 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening with the Eyes: Benchmarking Egocentric Co-Speech Grounding across Space and Time
Mar 09, 2026In situated collaboration, speakers often use intentionally underspecified deictic commands (e.g., ``pass me \textit{that}''), whose referent becomes identifiable only by aligning speech with a brief co-speech pointing \emph{stroke}. However, many embodied benchmarks admit language-only shortcuts, allowing MLLMs to perform well without learning the \emph{audio--visual alignment} required by deictic interaction. To bridge this gap, we introduce \textbf{Egocentric Co-Speech Grounding (EcoG)}, where grounding is executable only if an agent jointly predicts \textit{What}, \textit{Where}, and \textit{When}. To operationalize this, we present \textbf{EcoG-Bench}, an evaluation-only bilingual (EN/ZH) diagnostic benchmark of \textbf{811} egocentric clips with dense spatial annotations and millisecond-level stroke supervision. It is organized under a \textbf{Progressive Cognitive Evaluation} protocol. Benchmarking state-of-the-art MLLMs reveals a severe executability gap: while human subjects achieve near-ceiling performance on EcoG-Bench (\textbf{96.9\%} strict Eco-Accuracy), the best native video-audio setting remains low (Gemini-3-Pro: \textbf{17.0\%}). Moreover, in a diagnostic ablation, replacing the native video--audio interface with timestamped frame samples and externally verified ASR (with word-level timing) substantially improves the same model (\textbf{17.0\%}$\to$\textbf{42.9\%}). Overall, EcoG-Bench provides a strict, executable testbed for event-level speech--gesture binding, and suggests that multimodal interfaces may bottleneck the observability of temporal alignment cues, independently of model reasoning.
ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response
Feb 03, 2026While passive agents merely follow instructions, proactive agents align with higher-level objectives, such as assistance and safety by continuously monitoring the environment to determine when and how to act. However, developing proactive agents is hindered by the lack of specialized resources. To address this, we introduce ProAct-75, a benchmark designed to train and evaluate proactive agents across diverse domains, including assistance, maintenance, and safety monitoring. Spanning 75 tasks, our dataset features 91,581 step-level annotations enriched with explicit task graphs. These graphs encode step dependencies and parallel execution possibilities, providing the structural grounding necessary for complex decision-making. Building on this benchmark, we propose ProAct-Helper, a reference baseline powered by a Multimodal Large Language Model (MLLM) that grounds decision-making in state detection, and leveraging task graphs to enable entropy-driven heuristic search for action selection, allowing agents to execute parallel threads independently rather than mirroring the human's next step. Extensive experiments demonstrate that ProAct-Helper outperforms strong closed-source models, improving trigger detection mF1 by 6.21%, saving 0.25 more steps in online one-step decision, and increasing the rate of parallel actions by 15.58%.
MrCoM: A Meta-Regularized World-Model Generalizing Across Multi-Scenarios
Nov 09, 2025Model-based reinforcement learning (MBRL) is a crucial approach to enhance the generalization capabilities and improve the sample efficiency of RL algorithms. However, current MBRL methods focus primarily on building world models for single tasks and rarely address generalization across different scenarios. Building on the insight that dynamics within the same simulation engine share inherent properties, we attempt to construct a unified world model capable of generalizing across different scenarios, named Meta-Regularized Contextual World-Model (MrCoM). This method first decomposes the latent state space into various components based on the dynamic characteristics, thereby enhancing the accuracy of world-model prediction. Further, MrCoM adopts meta-state regularization to extract unified representation of scenario-relevant information, and meta-value regularization to align world-model optimization with policy learning across diverse scenario objectives. We theoretically analyze the generalization error upper bound of MrCoM in multi-scenario settings. We systematically evaluate our algorithm's generalization ability across diverse scenarios, demonstrating significantly better performance than previous state-of-the-art methods.
