 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneLCM: End-to-End Layout-Guided Interactive Indoor Scene Generation with Latent Consistency Model
Jun 08, 2025Our project page: https://scutyklin.github.io/SceneLCM/. Automated generation of complex, interactive indoor scenes tailored to user prompt remains a formidable challenge. While existing methods achieve indoor scene synthesis, they struggle with rigid editing constraints, physical incoherence, excessive human effort, single-room limitations, and suboptimal material quality. To address these limitations, we propose SceneLCM, an end-to-end framework that synergizes Large Language Model (LLM) for layout design with Latent Consistency Model(LCM) for scene optimization. Our approach decomposes scene generation into four modular pipelines: (1) Layout Generation. We employ LLM-guided 3D spatial reasoning to convert textual descriptions into parametric blueprints(3D layout). And an iterative programmatic validation mechanism iteratively refines layout parameters through LLM-mediated dialogue loops; (2) Furniture Generation. SceneLCM employs Consistency Trajectory Sampling(CTS), a consistency distillation sampling loss guided by LCM, to form fast, semantically rich, and high-quality representations. We also offer two theoretical justification to demonstrate that our CTS loss is equivalent to consistency loss and its distillation error is bounded by the truncation error of the Euler solver; (3) Environment Optimization. We use a multiresolution texture field to encode the appearance of the scene, and optimize via CTS loss. To maintain cross-geometric texture coherence, we introduce a normal-aware cross-attention decoder to predict RGB by cross-attending to the anchors locations in geometrically heterogeneous instance. (4)Physically Editing. SceneLCM supports physically editing by integrating physical simulation, achieved persistent physical realism. Extensive experiments validate SceneLCM's superiority over state-of-the-art techniques, showing its wide-ranging potential for diverse applications.
Multi-StyleGS: Stylizing Gaussian Splatting with Multiple Styles
Jun 07, 2025In recent years, there has been a growing demand to stylize a given 3D scene to align with the artistic style of reference images for creative purposes. While 3D Gaussian Splatting(GS) has emerged as a promising and efficient method for realistic 3D scene modeling, there remains a challenge in adapting it to stylize 3D GS to match with multiple styles through automatic local style transfer or manual designation, while maintaining memory efficiency for stylization training. In this paper, we introduce a novel 3D GS stylization solution termed Multi-StyleGS to tackle these challenges. In particular, we employ a bipartite matching mechanism to au tomatically identify correspondences between the style images and the local regions of the rendered images. To facilitate local style transfer, we introduce a novel semantic style loss function that employs a segmentation network to apply distinct styles to various objects of the scene and propose a local-global feature matching to enhance the multi-view consistency. Furthermore, this technique can achieve memory efficient training, more texture details and better color match. To better assign a robust semantic label to each Gaussian, we propose several techniques to regularize the segmentation network. As demonstrated by our comprehensive experiments, our approach outperforms existing ones in producing plausible stylization results and offering flexible editing.
* AAAI 2025
Prof. Robot: Differentiable Robot Rendering Without Static and Self-Collisions
Mar 17, 2025



Differentiable rendering has gained significant attention in the field of robotics, with differentiable robot rendering emerging as an effective paradigm for learning robotic actions from image-space supervision. However, the lack of physical world perception in this approach may lead to potential collisions during action optimization. In this work, we introduce a novel improvement on previous efforts by incorporating physical awareness of collisions through the learning of a neural robotic collision classifier. This enables the optimization of actions that avoid collisions with static, non-interactable environments as well as the robot itself. To facilitate effective gradient optimization with the classifier, we identify the underlying issue and propose leveraging Eikonal regularization to ensure consistent gradients for optimization. Our solution can be seamlessly integrated into existing differentiable robot rendering frameworks, utilizing gradients for optimization and providing a foundation for future applications of differentiable rendering in robotics with improved reliability of interactions with the physical world. Both qualitative and quantitative experiments demonstrate the necessity and effectiveness of our method compared to previous solutions.
