sample with altered class-associated code leads to a synthetic real-looking sample with preserved individual characters but modified class-associated features and possibly flipped class assignments. A building-block coherency feature extraction algorithm is proposed that efficiently separates class-associated features from individual ones. The extracted feature space forms a low-dimensional manifold that visualizes the classification decision patterns. Explanation on each individual sample can be then achieved in a counter-factual generation manner which continuously modifies the sample in one direction, by shifting its class-associated code along a guided path, until its classification outcome is changed. We compare our method with state-of-the-art ones on explaining image classification tasks in the form of saliency maps, demonstrating that our method achieves higher accuracies. The code is available at https://github.com/xrt11/XAI-CODE.
Mixup-Augmented Meta-Learning for Sample-Efficient Fine-Tuning of Protein Simulators
Sep 07, 2023



Molecular dynamics simulations have emerged as a fundamental instrument for studying biomolecules. At the same time, it is desirable to perform simulations of a collection of particles under various conditions in which the molecules can fluctuate. In this paper, we explore and adapt the soft prompt-based learning method to molecular dynamics tasks. Our model can remarkably generalize to unseen and out-of-distribution scenarios with limited training data. While our work focuses on temperature as a test case, the versatility of our approach allows for efficient simulation through any continuous dynamic conditions, such as pressure and volumes. Our framework has two stages: 1) Pre-trains with data mixing technique, augments molecular structure data and temperature prompts, then applies a curriculum learning method by increasing the ratio of them smoothly. 2) Meta-learning-based fine-tuning framework improves sample-efficiency of fine-tuning process and gives the soft prompt-tuning better initialization points. Comprehensive experiments reveal that our framework excels in accuracy for in-domain data and demonstrates strong generalization capabilities for unseen and out-of-distribution samples.
Active Globally Explainable Learning for Medical Images via Class Association Embedding and Cyclic Adversarial Generation
Jun 12, 2023Explainability poses a major challenge to artificial intelligence (AI) techniques. Current studies on explainable AI (XAI) lack the efficiency of extracting global knowledge about the learning task, thus suffer deficiencies such as imprecise saliency, context-aware absence and vague meaning. In this paper, we propose the class association embedding (CAE) approach to address these issues. We employ an encoder-decoder architecture to embed sample features and separate them into class-related and individual-related style vectors simultaneously. Recombining the individual-style code of a given sample with the class-style code of another leads to a synthetic sample with preserved individual characters but changed class assignment, following a cyclic adversarial learning strategy. Class association embedding distills the global class-related features of all instances into a unified domain with well separation between classes. The transition rules between different classes can be then extracted and further employed to individual instances. We then propose an active XAI framework which manipulates the class-style vector of a certain sample along guided paths towards the counter-classes, resulting in a series of counter-example synthetic samples with identical individual characters. Comparing these counterfactual samples with the original ones provides a global, intuitive illustration to the nature of the classification tasks. We adopt the framework on medical image classification tasks, which show that more precise saliency maps with powerful context-aware representation can be achieved compared with existing methods. Moreover, the disease pathology can be directly visualized via traversing the paths in the class-style space.
On the Power of Learning-Augmented BSTs
Nov 16, 2022We present the first Learning-Augmented Binary Search Tree(BST) that attains Static Optimality and Working-Set Bound given rough predictions. Following the recent studies in algorithms with predictions and learned index structures, Lin, Luo, and Woodruff (ICML 2022) introduced the concept of Learning-Augmented BSTs, which aim to improve BSTs with learned advice. Unfortunately, their construction gives only static optimality under strong assumptions on the input. In this paper, we present a simple BST maintenance scheme that benefits from learned advice. With proper predictions, the scheme achieves Static Optimality and Working-Set Bound, respectively, which are important performance measures for BSTs. Moreover, the scheme is robust to prediction errors and makes no assumption on the input.
Fast Adaptively Weighted Matrix Factorization for Recommendation with Implicit Feedback
Mar 04, 2020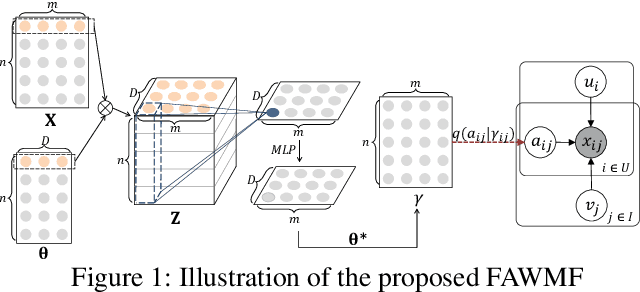
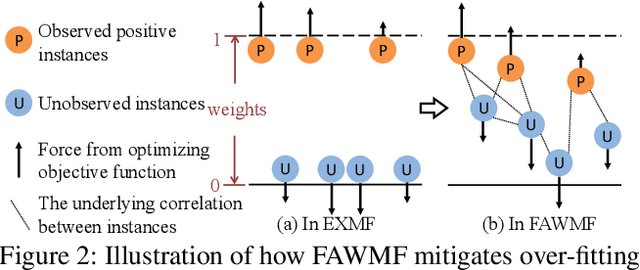

Recommendation from implicit feedback is a highly challenging task due to the lack of the reliable observed negative data. A popular and effective approach for implicit recommendation is to treat unobserved data as negative but downweight their confidence. Naturally, how to assign confidence weights and how to handle the large number of the unobserved data are two key problems for implicit recommendation models. However, existing methods either pursuit fast learning by manually assigning simple confidence weights, which lacks flexibility and may create empirical bias in evaluating user's preference; or adaptively infer personalized confidence weights but suffer from low efficiency. To achieve both adaptive weights assignment and efficient model learning, we propose a fast adaptively weighted matrix factorization (FAWMF) based on variational auto-encoder. The personalized data confidence weights are adaptively assigned with a parameterized neural network (function) and the network can be inferred from the data. Further, to support fast and stable learning of FAWMF, a new specific batch-based learning algorithm fBGD has been developed, which trains on all feedback data but its complexity is linear to the number of observed data. Extensive experiments on real-world datasets demonstrate the superiority of the proposed FAWMF and its learning algorithm fBGD.