 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Generation: Image Synthesis based on Coarsely Matched Texts
Sep 08, 2023



Previous text-to-image synthesis algorithms typically use explicit textual instructions to generate/manipulate images accurately, but they have difficulty adapting to guidance in the form of coarsely matched texts. In this work, we attempt to stylize an input image using such coarsely matched text as guidance. To tackle this new problem, we introduce a novel task called text-based style generation and propose a two-stage generative adversarial network: the first stage generates the overall image style with a sentence feature, and the second stage refines the generated style with a synthetic feature, which is produced by a multi-modality style synthesis module. We re-filter one existing dataset and collect a new dataset for the task. Extensive experiments and ablation studies are conducted to validate our framework. The practical potential of our work is demonstrated by various applications such as text-image alignment and story visualization. Our datasets are published at https://www.kaggle.com/datasets/mengyaocui/style-generation.
A Compact Neural Network-based Algorithm for Robust Image Watermarking
Dec 27, 2021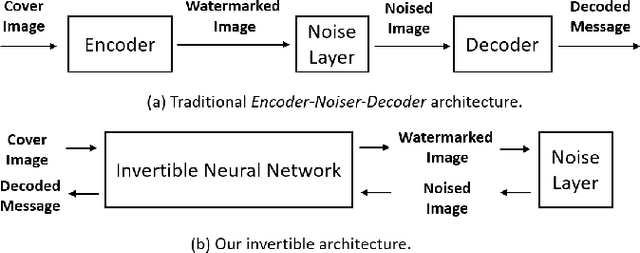
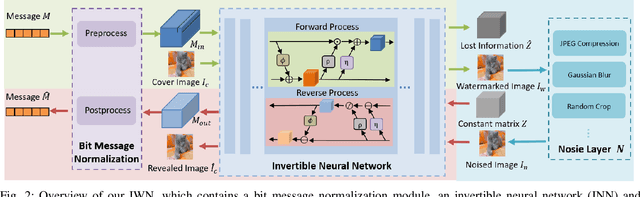
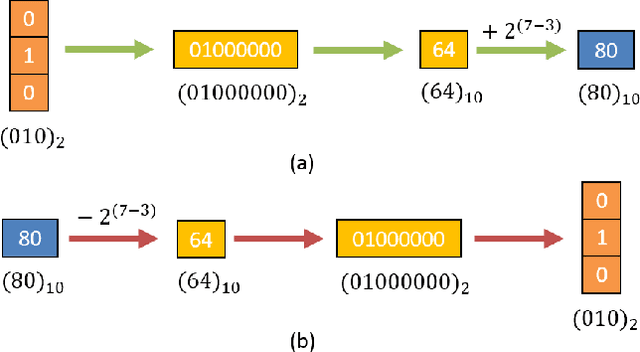
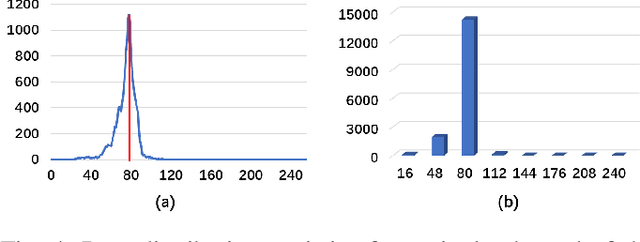
Digital image watermarking seeks to protect the digital media information from unauthorized access, where the message is embedded into the digital image and extracted from it, even some noises or distortions are applied under various data processing including lossy image compression and interactive content editing. Traditional image watermarking solutions easily suffer from robustness when specified with some prior constraints, while recent deep learning-based watermarking methods could not tackle the information loss problem well under various separate pipelines of feature encoder and decoder. In this paper, we propose a novel digital image watermarking solution with a compact neural network, named Invertible Watermarking Network (IWN). Our IWN architecture is based on a single Invertible Neural Network (INN), this bijective propagation framework enables us to effectively solve the challenge of message embedding and extraction simultaneously, by taking them as a pair of inverse problems for each other and learning a stable invertible mapping. In order to enhance the robustness of our watermarking solution, we specifically introduce a simple but effective bit message normalization module to condense the bit message to be embedded, and a noise layer is designed to simulate various practical attacks under our IWN framework. Extensive experiments demonstrate the superiority of our solution under various distortions.
