 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Context Transformer for Streaming 3D Reconstruction
Apr 16, 2026Streaming 3D reconstruction aims to recover 3D information, such as camera poses and point clouds, from a video stream, which necessitates geometric accuracy, temporal consistency, and computational efficiency. Motivated by the principles of Simultaneous Localization and Mapping (SLAM), we introduce LingBot-Map, a feed-forward 3D foundation model for reconstructing scenes from streaming data, built upon a geometric context transformer (GCT) architecture. A defining aspect of LingBot-Map lies in its carefully designed attention mechanism, which integrates an anchor context, a pose-reference window, and a trajectory memory to address coordinate grounding, dense geometric cues, and long-range drift correction, respectively. This design keeps the streaming state compact while retaining rich geometric context, enabling stable efficient inference at around 20 FPS on 518 x 378 resolution inputs over long sequences exceeding 10,000 frames. Extensive evaluations across a variety of benchmarks demonstrate that our approach achieves superior performance compared to both existing streaming and iterative optimization-based approaches.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
Flow Distillation Sampling: Regularizing 3D Gaussians with Pre-trained Matching Priors
Feb 11, 20253D Gaussian Splatting (3DGS) has achieved excellent rendering quality with fast training and rendering speed. However, its optimization process lacks explicit geometric constraints, leading to suboptimal geometric reconstruction in regions with sparse or no observational input views. In this work, we try to mitigate the issue by incorporating a pre-trained matching prior to the 3DGS optimization process. We introduce Flow Distillation Sampling (FDS), a technique that leverages pre-trained geometric knowledge to bolster the accuracy of the Gaussian radiance field. Our method employs a strategic sampling technique to target unobserved views adjacent to the input views, utilizing the optical flow calculated from the matching model (Prior Flow) to guide the flow analytically calculated from the 3DGS geometry (Radiance Flow). Comprehensive experiments in depth rendering, mesh reconstruction, and novel view synthesis showcase the significant advantages of FDS over state-of-the-art methods. Additionally, our interpretive experiments and analysis aim to shed light on the effects of FDS on geometric accuracy and rendering quality, potentially providing readers with insights into its performance. Project page: https://nju-3dv.github.io/projects/fds
Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation
Apr 09, 2020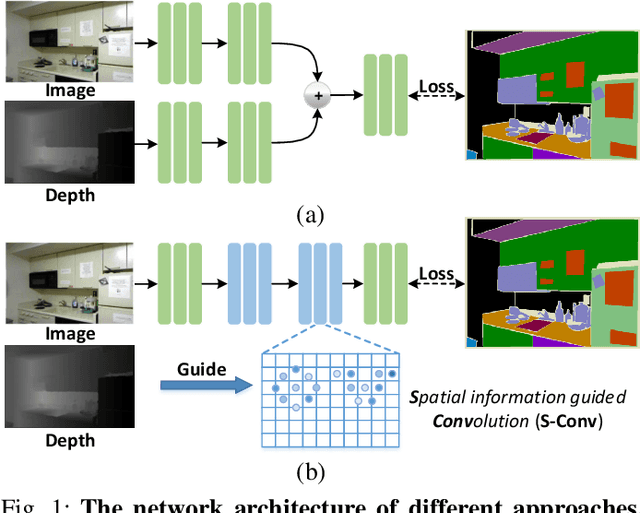