Cross-Task Experiential Learning on LLM-based Multi-Agent Collaboration
May 29, 2025Large Language Model-based multi-agent systems (MAS) have shown remarkable progress in solving complex tasks through collaborative reasoning and inter-agent critique. However, existing approaches typically treat each task in isolation, resulting in redundant computations and limited generalization across structurally similar tasks. To address this, we introduce multi-agent cross-task experiential learning (MAEL), a novel framework that endows LLM-driven agents with explicit cross-task learning and experience accumulation. We model the task-solving workflow on a graph-structured multi-agent collaboration network, where agents propagate information and coordinate via explicit connectivity. During the experiential learning phase, we quantify the quality for each step in the task-solving workflow and store the resulting rewards along with the corresponding inputs and outputs into each agent's individual experience pool. During inference, agents retrieve high-reward, task-relevant experiences as few-shot examples to enhance the effectiveness of each reasoning step, thereby enabling more accurate and efficient multi-agent collaboration. Experimental results on diverse datasets demonstrate that MAEL empowers agents to learn from prior task experiences effectively-achieving faster convergence and producing higher-quality solutions on current tasks.
Co-Saving: Resource Aware Multi-Agent Collaboration for Software Development
May 28, 2025Recent advancements in Large Language Models (LLMs) and autonomous agents have demonstrated remarkable capabilities across various domains. However, standalone agents frequently encounter limitations when handling complex tasks that demand extensive interactions and substantial computational resources. Although Multi-Agent Systems (MAS) alleviate some of these limitations through collaborative mechanisms like task decomposition, iterative communication, and role specialization, they typically remain resource-unaware, incurring significant inefficiencies due to high token consumption and excessive execution time. To address these limitations, we propose a resource-aware multi-agent system -- Co-Saving (meaning that multiple agents collaboratively engage in resource-saving activities), which leverages experiential knowledge to enhance operational efficiency and solution quality. Our key innovation is the introduction of "shortcuts" -- instructional transitions learned from historically successful trajectories -- which allows to bypass redundant reasoning agents and expedite the collective problem-solving process. Experiments for software development tasks demonstrate significant advantages over existing methods. Specifically, compared to the state-of-the-art MAS ChatDev, our method achieves an average reduction of 50.85% in token usage, and improves the overall code quality by 10.06%.
Multi-Agent Collaboration via Evolving Orchestration
May 26, 2025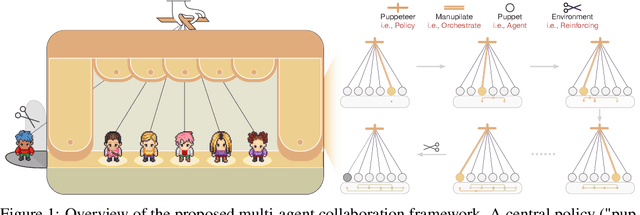
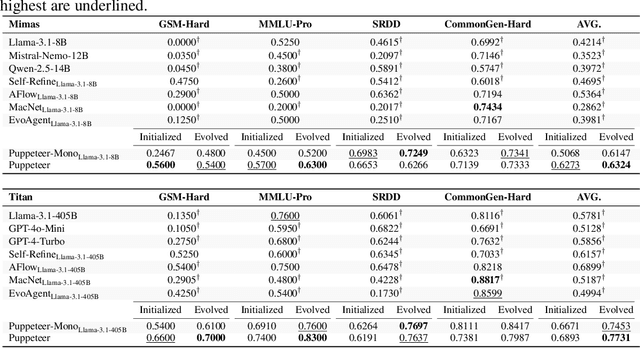
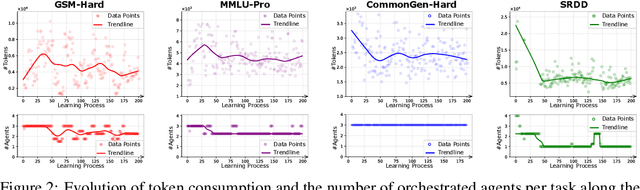
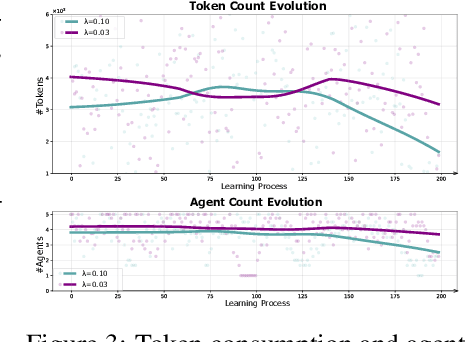
Large language models (LLMs) have achieved remarkable results across diverse downstream tasks, but their monolithic nature restricts scalability and efficiency in complex problem-solving. While recent research explores multi-agent collaboration among LLMs, most approaches rely on static organizational structures that struggle to adapt as task complexity and agent numbers grow, resulting in coordination overhead and inefficiencies. To this end, we propose a puppeteer-style paradigm for LLM-based multi-agent collaboration, where a centralized orchestrator ("puppeteer") dynamically directs agents ("puppets") in response to evolving task states. This orchestrator is trained via reinforcement learning to adaptively sequence and prioritize agents, enabling flexible and evolvable collective reasoning. Experiments on closed- and open-domain scenarios show that this method achieves superior performance with reduced computational costs. Analyses further reveal that the key improvements consistently stem from the emergence of more compact, cyclic reasoning structures under the orchestrator's evolution.