DOTS: Decoupling Operation and Topology in Differentiable Architecture Search
Oct 02, 2020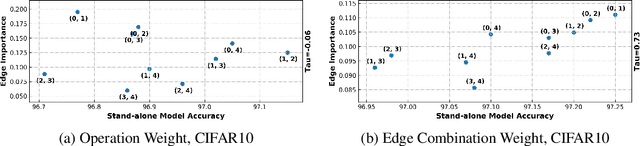
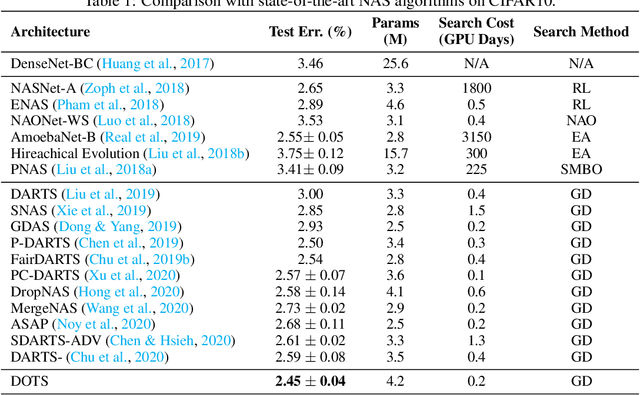
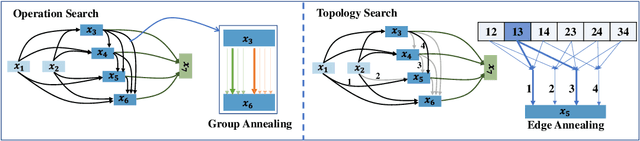
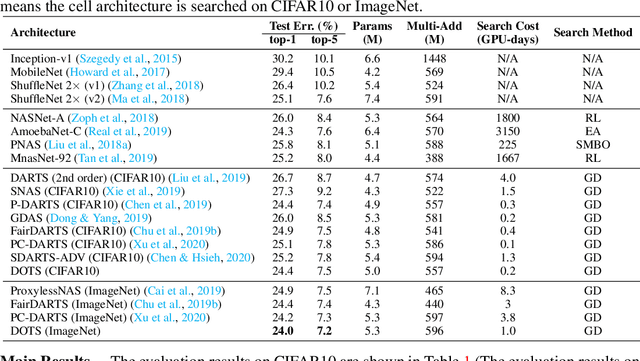
Differentiable Architecture Search (DARTS) has attracted extensive attention due to its efficiency in searching for cell structures. However, DARTS mainly focuses on the operation search, leaving the cell topology implicitly depending on the searched operation weights. Hence, a problem is raised: can cell topology be well represented by the operation weights? The answer is negative because we observe that the operation weights fail to indicate the performance of cell topology. In this paper, we propose to Decouple the Operation and Topology Search (DOTS), which decouples the cell topology representation from the operation weights to make an explicit topology search. DOTS is achieved by defining an additional cell topology search space besides the original operation search space. Within the DOTS framework, we propose group annealing operation search and edge annealing topology search to bridge the optimization gap between the searched over-parameterized network and the derived child network. DOTS is efficient and only costs 0.2 and 1 GPU-day to search the state-of-the-art cell architectures on CIFAR and ImageNet, respectively. By further searching for the topology of DARTS' searched cell, we can improve DARTS' performance significantly. The code will be publicly available.
