 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Domain Gap of Point Cloud Representations via Self-Supervised Geometric Augmentation
Sep 11, 2024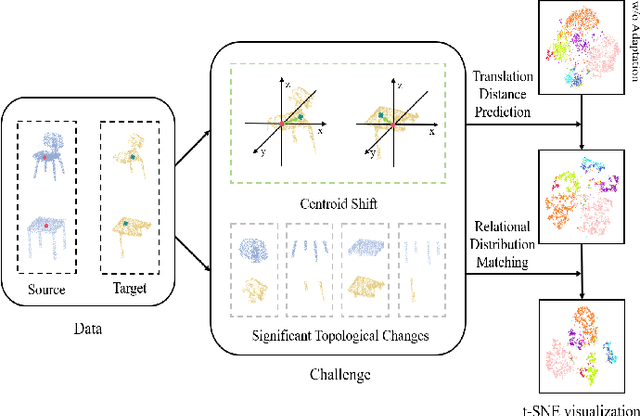
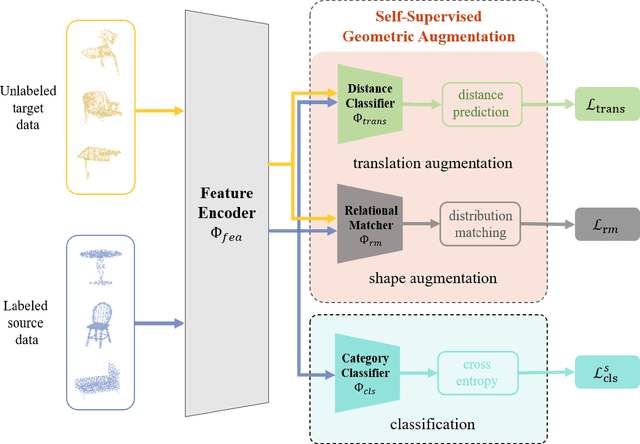
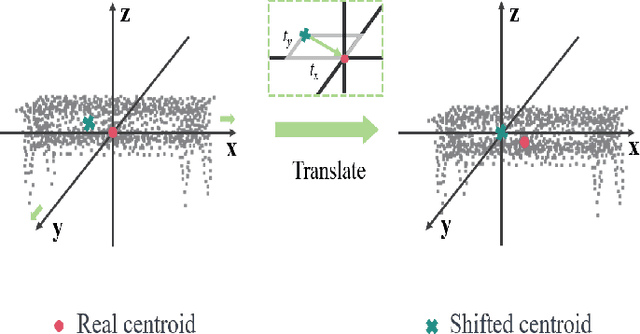
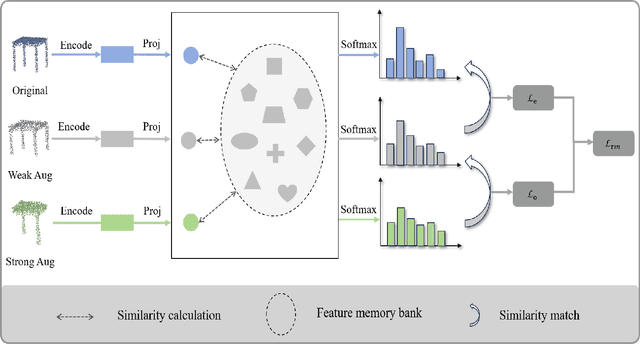
Recent progress of semantic point clouds analysis is largely driven by synthetic data (e.g., the ModelNet and the ShapeNet), which are typically complete, well-aligned and noisy free. Therefore, representations of those ideal synthetic point clouds have limited variations in the geometric perspective and can gain good performance on a number of 3D vision tasks such as point cloud classification. In the context of unsupervised domain adaptation (UDA), representation learning designed for synthetic point clouds can hardly capture domain invariant geometric patterns from incomplete and noisy point clouds. To address such a problem, we introduce a novel scheme for induced geometric invariance of point cloud representations across domains, via regularizing representation learning with two self-supervised geometric augmentation tasks. On one hand, a novel pretext task of predicting translation distances of augmented samples is proposed to alleviate centroid shift of point clouds due to occlusion and noises. On the other hand, we pioneer an integration of the relational self-supervised learning on geometrically-augmented point clouds in a cascade manner, utilizing the intrinsic relationship of augmented variants and other samples as extra constraints of cross-domain geometric features. Experiments on the PointDA-10 dataset demonstrate the effectiveness of the proposed method, achieving the state-of-the-art performance.