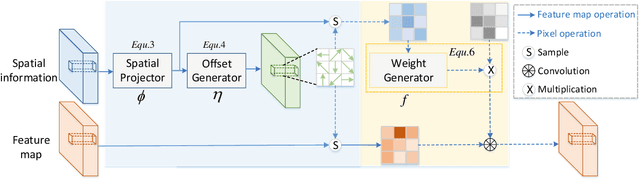
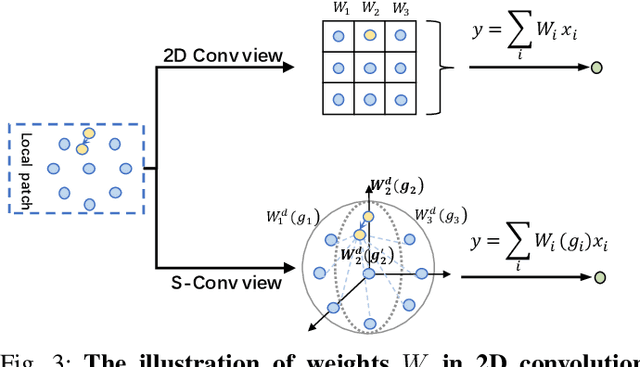
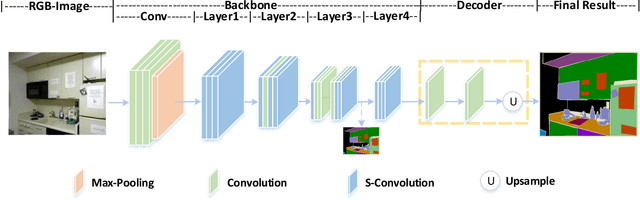
3D spatial information is known to be beneficial to the semantic segmentation task. Most existing methods take 3D spatial data as an additional input, leading to a two-stream segmentation network that processes RGB and 3D spatial information separately. This solution greatly increases the inference time and severely limits its scope for real-time applications. To solve this problem, we propose Spatial information guided Convolution (S-Conv), which allows efficient RGB feature and 3D spatial information integration. S-Conv is competent to infer the sampling offset of the convolution kernel guided by the 3D spatial information, helping the convolutional layer adjust the receptive field and adapt to geometric transformations. S-Conv also incorporates geometric information into the feature learning process by generating spatially adaptive convolutional weights. The capability of perceiving geometry is largely enhanced without much affecting the amount of parameters and computational cost. We further embed S-Conv into a semantic segmentation network, called Spatial information Guided convolutional Network (SGNet), resulting in real-time inference and state-of-the-art performance on NYUDv2 and SUNRGBD datasets.
LSANet: Feature Learning on Point Sets by Local Spatial Attention
May 14, 2019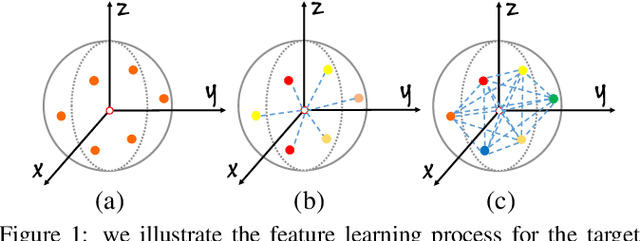

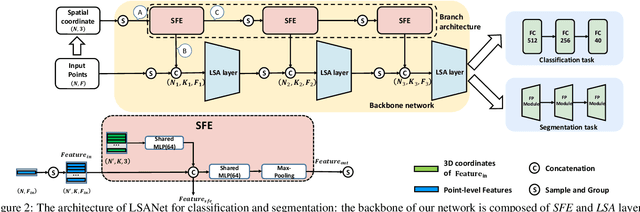
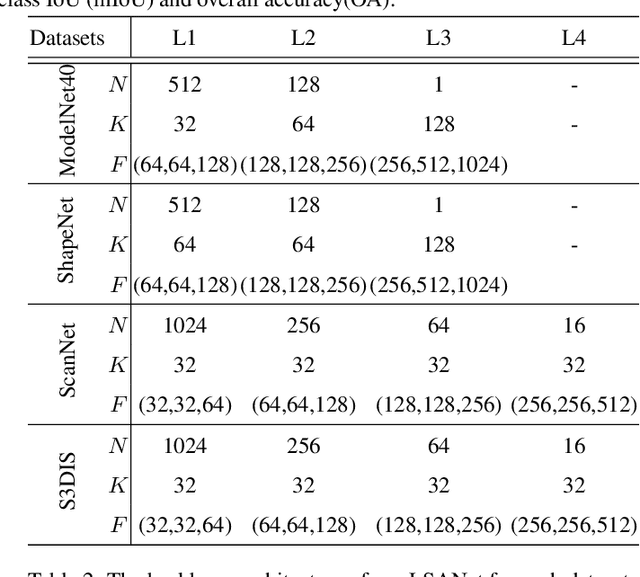
Directly learning features from the point cloud has become an active research direction in 3D understanding. Existing learning-based methods usually construct local regions from the point cloud and extract the corresponding features using shared Multi-Layer Perceptron (MLP) and max pooling. However, most of these processes do not adequately take the spatial distribution of the point cloud into account, limiting the ability to perceive fine-grained patterns. We design a novel Local Spatial Attention (LSA) module to adaptively generate attention maps according to the spatial distribution of local regions. The feature learning process which integrates with these attention maps can effectively capture the local geometric structure. We further propose the Spatial Feature Extractor (SFE), which constructs a branch architecture, to aggregate the spatial information with associated features in each layer of the network better.The experiments show that our network, named LSANet, can achieve on par or better performance than the state-of-the-art methods when evaluating on the challenging benchmark datasets. The source code is available at https://github.com/LinZhuoChen/LSANet.