Generalized Zero-Shot Learning via VAE-Conditioned Generative Flow
Sep 01, 2020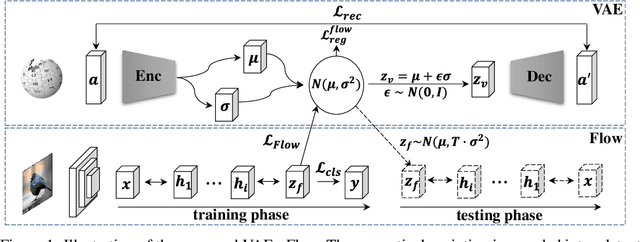
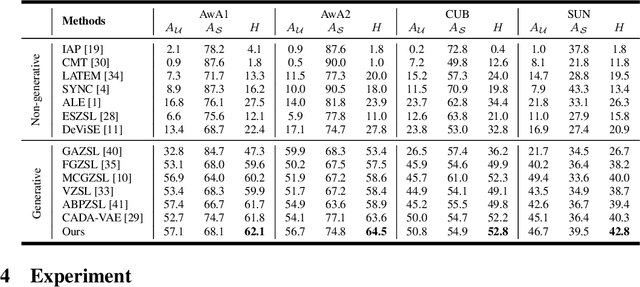
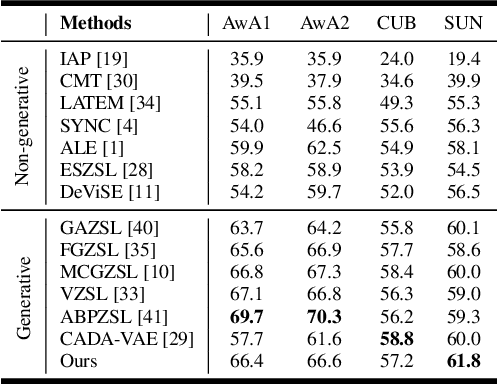
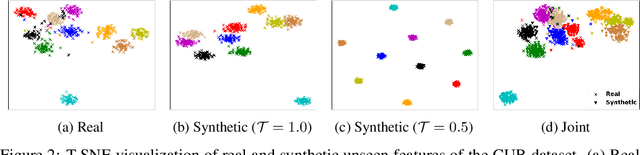
Generalized zero-shot learning (GZSL) aims to recognize both seen and unseen classes by transferring knowledge from semantic descriptions to visual representations. Recent generative methods formulate GZSL as a missing data problem, which mainly adopts GANs or VAEs to generate visual features for unseen classes. However, GANs often suffer from instability, and VAEs can only optimize the lower bound on the log-likelihood of observed data. To overcome the above limitations, we resort to generative flows, a family of generative models with the advantage of accurate likelihood estimation. More specifically, we propose a conditional version of generative flows for GZSL, i.e., VAE-Conditioned Generative Flow (VAE-cFlow). By using VAE, the semantic descriptions are firstly encoded into tractable latent distributions, conditioned on that the generative flow optimizes the exact log-likelihood of the observed visual features. We ensure the conditional latent distribution to be both semantic meaningful and inter-class discriminative by i) adopting the VAE reconstruction objective, ii) releasing the zero-mean constraint in VAE posterior regularization, and iii) adding a classification regularization on the latent variables. Our method achieves state-of-the-art GZSL results on five well-known benchmark datasets, especially for the significant improvement in the large-scale setting. Code is released at https://github.com/guyuchao/VAE-cFlow-ZSL.