Boosting Cross-Domain Point Classification via Distilling Relational Priors from 2D Transformers
Jul 26, 2024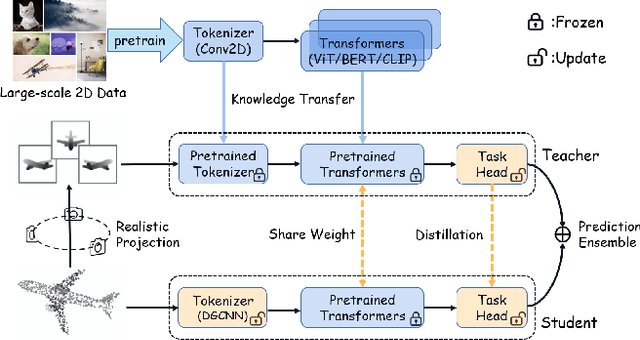
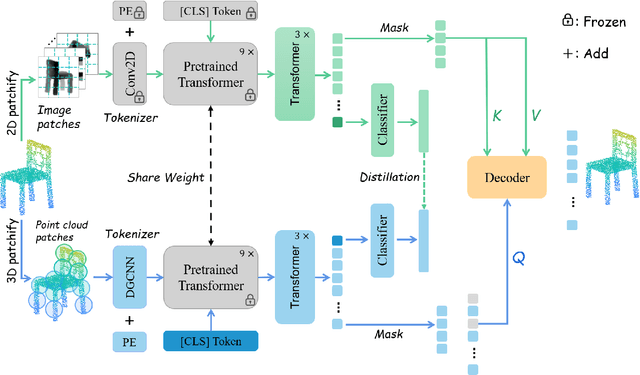
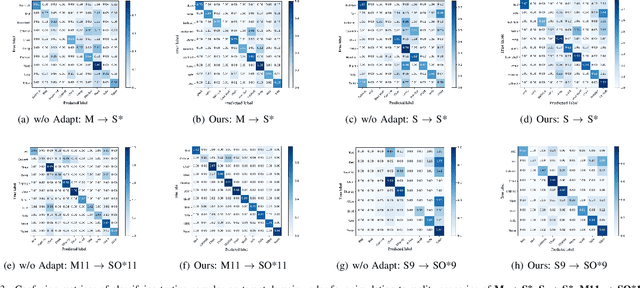
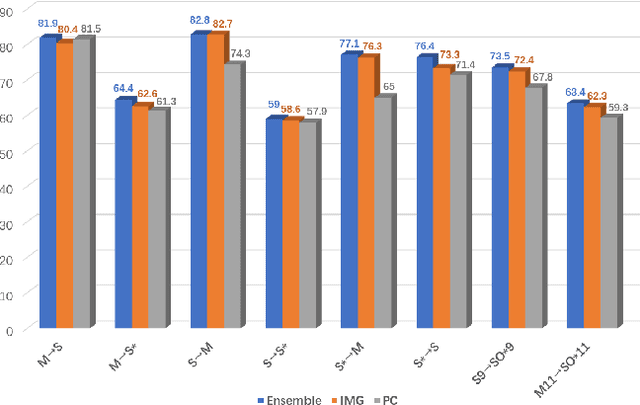
Semantic pattern of an object point cloud is determined by its topological configuration of local geometries. Learning discriminative representations can be challenging due to large shape variations of point sets in local regions and incomplete surface in a global perspective, which can be made even more severe in the context of unsupervised domain adaptation (UDA). In specific, traditional 3D networks mainly focus on local geometric details and ignore the topological structure between local geometries, which greatly limits their cross-domain generalization. Recently, the transformer-based models have achieved impressive performance gain in a range of image-based tasks, benefiting from its strong generalization capability and scalability stemming from capturing long range correlation across local patches. Inspired by such successes of visual transformers, we propose a novel Relational Priors Distillation (RPD) method to extract relational priors from the well-trained transformers on massive images, which can significantly empower cross-domain representations with consistent topological priors of objects. To this end, we establish a parameter-frozen pre-trained transformer module shared between 2D teacher and 3D student models, complemented by an online knowledge distillation strategy for semantically regularizing the 3D student model. Furthermore, we introduce a novel self-supervised task centered on reconstructing masked point cloud patches using corresponding masked multi-view image features, thereby empowering the model with incorporating 3D geometric information. Experiments on the PointDA-10 and the Sim-to-Real datasets verify that the proposed method consistently achieves the state-of-the-art performance of UDA for point cloud classification. The source code of this work is available at https://github.com/zou-longkun/RPD.git.
