 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Domain Gap of Point Cloud Representations via Self-Supervised Geometric Augmentation
Paper and Code
Sep 11, 2024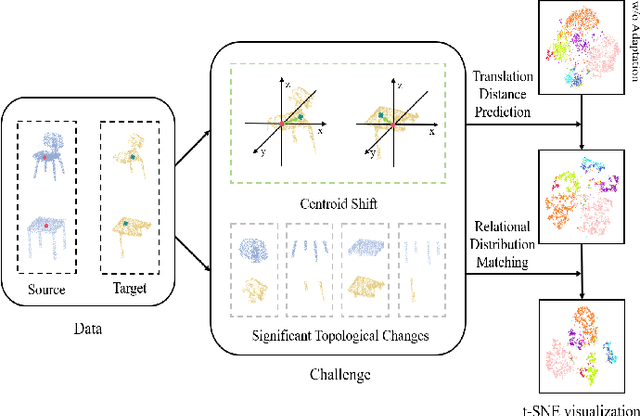
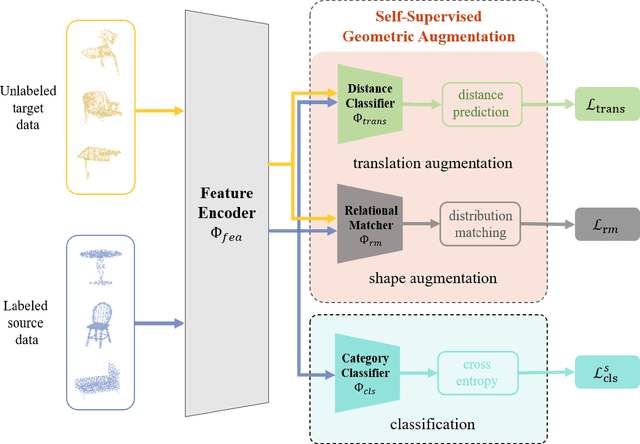
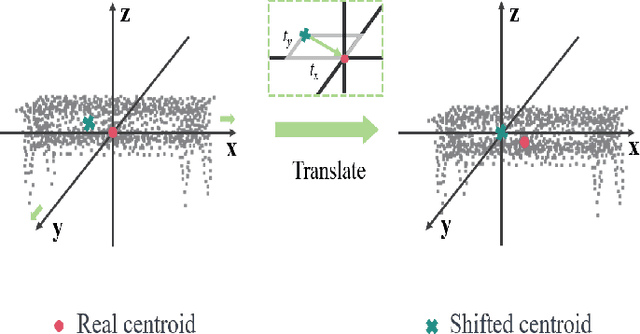
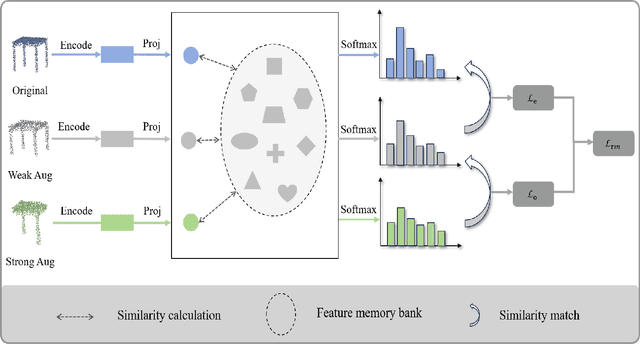
Recent progress of semantic point clouds analysis is largely driven by synthetic data (e.g., the ModelNet and the ShapeNet), which are typically complete, well-aligned and noisy free. Therefore, representations of those ideal synthetic point clouds have limited variations in the geometric perspective and can gain good performance on a number of 3D vision tasks such as point cloud classification. In the context of unsupervised domain adaptation (UDA), representation learning designed for synthetic point clouds can hardly capture domain invariant geometric patterns from incomplete and noisy point clouds. To address such a problem, we introduce a novel scheme for induced geometric invariance of point cloud representations across domains, via regularizing representation learning with two self-supervised geometric augmentation tasks. On one hand, a novel pretext task of predicting translation distances of augmented samples is proposed to alleviate centroid shift of point clouds due to occlusion and noises. On the other hand, we pioneer an integration of the relational self-supervised learning on geometrically-augmented point clouds in a cascade manner, utilizing the intrinsic relationship of augmented variants and other samples as extra constraints of cross-domain geometric features. Experiments on the PointDA-10 dataset demonstrate the effectiveness of the proposed method, achieving the state-of-the-art performance.