Generative Scene Synthesis via Incremental View Inpainting using RGBD Diffusion Models
Dec 12, 2022We address the challenge of recovering an underlying scene geometry and colors from a sparse set of RGBD view observations. In this work, we present a new solution that sequentially generates novel RGBD views along a camera trajectory, and the scene geometry is simply the fusion result of these views. More specifically, we maintain an intermediate surface mesh used for rendering new RGBD views, which subsequently becomes complete by an inpainting network; each rendered RGBD view is later back-projected as a partial surface and is supplemented into the intermediate mesh. The use of intermediate mesh and camera projection helps solve the refractory problem of multi-view inconsistency. We practically implement the RGBD inpainting network as a versatile RGBD diffusion model, which is previously used for 2D generative modeling; we make a modification to its reverse diffusion process to enable our use. We evaluate our approach on the task of 3D scene synthesis from sparse RGBD inputs; extensive experiments on the ScanNet dataset demonstrate the superiority of our approach over existing ones. Project page: https://jblei.site/project-pages/rgbd-diffusion.html
TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition
Oct 20, 2022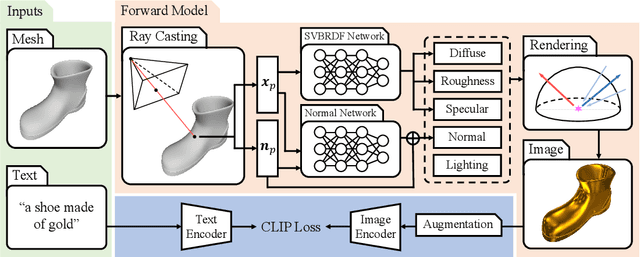



Creation of 3D content by stylization is a promising yet challenging problem in computer vision and graphics research. In this work, we focus on stylizing photorealistic appearance renderings of a given surface mesh of arbitrary topology. Motivated by the recent surge of cross-modal supervision of the Contrastive Language-Image Pre-training (CLIP) model, we propose TANGO, which transfers the appearance style of a given 3D shape according to a text prompt in a photorealistic manner. Technically, we propose to disentangle the appearance style as the spatially varying bidirectional reflectance distribution function, the local geometric variation, and the lighting condition, which are jointly optimized, via supervision of the CLIP loss, by a spherical Gaussians based differentiable renderer. As such, TANGO enables photorealistic 3D style transfer by automatically predicting reflectance effects even for bare, low-quality meshes, without training on a task-specific dataset. Extensive experiments show that TANGO outperforms existing methods of text-driven 3D style transfer in terms of photorealistic quality, consistency of 3D geometry, and robustness when stylizing low-quality meshes. Our codes and results are available at our project webpage https://cyw-3d.github.io/tango/.
Learning and Meshing from Deep Implicit Surface Networks Using an Efficient Implementation of Analytic Marching
Jun 18, 2021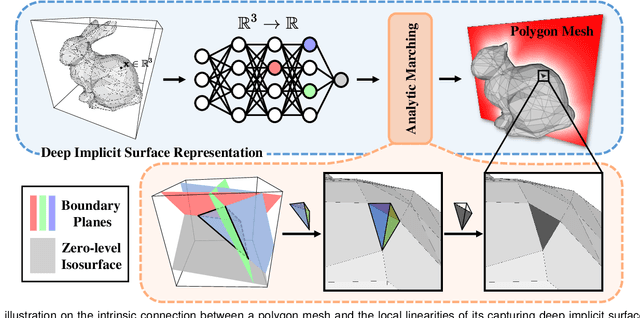
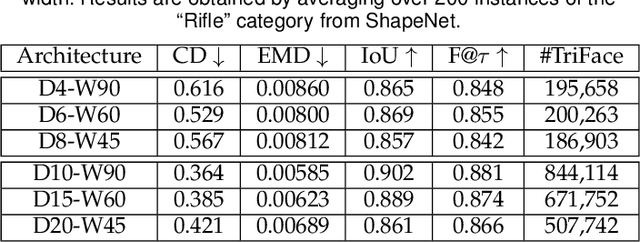
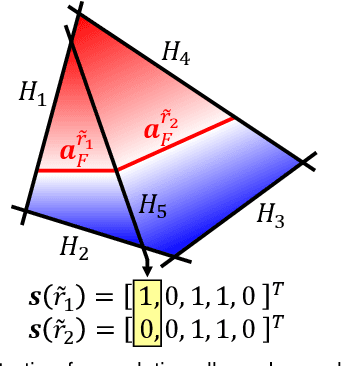
Reconstruction of object or scene surfaces has tremendous applications in computer vision, computer graphics, and robotics. In this paper, we study a fundamental problem in this context about recovering a surface mesh from an implicit field function whose zero-level set captures the underlying surface. To achieve the goal, existing methods rely on traditional meshing algorithms; while promising, they suffer from loss of precision learned in the implicit surface networks, due to the use of discrete space sampling in marching cubes. Given that an MLP with activations of Rectified Linear Unit (ReLU) partitions its input space into a number of linear regions, we are motivated to connect this local linearity with a same property owned by the desired result of polygon mesh. More specifically, we identify from the linear regions, partitioned by an MLP based implicit function, the analytic cells and analytic faces that are associated with the function's zero-level isosurface. We prove that under mild conditions, the identified analytic faces are guaranteed to connect and form a closed, piecewise planar surface. Based on the theorem, we propose an algorithm of analytic marching, which marches among analytic cells to exactly recover the mesh captured by an implicit surface network. We also show that our theory and algorithm are equally applicable to advanced MLPs with shortcut connections and max pooling. Given the parallel nature of analytic marching, we contribute AnalyticMesh, a software package that supports efficient meshing of implicit surface networks via CUDA parallel computing, and mesh simplification for efficient downstream processing. We apply our method to different settings of generative shape modeling using implicit surface networks. Extensive experiments demonstrate our advantages over existing methods in terms of both meshing accuracy and efficiency.