GLTW: Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion
Feb 17, 2025Knowledge Graph Completion (KGC), which aims to infer missing or incomplete facts, is a crucial task for KGs. However, integrating the vital structural information of KGs into Large Language Models (LLMs) and outputting predictions deterministically remains challenging. To address this, we propose a new method called GLTW, which encodes the structural information of KGs and merges it with LLMs to enhance KGC performance. Specifically, we introduce an improved Graph Transformer (iGT) that effectively encodes subgraphs with both local and global structural information and inherits the characteristics of language model, bypassing training from scratch. Also, we develop a subgraph-based multi-classification training objective, using all entities within KG as classification objects, to boost learning efficiency.Importantly, we combine iGT with an LLM that takes KG language prompts as input.Our extensive experiments on various KG datasets show that GLTW achieves significant performance gains compared to SOTA baselines.
GuideLight: "Industrial Solution" Guidance for More Practical Traffic Signal Control Agents
Jul 15, 2024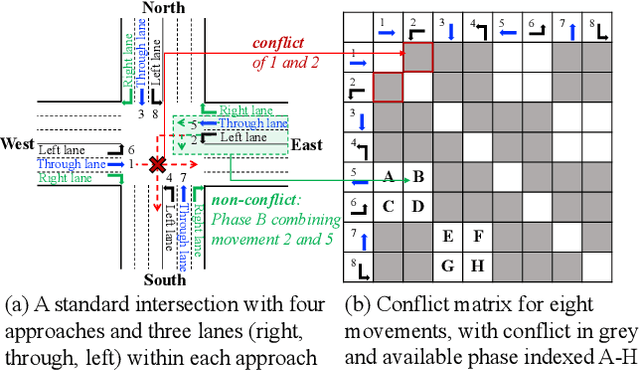
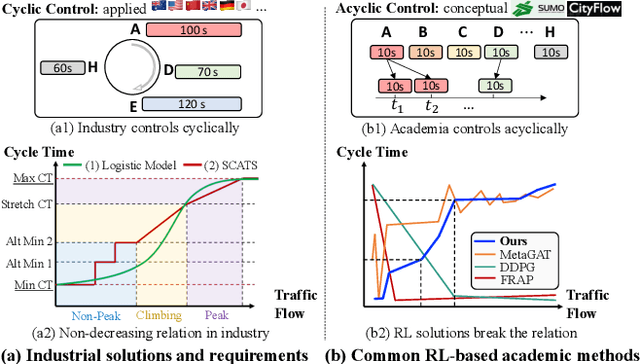
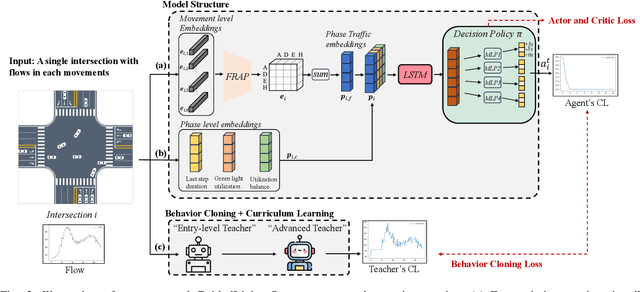
Currently, traffic signal control (TSC) methods based on reinforcement learning (RL) have proven superior to traditional methods. However, most RL methods face difficulties when applied in the real world due to three factors: input, output, and the cycle-flow relation. The industry's observable input is much more limited than simulation-based RL methods. For real-world solutions, only flow can be reliably collected, whereas common RL methods need more. For the output action, most RL methods focus on acyclic control, which real-world signal controllers do not support. Most importantly, industry standards require a consistent cycle-flow relationship: non-decreasing and different response strategies for low, medium, and high-level flows, which is ignored by the RL methods. To narrow the gap between RL methods and industry standards, we innovatively propose to use industry solutions to guide the RL agent. Specifically, we design behavior cloning and curriculum learning to guide the agent to mimic and meet industry requirements and, at the same time, leverage the power of exploration and exploitation in RL for better performance. We theoretically prove that such guidance can largely decrease the sample complexity to polynomials in the horizon when searching for an optimal policy. Our rigid experiments show that our method has good cycle-flow relation and superior performance.
