 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Cross-Domain Point Classification via Distilling Relational Priors from 2D Transformers
Jul 26, 2024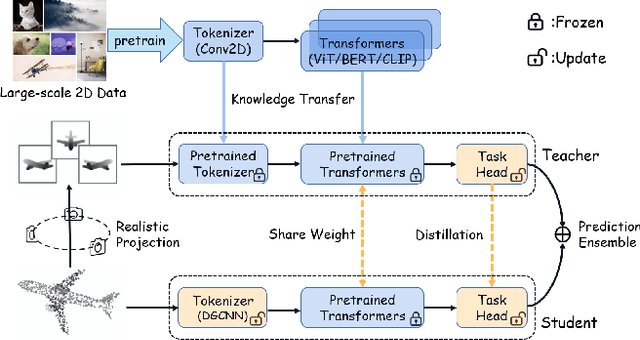
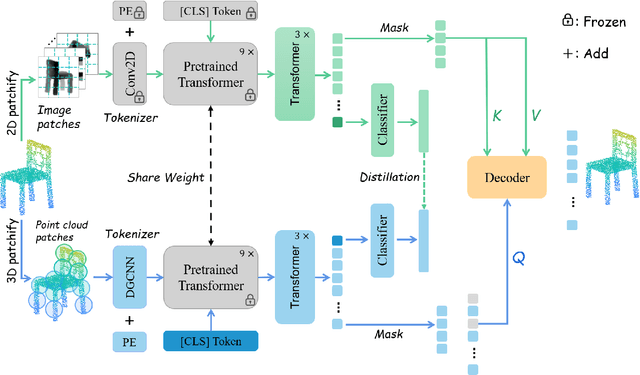
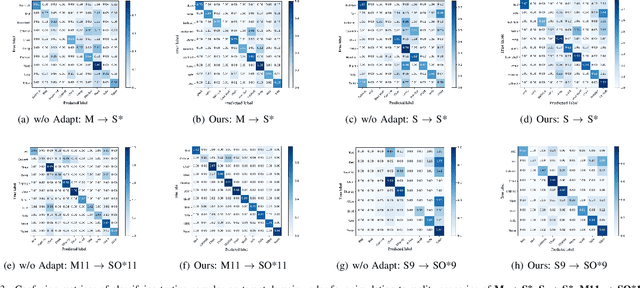
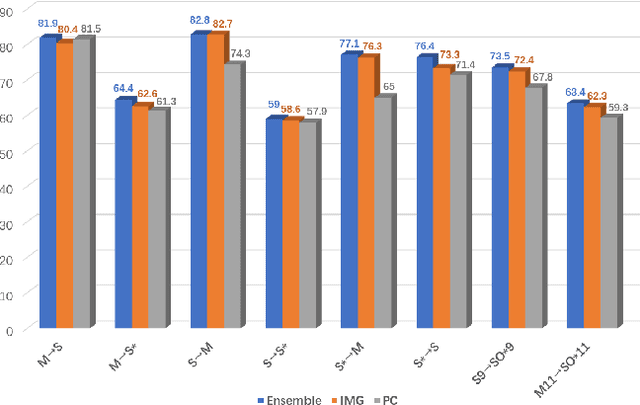
Semantic pattern of an object point cloud is determined by its topological configuration of local geometries. Learning discriminative representations can be challenging due to large shape variations of point sets in local regions and incomplete surface in a global perspective, which can be made even more severe in the context of unsupervised domain adaptation (UDA). In specific, traditional 3D networks mainly focus on local geometric details and ignore the topological structure between local geometries, which greatly limits their cross-domain generalization. Recently, the transformer-based models have achieved impressive performance gain in a range of image-based tasks, benefiting from its strong generalization capability and scalability stemming from capturing long range correlation across local patches. Inspired by such successes of visual transformers, we propose a novel Relational Priors Distillation (RPD) method to extract relational priors from the well-trained transformers on massive images, which can significantly empower cross-domain representations with consistent topological priors of objects. To this end, we establish a parameter-frozen pre-trained transformer module shared between 2D teacher and 3D student models, complemented by an online knowledge distillation strategy for semantically regularizing the 3D student model. Furthermore, we introduce a novel self-supervised task centered on reconstructing masked point cloud patches using corresponding masked multi-view image features, thereby empowering the model with incorporating 3D geometric information. Experiments on the PointDA-10 and the Sim-to-Real datasets verify that the proposed method consistently achieves the state-of-the-art performance of UDA for point cloud classification. The source code of this work is available at https://github.com/zou-longkun/RPD.git.