Sign-Agnostic CONet: Learning Implicit Surface Reconstructions by Sign-Agnostic Optimization of Convolutional Occupancy Networks
May 08, 2021
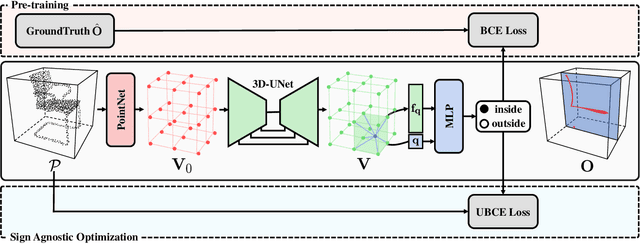
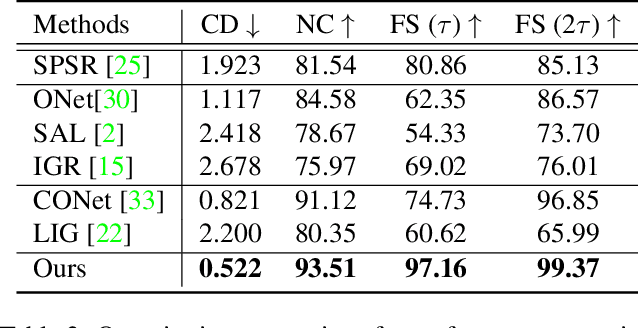
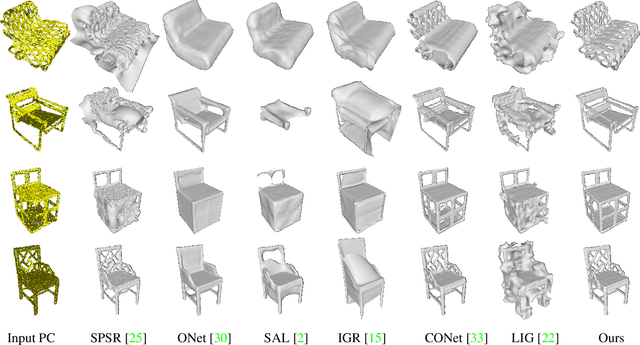
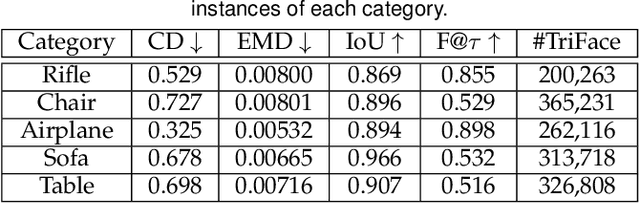
Surface reconstruction from point clouds is a fundamental problem in the computer vision and graphics community. Recent state-of-the-arts solve this problem by individually optimizing each local implicit field during inference. Without considering the geometric relationships between local fields, they typically require accurate normals to avoid the sign conflict problem in overlapping regions of local fields, which severely limits their applicability to raw scans where surface normals could be unavailable. Although SAL breaks this limitation via sign-agnostic learning, it is still unexplored that how to extend this pipeline to local shape modeling. To this end, we propose to learn implicit surface reconstruction by sign-agnostic optimization of convolutional occupancy networks, to simultaneously achieve advanced scalability, generality, and applicability in a unified framework. In the paper, we also show this goal can be effectively achieved by a simple yet effective design, which optimizes the occupancy fields that are conditioned on convolutional features from an hourglass network architecture with an unsigned binary cross-entropy loss. Extensive experimental comparison with previous state-of-the-arts on both object-level and scene-level datasets demonstrate the superior accuracy of our approach for surface reconstruction from un-orientated point clouds.
