 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHARK: A Lightweight Model Compression Approach for Large-scale Recommender Systems
Paper and Code
Aug 18, 2023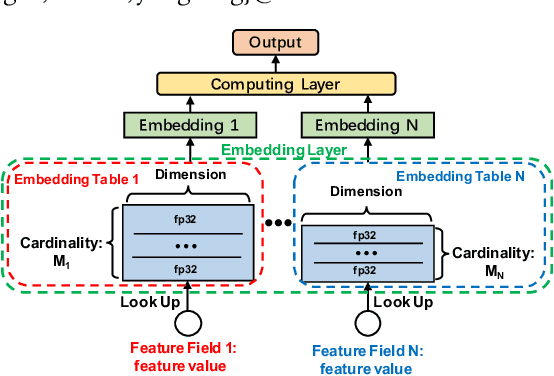


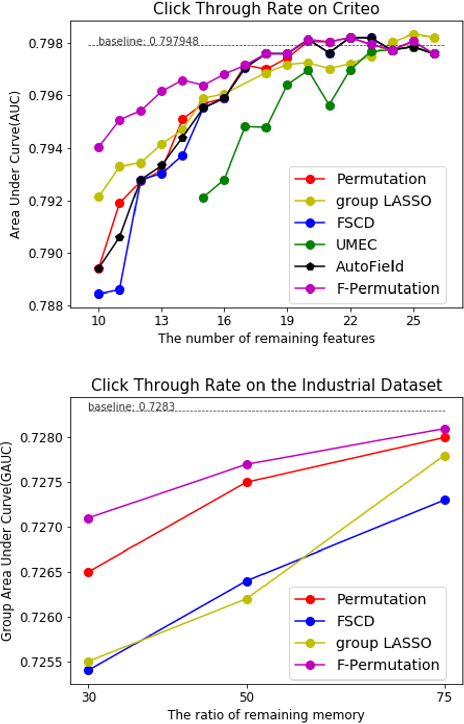
Increasing the size of embedding layers has shown to be effective in improving the performance of recommendation models, yet gradually causing their sizes to exceed terabytes in industrial recommender systems, and hence the increase of computing and storage costs. To save resources while maintaining model performances, we propose SHARK, the model compression practice we have summarized in the recommender system of industrial scenarios. SHARK consists of two main components. First, we use the novel first-order component of Taylor expansion as importance scores to prune the number of embedding tables (feature fields). Second, we introduce a new row-wise quantization method to apply different quantization strategies to each embedding. We conduct extensive experiments on both public and industrial datasets, demonstrating that each component of our proposed SHARK framework outperforms previous approaches. We conduct A/B tests in multiple models on Kuaishou, such as short video, e-commerce, and advertising recommendation models. The results of the online A/B test showed SHARK can effectively reduce the memory footprint of the embedded layer. For the short-video scenarios, the compressed model without any performance drop significantly saves 70% storage and thousands of machines, improves 30\% queries per second (QPS), and has been deployed to serve hundreds of millions of users and process tens of billions of requests every day.