 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSLight: Co-optimizing Collaborator Selection and Decision-making to Enhance Traffic Signal Control
May 27, 2024

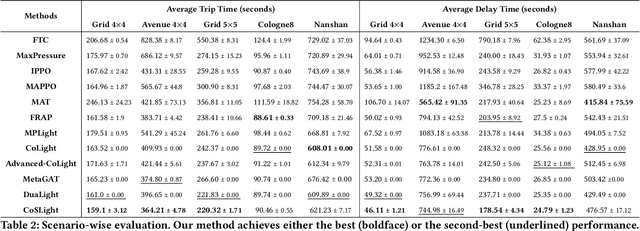
Effective multi-intersection collaboration is pivotal for reinforcement-learning-based traffic signal control to alleviate congestion. Existing work mainly chooses neighboring intersections as collaborators. However, quite an amount of congestion, even some wide-range congestion, is caused by non-neighbors failing to collaborate. To address these issues, we propose to separate the collaborator selection as a second policy to be learned, concurrently being updated with the original signal-controlling policy. Specifically, the selection policy in real-time adaptively selects the best teammates according to phase- and intersection-level features. Empirical results on both synthetic and real-world datasets provide robust validation for the superiority of our approach, offering significant improvements over existing state-of-the-art methods. The code is available at https://github.com/AnonymousAccountss/CoSLight.
X-Light: Cross-City Traffic Signal Control Using Transformer on Transformer as Meta Multi-Agent Reinforcement Learner
Apr 18, 2024



The effectiveness of traffic light control has been significantly improved by current reinforcement learning-based approaches via better cooperation among multiple traffic lights. However, a persisting issue remains: how to obtain a multi-agent traffic signal control algorithm with remarkable transferability across diverse cities? In this paper, we propose a Transformer on Transformer (TonT) model for cross-city meta multi-agent traffic signal control, named as X-Light: We input the full Markov Decision Process trajectories, and the Lower Transformer aggregates the states, actions, rewards among the target intersection and its neighbors within a city, and the Upper Transformer learns the general decision trajectories across different cities. This dual-level approach bolsters the model's robust generalization and transferability. Notably, when directly transferring to unseen scenarios, ours surpasses all baseline methods with +7.91% on average, and even +16.3% in some cases, yielding the best results.
DuaLight: Enhancing Traffic Signal Control by Leveraging Scenario-Specific and Scenario-Shared Knowledge
Dec 22, 2023



Reinforcement learning has been revolutionizing the traditional traffic signal control task, showing promising power to relieve congestion and improve efficiency. However, the existing methods lack effective learning mechanisms capable of absorbing dynamic information inherent to a specific scenario and universally applicable dynamic information across various scenarios. Moreover, within each specific scenario, they fail to fully capture the essential empirical experiences about how to coordinate between neighboring and target intersections, leading to sub-optimal system-wide outcomes. Viewing these issues, we propose DuaLight, which aims to leverage both the experiential information within a single scenario and the generalizable information across various scenarios for enhanced decision-making. Specifically, DuaLight introduces a scenario-specific experiential weight module with two learnable parts: Intersection-wise and Feature-wise, guiding how to adaptively utilize neighbors and input features for each scenario, thus providing a more fine-grained understanding of different intersections. Furthermore, we implement a scenario-shared Co-Train module to facilitate the learning of generalizable dynamics information across different scenarios. Empirical results on both real-world and synthetic scenarios show DuaLight achieves competitive performance across various metrics, offering a promising solution to alleviate traffic congestion, with 3-7\% improvements. The code is available under: https://github.com/lujiaming-12138/DuaLight.
Little Exploration is All You Need
Oct 26, 2023The prevailing principle of "Optimism in the Face of Uncertainty" advocates for the incorporation of an exploration bonus, generally assumed to be proportional to the inverse square root of the visit count ($1/\sqrt{n}$), where $n$ is the number of visits to a particular state-action pair. This approach, however, exclusively focuses on "uncertainty," neglecting the inherent "difficulty" of different options. To address this gap, we introduce a novel modification of standard UCB algorithm in the multi-armed bandit problem, proposing an adjusted bonus term of $1/n^\tau$, where $\tau > 1/2$, that accounts for task difficulty. Our proposed algorithm, denoted as UCB$^\tau$, is substantiated through comprehensive regret and risk analyses, confirming its theoretical robustness. Comparative evaluations with standard UCB and Thompson Sampling algorithms on synthetic datasets demonstrate that UCB$^\tau$ not only outperforms in efficacy but also exhibits lower risk across various environmental conditions and hyperparameter settings.
Uncertainty-Aware Cross-Modal Transfer Network for Sketch-Based 3D Shape Retrieval
Aug 11, 2023In recent years, sketch-based 3D shape retrieval has attracted growing attention. While many previous studies have focused on cross-modal matching between hand-drawn sketches and 3D shapes, the critical issue of how to handle low-quality and noisy samples in sketch data has been largely neglected. This paper presents an uncertainty-aware cross-modal transfer network (UACTN) that addresses this issue. UACTN decouples the representation learning of sketches and 3D shapes into two separate tasks: classification-based sketch uncertainty learning and 3D shape feature transfer. We first introduce an end-to-end classification-based approach that simultaneously learns sketch features and uncertainty, allowing uncertainty to prevent overfitting noisy sketches by assigning different levels of importance to clean and noisy sketches. Then, 3D shape features are mapped into the pre-learned sketch embedding space for feature alignment. Extensive experiments and ablation studies on two benchmarks demonstrate the superiority of our proposed method compared to state-of-the-art methods.
A Comparative Study of Algorithms for Realtime Panoramic Video Blending
Dec 24, 2016
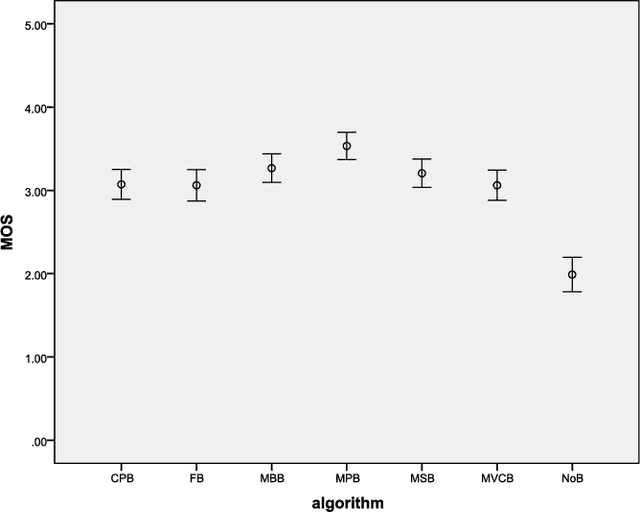


Unlike image blending algorithms, video blending algorithms have been little studied. In this paper, we investigate 6 popular blending algorithms---feather blending, multi-band blending, modified Poisson blending, mean value coordinate blending, multi-spline blending and convolution pyramid blending. We consider in particular realtime panoramic video blending, a key problem in various virtual reality tasks. To evaluate the performance of the 6 algorithms on this problem, we have created a video benchmark of several videos captured under various conditions. We analyze the time and memory needed by the above 6 algorithms, for both CPU and GPU implementations (where readily parallelizable). The visual quality provided by these algorithms is also evaluated both objectively and subjectively. The video benchmark and algorithm implementations are publicly available.