Bilateral Attention Network for RGB-D Salient Object Detection
Apr 30, 2020
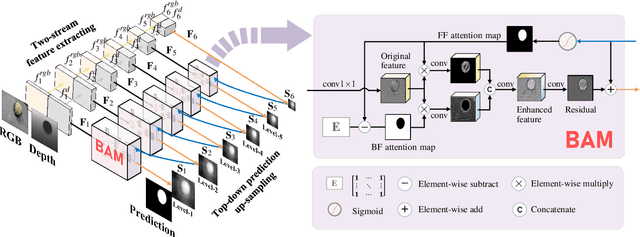


Most existing RGB-D salient object detection (SOD) methods focus on the foreground region when utilizing the depth images. However, the background also provides important information in traditional SOD methods for promising performance. To better explore salient information in both foreground and background regions, this paper proposes a Bilateral Attention Network (BiANet) for the RGB-D SOD task. Specifically, we introduce a Bilateral Attention Module (BAM) with a complementary attention mechanism: foreground-first (FF) attention and background-first (BF) attention. The FF attention focuses on the foreground region with a gradual refinement style, while the BF one recovers potentially useful salient information in the background region. Benefitted from the proposed BAM module, our BiANet can capture more meaningful foreground and background cues, and shift more attention to refining the uncertain details between foreground and background regions. Additionally, we extend our BAM by leveraging the multi-scale techniques for better SOD performance. Extensive experiments on six benchmark datasets demonstrate that our BiANet outperforms other state-of-the-art RGB-D SOD methods in terms of objective metrics and subjective visual comparison. Our BiANet can run up to 80fps on $224\times224$ RGB-D images, with an NVIDIA GeForce RTX 2080Ti GPU. Comprehensive ablation studies also validate our contributions.
LSANet: Feature Learning on Point Sets by Local Spatial Attention
May 14, 2019

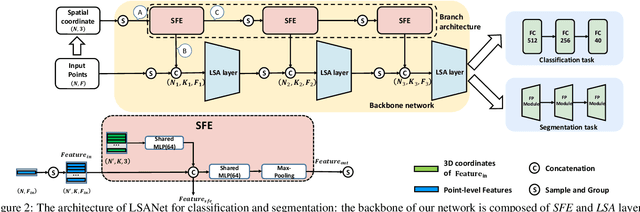
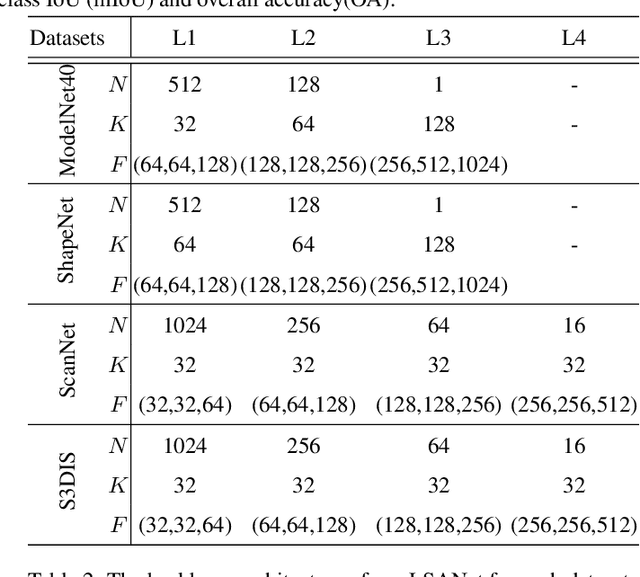
Directly learning features from the point cloud has become an active research direction in 3D understanding. Existing learning-based methods usually construct local regions from the point cloud and extract the corresponding features using shared Multi-Layer Perceptron (MLP) and max pooling. However, most of these processes do not adequately take the spatial distribution of the point cloud into account, limiting the ability to perceive fine-grained patterns. We design a novel Local Spatial Attention (LSA) module to adaptively generate attention maps according to the spatial distribution of local regions. The feature learning process which integrates with these attention maps can effectively capture the local geometric structure. We further propose the Spatial Feature Extractor (SFE), which constructs a branch architecture, to aggregate the spatial information with associated features in each layer of the network better.The experiments show that our network, named LSANet, can achieve on par or better performance than the state-of-the-art methods when evaluating on the challenging benchmark datasets. The source code is available at https://github.com/LinZhuoChen/LSANet.