CoSLight: Co-optimizing Collaborator Selection and Decision-making to Enhance Traffic Signal Control
May 27, 2024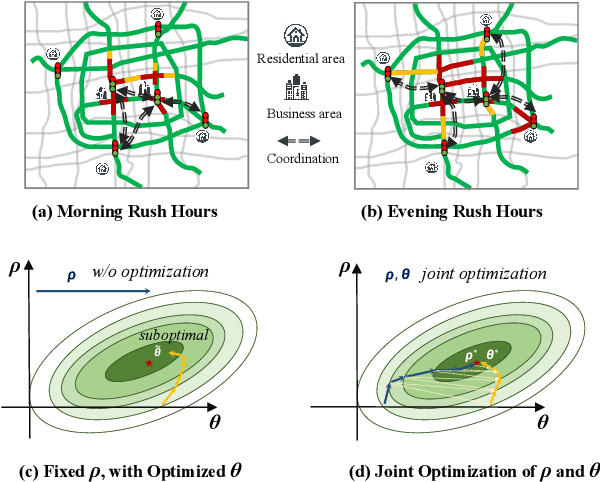

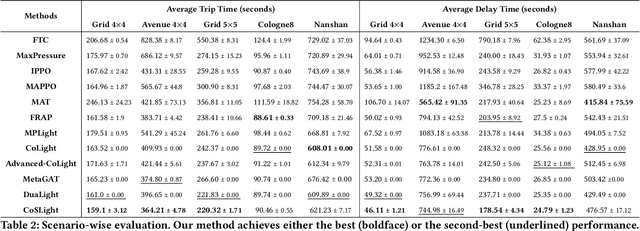
Effective multi-intersection collaboration is pivotal for reinforcement-learning-based traffic signal control to alleviate congestion. Existing work mainly chooses neighboring intersections as collaborators. However, quite an amount of congestion, even some wide-range congestion, is caused by non-neighbors failing to collaborate. To address these issues, we propose to separate the collaborator selection as a second policy to be learned, concurrently being updated with the original signal-controlling policy. Specifically, the selection policy in real-time adaptively selects the best teammates according to phase- and intersection-level features. Empirical results on both synthetic and real-world datasets provide robust validation for the superiority of our approach, offering significant improvements over existing state-of-the-art methods. The code is available at https://github.com/AnonymousAccountss/CoSLight.
X-Light: Cross-City Traffic Signal Control Using Transformer on Transformer as Meta Multi-Agent Reinforcement Learner
Apr 18, 2024



The effectiveness of traffic light control has been significantly improved by current reinforcement learning-based approaches via better cooperation among multiple traffic lights. However, a persisting issue remains: how to obtain a multi-agent traffic signal control algorithm with remarkable transferability across diverse cities? In this paper, we propose a Transformer on Transformer (TonT) model for cross-city meta multi-agent traffic signal control, named as X-Light: We input the full Markov Decision Process trajectories, and the Lower Transformer aggregates the states, actions, rewards among the target intersection and its neighbors within a city, and the Upper Transformer learns the general decision trajectories across different cities. This dual-level approach bolsters the model's robust generalization and transferability. Notably, when directly transferring to unseen scenarios, ours surpasses all baseline methods with +7.91% on average, and even +16.3% in some cases, yielding the best results.