Quasi-Balanced Self-Training on Noise-Aware Synthesis of Object Point Clouds for Closing Domain Gap
Mar 08, 2022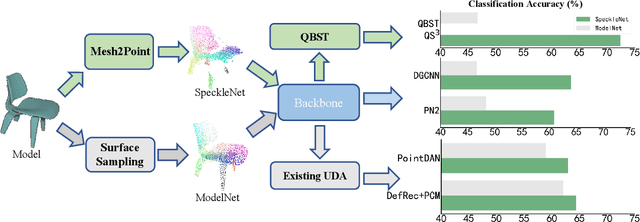
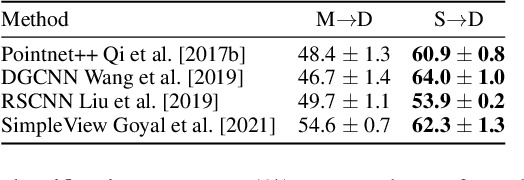
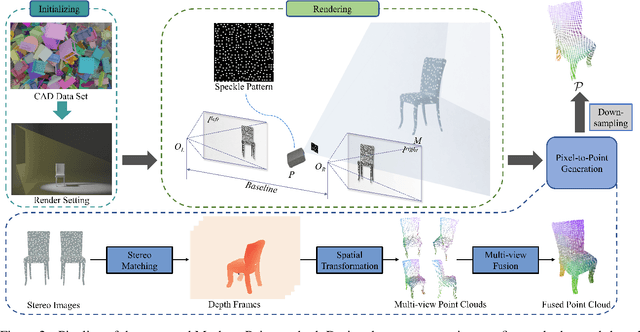
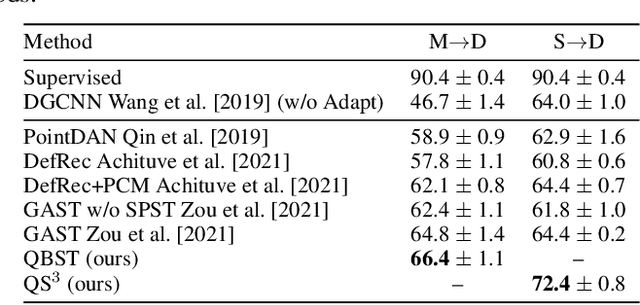
Semantic analyses of object point clouds are largely driven by releasing of benchmarking datasets, including synthetic ones whose instances are sampled from object CAD models. However, learning from synthetic data may not generalize to practical scenarios, where point clouds are typically incomplete, non-uniformly distributed, and noisy. Such a challenge of Simulation-to-Real (Sim2Real) domain gap could be mitigated via learning algorithms of domain adaptation; however, we argue that generation of synthetic point clouds via more physically realistic rendering is a powerful alternative, as systematic non-uniform noise patterns can be captured. To this end, we propose an integrated scheme consisting of physically realistic synthesis of object point clouds via rendering stereo images via projection of speckle patterns onto CAD models and a novel quasi-balanced self-training designed for more balanced data distribution by sparsity-driven selection of pseudo labeled samples for long tailed classes. Experiment results can verify the effectiveness of our method as well as both of its modules for unsupervised domain adaptation on point cloud classification, achieving the state-of-the-art performance.
Geometry-Aware Self-Training for Unsupervised Domain Adaptationon Object Point Clouds
Aug 20, 2021
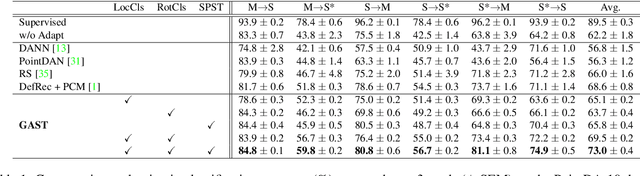

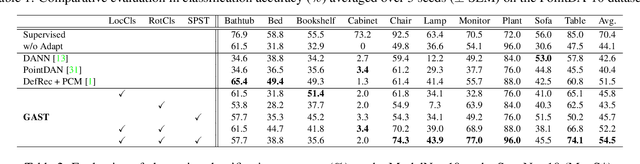
The point cloud representation of an object can have a large geometric variation in view of inconsistent data acquisition procedure, which thus leads to domain discrepancy due to diverse and uncontrollable shape representation cross datasets. To improve discrimination on unseen distribution of point-based geometries in a practical and feasible perspective, this paper proposes a new method of geometry-aware self-training (GAST) for unsupervised domain adaptation of object point cloud classification. Specifically, this paper aims to learn a domain-shared representation of semantic categories, via two novel self-supervised geometric learning tasks as feature regularization. On one hand, the representation learning is empowered by a linear mixup of point cloud samples with their self-generated rotation labels, to capture a global topological configuration of local geometries. On the other hand, a diverse point distribution across datasets can be normalized with a novel curvature-aware distortion localization. Experiments on the PointDA-10 dataset show that our GAST method can significantly outperform the state-of-the-art methods.