 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopKGAT: A Top-K Objective-Driven Architecture for Recommendation
Jan 26, 2026Recommendation systems (RS) aim to retrieve the top-K items most relevant to users, with metrics such as Precision@K and Recall@K commonly used to assess effectiveness. The architecture of an RS model acts as an inductive bias, shaping the patterns the model is inclined to learn. In recent years, numerous recommendation architectures have emerged, spanning traditional matrix factorization, deep neural networks, and graph neural networks. However, their designs are often not explicitly aligned with the top-K objective, thereby limiting their effectiveness. To address this limitation, we propose TopKGAT, a novel recommendation architecture directly derived from a differentiable approximation of top-K metrics. The forward computation of a single TopKGAT layer is intrinsically aligned with the gradient ascent dynamics of the Precision@K metric, enabling the model to naturally improve top-K recommendation accuracy. Structurally, TopKGAT resembles a graph attention network and can be implemented efficiently. Extensive experiments on four benchmark datasets demonstrate that TopKGAT consistently outperforms state-of-the-art baselines. The code is available at https://github.com/StupidThree/TopKGAT.
Knowledge Distillation with Refined Logits
Aug 14, 2024

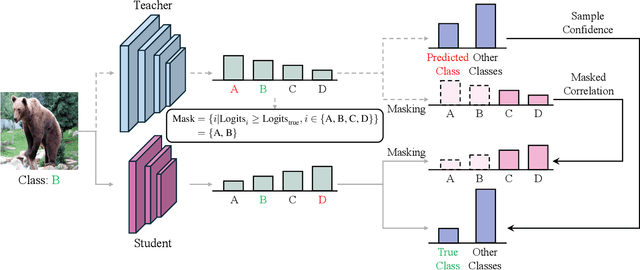

Recent research on knowledge distillation has increasingly focused on logit distillation because of its simplicity, effectiveness, and versatility in model compression. In this paper, we introduce Refined Logit Distillation (RLD) to address the limitations of current logit distillation methods. Our approach is motivated by the observation that even high-performing teacher models can make incorrect predictions, creating a conflict between the standard distillation loss and the cross-entropy loss. This conflict can undermine the consistency of the student model's learning objectives. Previous attempts to use labels to empirically correct teacher predictions may undermine the class correlation. In contrast, our RLD employs labeling information to dynamically refine teacher logits. In this way, our method can effectively eliminate misleading information from the teacher while preserving crucial class correlations, thus enhancing the value and efficiency of distilled knowledge. Experimental results on CIFAR-100 and ImageNet demonstrate its superiority over existing methods. The code is provided at \text{https://github.com/zju-SWJ/RLD}.
Knowledge Translation: A New Pathway for Model Compression
Jan 11, 2024Deep learning has witnessed significant advancements in recent years at the cost of increasing training, inference, and model storage overhead. While existing model compression methods strive to reduce the number of model parameters while maintaining high accuracy, they inevitably necessitate the re-training of the compressed model or impose architectural constraints. To overcome these limitations, this paper presents a novel framework, termed \textbf{K}nowledge \textbf{T}ranslation (KT), wherein a ``translation'' model is trained to receive the parameters of a larger model and generate compressed parameters. The concept of KT draws inspiration from language translation, which effectively employs neural networks to convert different languages, maintaining identical meaning. Accordingly, we explore the potential of neural networks to convert models of disparate sizes, while preserving their functionality. We propose a comprehensive framework for KT, introduce data augmentation strategies to enhance model performance despite restricted training data, and successfully demonstrate the feasibility of KT on the MNIST dataset. Code is available at \url{https://github.com/zju-SWJ/KT}.
Accelerating Diffusion Sampling with Classifier-based Feature Distillation
Nov 22, 2022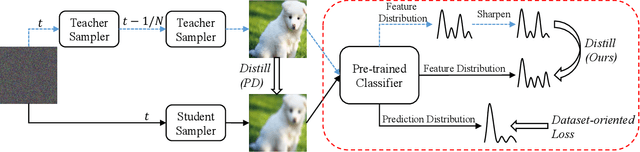
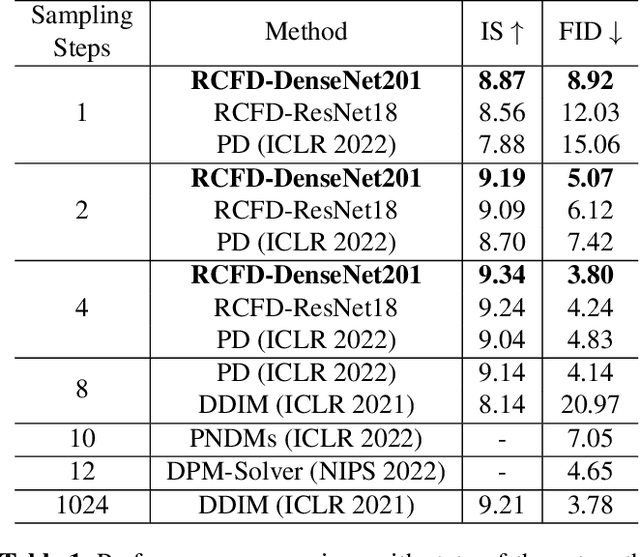

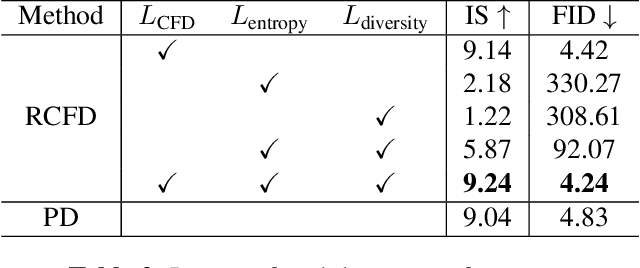
Although diffusion model has shown great potential for generating higher quality images than GANs, slow sampling speed hinders its wide application in practice. Progressive distillation is thus proposed for fast sampling by progressively aligning output images of $N$-step teacher sampler with $N/2$-step student sampler. In this paper, we argue that this distillation-based accelerating method can be further improved, especially for few-step samplers, with our proposed \textbf{C}lassifier-based \textbf{F}eature \textbf{D}istillation (CFD). Instead of aligning output images, we distill teacher's sharpened feature distribution into the student with a dataset-independent classifier, making the student focus on those important features to improve performance. We also introduce a dataset-oriented loss to further optimize the model. Experiments on CIFAR-10 show the superiority of our method in achieving high quality and fast sampling. Code will be released soon.