Sign-Agnostic Implicit Learning of Surface Self-Similarities for Shape Modeling and Reconstruction from Raw Point Clouds
Dec 14, 2020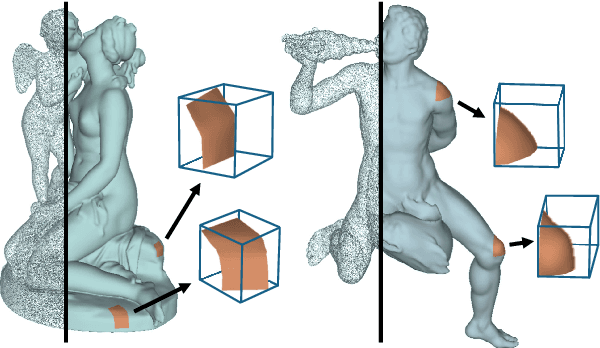

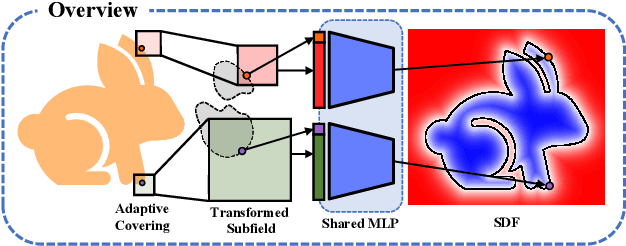
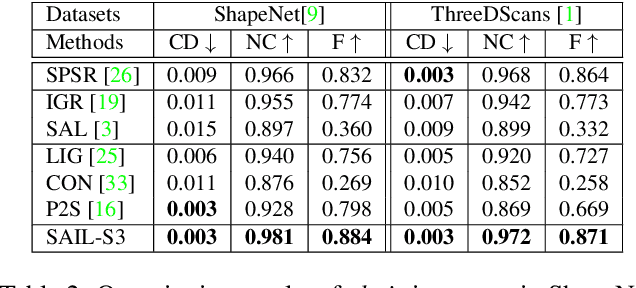
Shape modeling and reconstruction from raw point clouds of objects stand as a fundamental challenge in vision and graphics research. Classical methods consider analytic shape priors; however, their performance degraded when the scanned points deviate from the ideal conditions of cleanness and completeness. Important progress has been recently made by data-driven approaches, which learn global and/or local models of implicit surface representations from auxiliary sets of training shapes. Motivated from a universal phenomenon that self-similar shape patterns of local surface patches repeat across the entire surface of an object, we aim to push forward the data-driven strategies and propose to learn a local implicit surface network for a shared, adaptive modeling of the entire surface for a direct surface reconstruction from raw point cloud; we also enhance the leveraging of surface self-similarities by improving correlations among the optimized latent codes of individual surface patches. Given that orientations of raw points could be unavailable or noisy, we extend sign agnostic learning into our local implicit model, which enables our recovery of signed implicit fields of local surfaces from the unsigned inputs. We term our framework as Sign-Agnostic Implicit Learning of Surface Self-Similarities (SAIL-S3). With a global post-optimization of local sign flipping, SAIL-S3 is able to directly model raw, un-oriented point clouds and reconstruct high-quality object surfaces. Experiments show its superiority over existing methods.
Analytic Marching: An Analytic Meshing Solution from Deep Implicit Surface Networks
Feb 16, 2020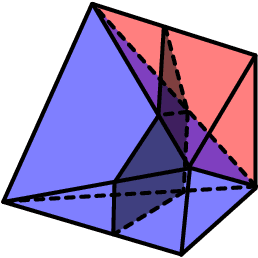
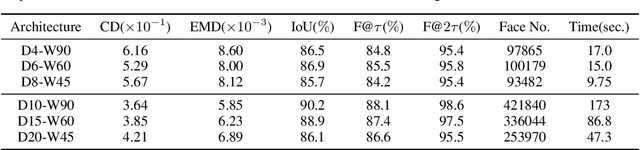
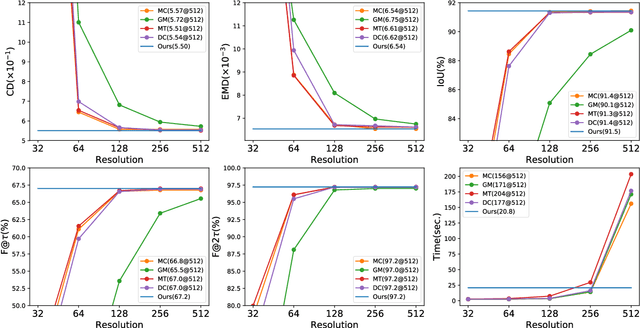

This paper studies a problem of learning surface mesh via implicit functions in an emerging field of deep learning surface reconstruction, where implicit functions are popularly implemented as multi-layer perceptrons (MLPs) with rectified linear units (ReLU). To achieve meshing from learned implicit functions, existing methods adopt the de-facto standard algorithm of marching cubes; while promising, they suffer from loss of precision learned in the MLPs, due to the discretization nature of marching cubes. Motivated by the knowledge that a ReLU based MLP partitions its input space into a number of linear regions, we identify from these regions analytic cells and analytic faces that are associated with zero-level isosurface of the implicit function, and characterize the theoretical conditions under which the identified analytic faces are guaranteed to connect and form a closed, piecewise planar surface. Based on our theorem, we propose a naturally parallelizable algorithm of analytic marching, which marches among analytic cells to exactly recover the mesh captured by a learned MLP. Experiments on deep learning mesh reconstruction verify the advantages of our algorithm over existing ones.