 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Complex-query Referring Image Segmentation: A Novel Benchmark
Paper and Code
Sep 29, 2023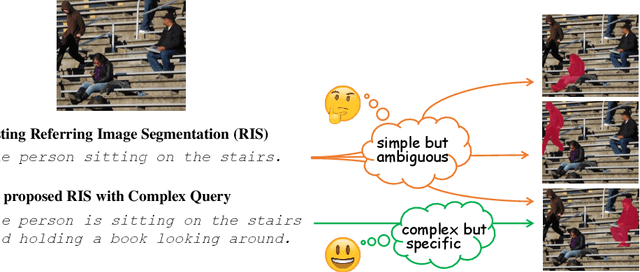
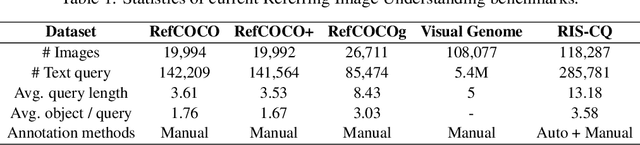

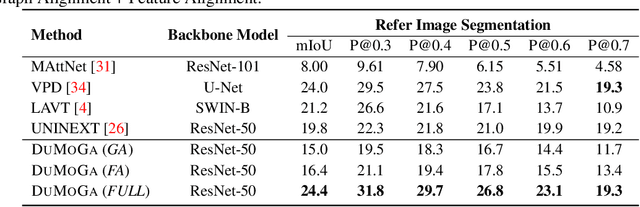
Referring Image Understanding (RIS) has been extensively studied over the past decade, leading to the development of advanced algorithms. However, there has been a lack of research investigating how existing algorithms should be benchmarked with complex language queries, which include more informative descriptions of surrounding objects and backgrounds (\eg \textit{"the black car."} vs. \textit{"the black car is parking on the road and beside the bus."}). Given the significant improvement in the semantic understanding capability of large pre-trained models, it is crucial to take a step further in RIS by incorporating complex language that resembles real-world applications. To close this gap, building upon the existing RefCOCO and Visual Genome datasets, we propose a new RIS benchmark with complex queries, namely \textbf{RIS-CQ}. The RIS-CQ dataset is of high quality and large scale, which challenges the existing RIS with enriched, specific and informative queries, and enables a more realistic scenario of RIS research. Besides, we present a nichetargeting method to better task the RIS-CQ, called dual-modality graph alignment model (\textbf{\textsc{DuMoGa}}), which outperforms a series of RIS methods.